 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverlapNet: Loop Closing for LiDAR-based SLAM
May 24, 2021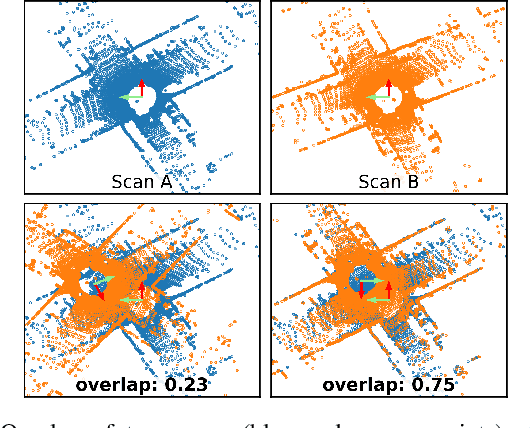
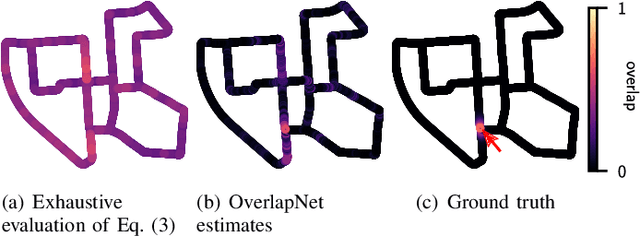

Simultaneous localization and mapping (SLAM) is a fundamental capability required by most autonomous systems. In this paper, we address the problem of loop closing for SLAM based on 3D laser scans recorded by autonomous cars. Our approach utilizes a deep neural network exploiting different cues generated from LiDAR data for finding loop closures. It estimates an image overlap generalized to range images and provides a relative yaw angle estimate between pairs of scans. Based on such predictions, we tackle loop closure detection and integrate our approach into an existing SLAM system to improve its mapping results. We evaluate our approach on sequences of the KITTI odometry benchmark and the Ford campus dataset. We show that our method can effectively detect loop closures surpassing the detection performance of state-of-the-art methods. To highlight the generalization capabilities of our approach, we evaluate our model on the Ford campus dataset while using only KITTI for training. The experiments show that the learned representation is able to provide reliable loop closure candidates, also in unseen environments.
SuMa++: Efficient LiDAR-based Semantic SLAM
May 24, 2021
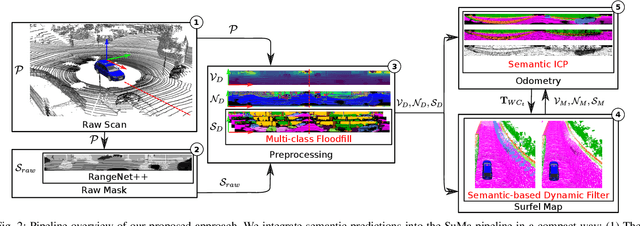


Reliable and accurate localization and mapping are key components of most autonomous systems. Besides geometric information about the mapped environment, the semantics plays an important role to enable intelligent navigation behaviors. In most realistic environments, this task is particularly complicated due to dynamics caused by moving objects, which can corrupt the mapping step or derail localization. In this paper, we propose an extension of a recently published surfel-based mapping approach exploiting three-dimensional laser range scans by integrating semantic information to facilitate the mapping process. The semantic information is efficiently extracted by a fully convolutional neural network and rendered on a spherical projection of the laser range data. This computed semantic segmentation results in point-wise labels for the whole scan, allowing us to build a semantically-enriched map with labeled surfels. This semantic map enables us to reliably filter moving objects, but also improve the projective scan matching via semantic constraints. Our experimental evaluation on challenging highways sequences from KITTI dataset with very few static structures and a large amount of moving cars shows the advantage of our semantic SLAM approach in comparison to a purely geometric, state-of-the-art approach.
A Benchmark for LiDAR-based Panoptic Segmentation based on KITTI
Mar 04, 2020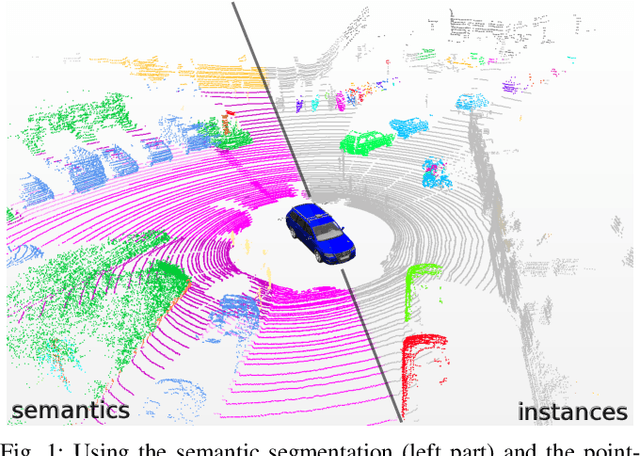
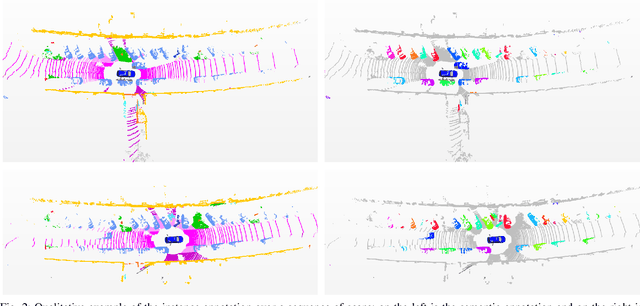

