 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeURA*: Uncertainty-aware Path Planning using Image-based Aerial-to-Ground Traversability Estimation for Off-road Environments
Sep 15, 2023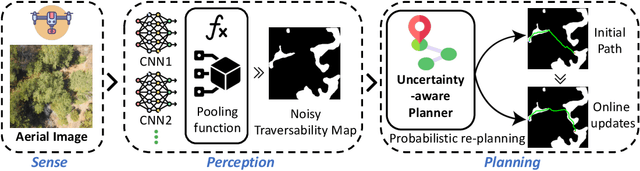
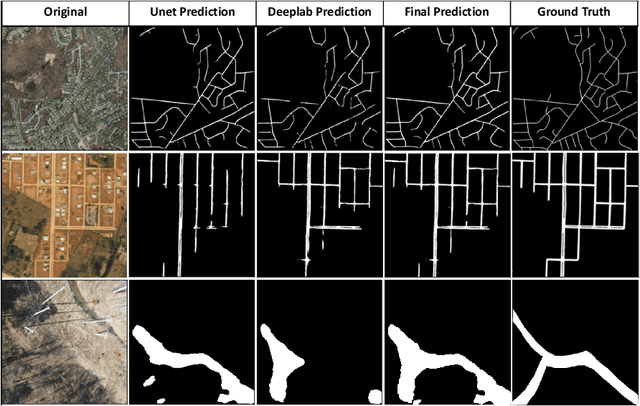
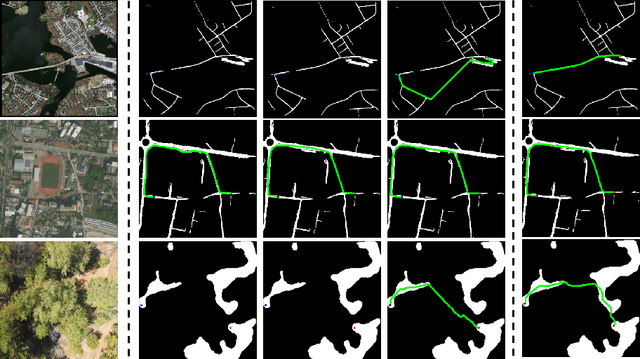
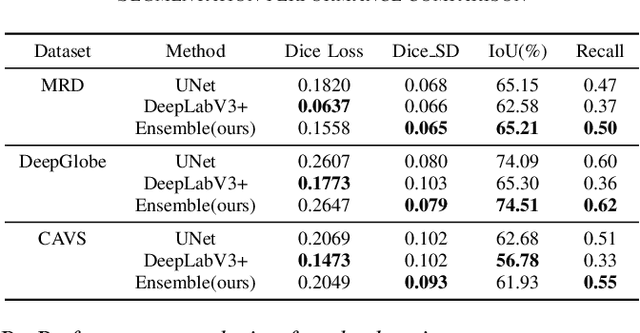
A major challenge with off-road autonomous navigation is the lack of maps or road markings that can be used to plan a path for autonomous robots. Classical path planning methods mostly assume a perfectly known environment without accounting for the inherent perception and sensing uncertainty from detecting terrain and obstacles in off-road environments. Recent work in computer vision and deep neural networks has advanced the capability of terrain traversability segmentation from raw images; however, the feasibility of using these noisy segmentation maps for navigation and path planning has not been adequately explored. To address this problem, this research proposes an uncertainty-aware path planning method, URA* using aerial images for autonomous navigation in off-road environments. An ensemble convolutional neural network (CNN) model is first used to perform pixel-level traversability estimation from aerial images of the region of interest. The traversability predictions are represented as a grid of traversal probability values. An uncertainty-aware planner is then applied to compute the best path from a start point to a goal point given these noisy traversal probability estimates. The proposed planner also incorporates replanning techniques to allow rapid replanning during online robot operation. The proposed method is evaluated on the Massachusetts Road Dataset, the DeepGlobe dataset, as well as a dataset of aerial images from off-road proving grounds at Mississippi State University. Results show that the proposed image segmentation and planning methods outperform conventional planning algorithms in terms of the quality and feasibility of the initial path, as well as the quality of replanned paths.
An Attempt towards Interpretable Audio-Visual Video Captioning
Dec 07, 2018
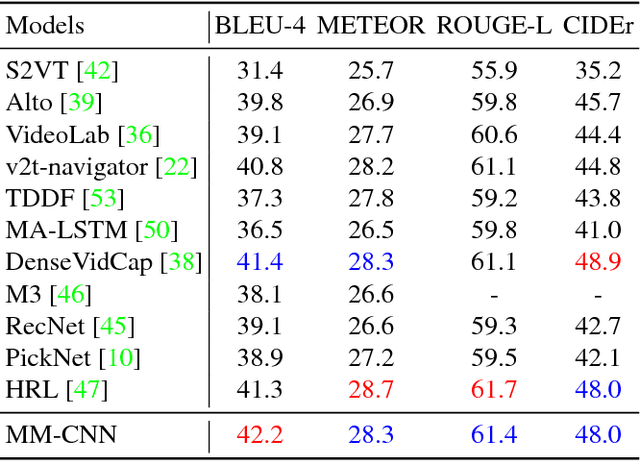
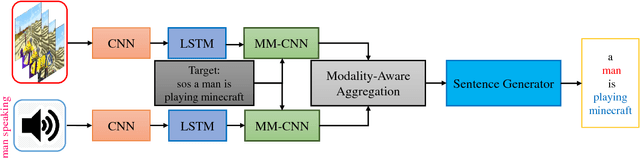
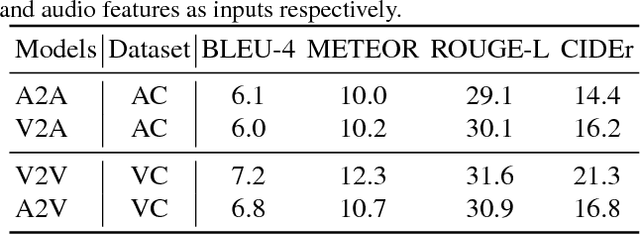
Automatically generating a natural language sentence to describe the content of an input video is a very challenging problem. It is an essential multimodal task in which auditory and visual contents are equally important. Although audio information has been exploited to improve video captioning in previous works, it is usually regarded as an additional feature fed into a black box fusion machine. How are the words in the generated sentences associated with the auditory and visual modalities? The problem is still not investigated. In this paper, we make the first attempt to design an interpretable audio-visual video captioning network to discover the association between words in sentences and audio-visual sequences. To achieve this, we propose a multimodal convolutional neural network-based audio-visual video captioning framework and introduce a modality-aware module for exploring modality selection during sentence generation. Besides, we collect new audio captioning and visual captioning datasets for further exploring the interactions between auditory and visual modalities for high-level video understanding. Extensive experiments demonstrate that the modality-aware module makes our model interpretable on modality selection during sentence generation. Even with the added interpretability, our video captioning network can still achieve comparable performance with recent state-of-the-art methods.