 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving OCR Accuracy on Early Printed Books by utilizing Cross Fold Training and Voting
Paper and Code
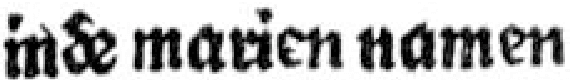
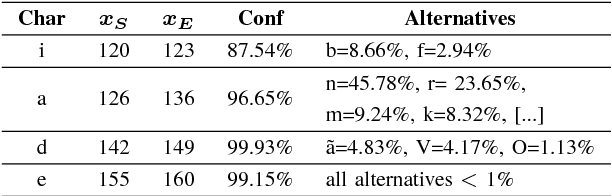
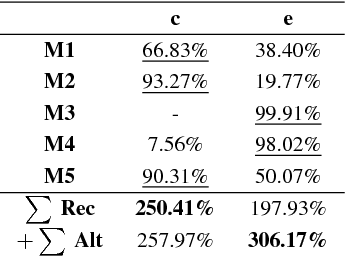
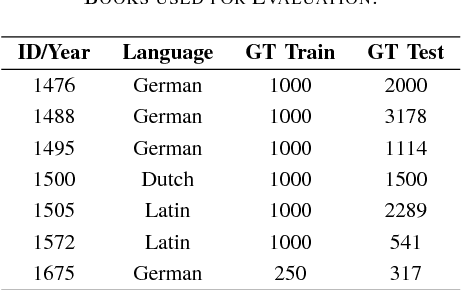
In this paper we introduce a method that significantly reduces the character error rates for OCR text obtained from OCRopus models trained on early printed books. The method uses a combination of cross fold training and confidence based voting. After allocating the available ground truth in different subsets several training processes are performed, each resulting in a specific OCR model. The OCR text generated by these models then gets voted to determine the final output by taking the recognized characters, their alternatives, and the confidence values assigned to each character into consideration. Experiments on seven early printed books show that the proposed method outperforms the standard approach considerably by reducing the amount of errors by up to 50% and more.