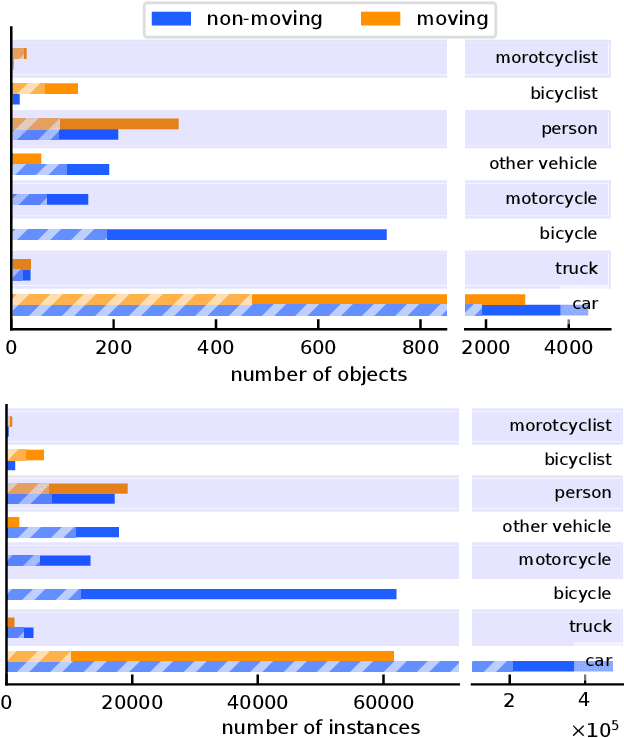
Panoptic segmentation is the recently introduced task that tackles semantic segmentation and instance segmentation jointly. In this paper, we present an extension of SemanticKITTI, which is a large-scale dataset providing dense point-wise semantic labels for all sequences of the KITTI Odometry Benchmark, for training and evaluation of laser-based panoptic segmentation. We provide the data and discuss the processing steps needed to enrich a given semantic annotation with temporally consistent instance information, i.e., instance information that supplements the semantic labels and identifies the same instance over sequences of LiDAR point clouds. Additionally, we present two strong baselines that combine state-of-the-art LiDAR-based semantic segmentation approaches with a state-of-the-art detector enriching the segmentation with instance information and that allow other researchers to compare their approaches against. We hope that our extension of SemanticKITTI with strong baselines enables the creation of novel algorithms for LiDAR-based panoptic segmentation as much as it has for the original semantic segmentation and semantic scene completion tasks. Data, code, and an online evaluation using a hidden test set will be published on http://semantic-kitti.org.
Building an Aerial-Ground Robotics System for Precision Farming
Nov 08, 2019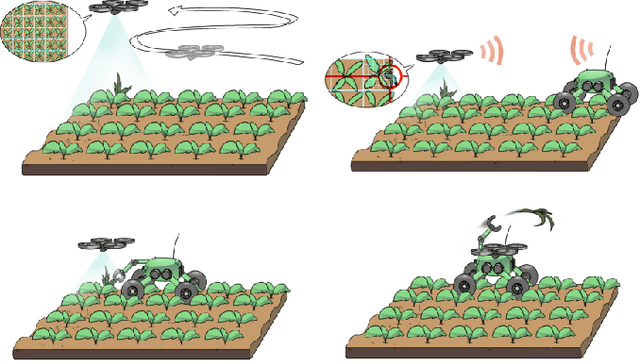

