 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Attempt towards Interpretable Audio-Visual Video Captioning
Paper and Code
Dec 07, 2018
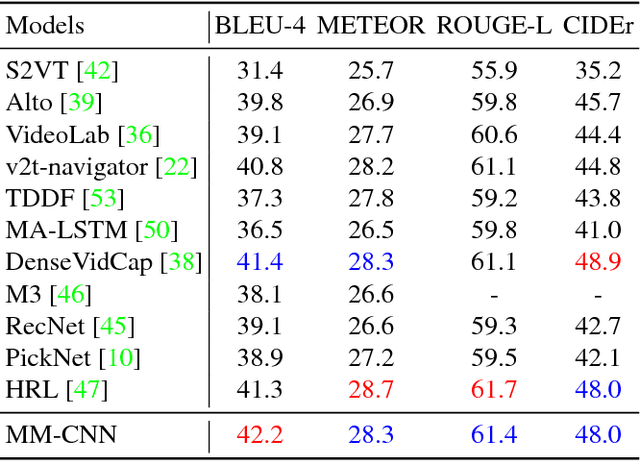
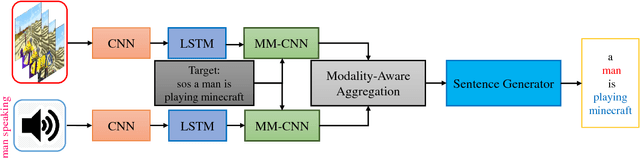
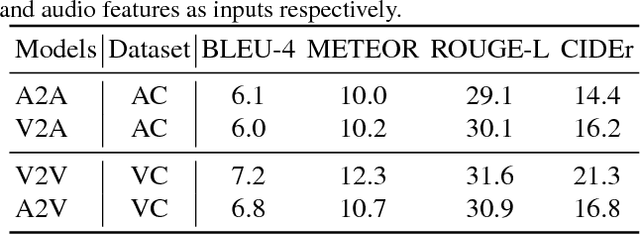
Automatically generating a natural language sentence to describe the content of an input video is a very challenging problem. It is an essential multimodal task in which auditory and visual contents are equally important. Although audio information has been exploited to improve video captioning in previous works, it is usually regarded as an additional feature fed into a black box fusion machine. How are the words in the generated sentences associated with the auditory and visual modalities? The problem is still not investigated. In this paper, we make the first attempt to design an interpretable audio-visual video captioning network to discover the association between words in sentences and audio-visual sequences. To achieve this, we propose a multimodal convolutional neural network-based audio-visual video captioning framework and introduce a modality-aware module for exploring modality selection during sentence generation. Besides, we collect new audio captioning and visual captioning datasets for further exploring the interactions between auditory and visual modalities for high-level video understanding. Extensive experiments demonstrate that the modality-aware module makes our model interpretable on modality selection during sentence generation. Even with the added interpretability, our video captioning network can still achieve comparable performance with recent state-of-the-art methods.