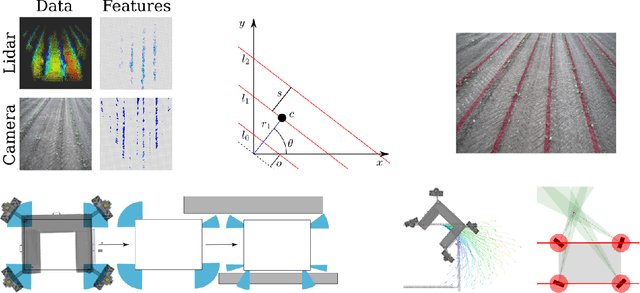
The application of autonomous robots in agriculture is gaining more and more popularity thanks to the high impact it may have on food security, sustainability, resource use efficiency, reduction of chemical treatments, minimization of the human effort and maximization of yield. The Flourish research project faced this challenge by developing an adaptable robotic solution for precision farming that combines the aerial survey capabilities of small autonomous unmanned aerial vehicles (UAVs) with flexible targeted intervention performed by multi-purpose agricultural unmanned ground vehicles (UGVs). This paper presents an exhaustive overview of the scientific and technological advances and outcomes obtained in the Flourish project. We introduce multi-spectral perception algorithms and aerial and ground based systems developed to monitor crop density, weed pressure, crop nitrogen nutrition status, and to accurately classify and locate weeds. We then introduce the navigation and mapping systems to deal with the specificity of the employed robots and of the agricultural environment, highlighting the collaborative modules that enable the UAVs and UGVs to collect and share information in a unified environment model. We finally present the ground intervention hardware, software solutions, and interfaces we implemented and tested in different field conditions and with different crops. We describe here a real use case in which a UAV collaborates with a UGV to monitor the field and to perform selective spraying treatments in a totally autonomous way.
Detection of Single Grapevine Berries in Images Using Fully Convolutional Neural Networks
May 01, 2019

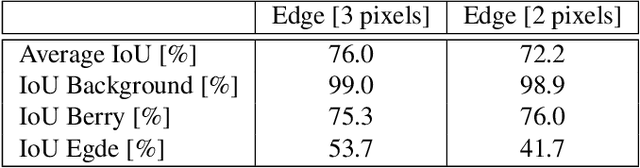
Yield estimation and forecasting are of special interest in the field of grapevine breeding and viticulture. The number of harvested berries per plant is strongly correlated with the resulting quality. Therefore, early yield forecasting can enable a focused thinning of berries to ensure a high quality end product. Traditionally yield estimation is done by extrapolating from a small sample size and by utilizing historic data. Moreover, it needs to be carried out by skilled experts with much experience in this field. Berry detection in images offers a cheap, fast and non-invasive alternative to the otherwise time-consuming and subjective on-site analysis by experts. We apply fully convolutional neural networks on images acquired with the Phenoliner, a field phenotyping platform. We count single berries in images to avoid the error-prone detection of grapevine clusters. Clusters are often overlapping and can vary a lot in the size which makes the reliable detection of them difficult. We address especially the detection of white grapes directly in the vineyard. The detection of single berries is formulated as a classification task with three classes, namely 'berry', 'edge' and 'background'. A connected component algorithm is applied to determine the number of berries in one image. We compare the automatically counted number of berries with the manually detected berries in 60 images showing Riesling plants in vertical shoot positioned trellis (VSP) and semi minimal pruned hedges (SMPH). We are able to detect berries correctly within the VSP system with an accuracy of 94.0 \% and for the SMPH system with 85.6 \%.
A Dataset for Semantic Segmentation of Point Cloud Sequences
Apr 02, 2019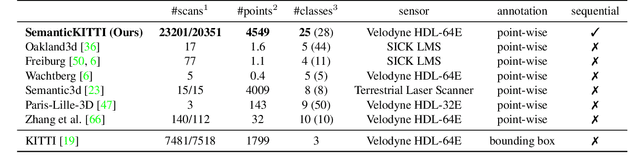

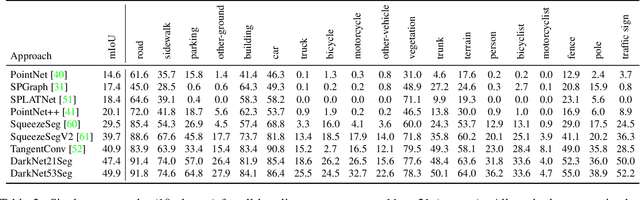

Semantic scene understanding is important for various applications. In particular, self-driving cars need a fine-grained understanding of the surfaces and objects in their vicinity. Light detection and ranging (LiDAR) provides precise geometric information about the environment and is thus a part of the sensor suites of almost all self-driving cars. Despite the relevance of semantic scene understanding for this application, there is a lack of a large dataset for this task which is based on an automotive LiDAR. In this paper, we introduce a large dataset to propel research on laser-based semantic segmentation. We annotated all sequences of the KITTI Vision Odometry Benchmark and provide dense point-wise annotations for the complete $360^{o}$ field-of-view of the employed automotive LiDAR. We propose three benchmark tasks based on this dataset: (i) semantic segmentation of point clouds using a single scan, (ii) semantic segmentation using sequences comprised of multiple past scans, and (iii) semantic scene completion, which requires to anticipate the semantic scene in the future. We provide baseline experiments and show that there is a need for more sophisticated models to efficiently tackle these tasks. Our dataset opens the door for the development of more advanced methods, but also provides plentiful data to investigate new research directions.
Bonnet: An Open-Source Training and Deployment Framework for Semantic Segmentation in Robotics using CNNs
Feb 01, 2019
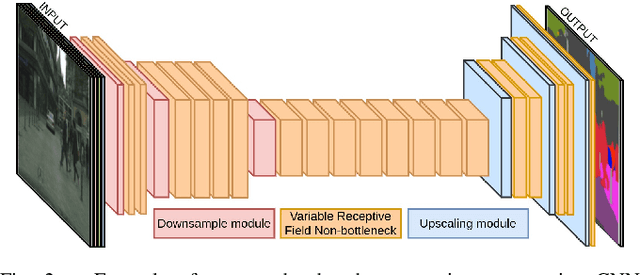
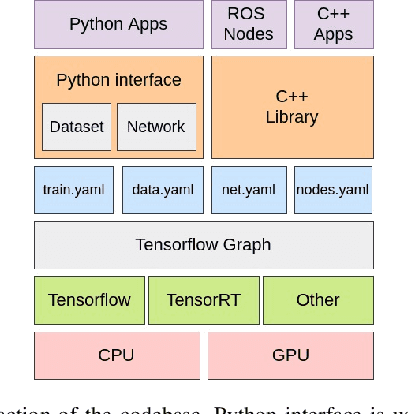

The ability to interpret a scene is an important capability for a robot that is supposed to interact with its environment. The knowledge of what is in front of the robot is, for example, relevant for navigation, manipulation, or planning. Semantic segmentation labels each pixel of an image with a class label and thus provides a detailed semantic annotation of the surroundings to the robot. Convolutional neural networks (CNNs) are popular methods for addressing this type of problem. The available software for training and the integration of CNNs for real robots, however, is quite fragmented and often difficult to use for non-experts, despite the availability of several high-quality open-source frameworks for neural network implementation and training. In this paper, we propose a tool called Bonnet, which addresses this fragmentation problem by building a higher abstraction that is specific for the semantic segmentation task. It provides a modular approach to simplify the training of a semantic segmentation CNN independently of the used dataset and the intended task. Furthermore, we also address the deployment on a real robotic platform. Thus, we do not propose a new CNN approach in this paper. Instead, we provide a stable and easy-to-use tool to make this technology more approachable in the context of autonomous systems. In this sense, we aim at closing a gap between computer vision research and its use in robotics research. We provide an open-source codebase for training and deployment. The training interface is implemented in Python using TensorFlow and the deployment interface provides a C++ library that can be easily integrated in an existing robotics codebase, a ROS node, and two standalone applications for label prediction in images and videos.
Joint Stem Detection and Crop-Weed Classification for Plant-specific Treatment in Precision Farming
Jun 09, 2018



Applying agrochemicals is the default procedure for conventional weed control in crop production, but has negative impacts on the environment. Robots have the potential to treat every plant in the field individually and thus can reduce the required use of such chemicals. To achieve that, robots need the ability to identify crops and weeds in the field and must additionally select effective treatments. While certain types of weed can be treated mechanically, other types need to be treated by (selective) spraying. In this paper, we present an approach that provides the necessary information for effective plant-specific treatment. It outputs the stem location for weeds, which allows for mechanical treatments, and the covered area of the weed for selective spraying. Our approach uses an end-to-end trainable fully convolutional network that simultaneously estimates stem positions as well as the covered area of crops and weeds. It jointly learns the class-wise stem detection and the pixel-wise semantic segmentation. Experimental evaluations on different real-world datasets show that our approach is able to reliably solve this problem. Compared to state-of-the-art approaches, our approach not only substantially improves the stem detection accuracy, i.e., distinguishing crop and weed stems, but also provides an improvement in the semantic segmentation performance.
Fully Convolutional Networks with Sequential Information for Robust Crop and Weed Detection in Precision Farming
Jun 09, 2018

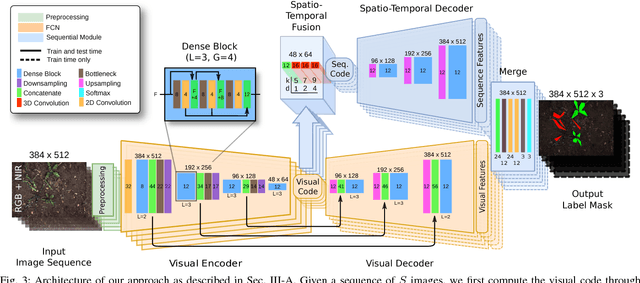

Reducing the use of agrochemicals is an important component towards sustainable agriculture. Robots that can perform targeted weed control offer the potential to contribute to this goal, for example, through specialized weeding actions such as selective spraying or mechanical weed removal. A prerequisite of such systems is a reliable and robust plant classification system that is able to distinguish crop and weed in the field. A major challenge in this context is the fact that different fields show a large variability. Thus, classification systems have to robustly cope with substantial environmental changes with respect to weed pressure and weed types, growth stages of the crop, visual appearance, and soil conditions. In this paper, we propose a novel crop-weed classification system that relies on a fully convolutional network with an encoder-decoder structure and incorporates spatial information by considering image sequences. Exploiting the crop arrangement information that is observable from the image sequences enables our system to robustly estimate a pixel-wise labeling of the images into crop and weed, i.e., a semantic segmentation. We provide a thorough experimental evaluation, which shows that our system generalizes well to previously unseen fields under varying environmental conditions --- a key capability to actually use such systems in precision framing. We provide comparisons to other state-of-the-art approaches and show that our system substantially improves the accuracy of crop-weed classification without requiring a retraining of the model.
Ocean Eddy Identification and Tracking using Neural Networks
May 15, 2018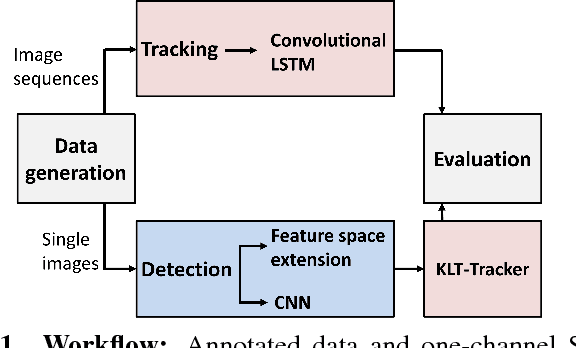



Global climate change plays an essential role in our daily life. Mesoscale ocean eddies have a significant impact on global warming, since they affect the ocean dynamics, the energy as well as the mass transports of ocean circulation. From satellite altimetry we can derive high-resolution, global maps containing ocean signals with dominating coherent eddy structures. The aim of this study is the development and evaluation of a deep-learning based approach for the analysis of eddies. In detail, we develop an eddy identification and tracking framework with two different approaches that are mainly based on feature learning with convolutional neural networks. Furthermore, state-of-the-art image processing tools and object tracking methods are used to support the eddy tracking. In contrast to previous methods, our framework is able to learn a representation of the data in which eddies can be detected and tracked in more objective and robust way. We show the detection and tracking results on sea level anomalies (SLA) data from the area of Australia and the East Australia current, and compare our two eddy detection and tracking approaches to identify the most robust and objective method.