 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrthoGAN:High-Precision Image Generation for Teeth Orthodontic Visualization
Dec 29, 2022



Patients take care of what their teeth will be like after the orthodontics. Orthodontists usually describe the expectation movement based on the original smile images, which is unconvincing. The growth of deep-learning generative models change this situation. It can visualize the outcome of orthodontic treatment and help patients foresee their future teeth and facial appearance. While previous studies mainly focus on 2D or 3D virtual treatment outcome (VTO) at a profile level, the problem of simulating treatment outcome at a frontal facial image is poorly explored. In this paper, we build an efficient and accurate system for simulating virtual teeth alignment effects in a frontal facial image. Our system takes a frontal face image of a patient with visible malpositioned teeth and the patient's 3D scanned teeth model as input, and progressively generates the visual results of the patient's teeth given the specific orthodontics planning steps from the doctor (i.e., the specification of translations and rotations of individual tooth). We design a multi-modal encoder-decoder based generative model to synthesize identity-preserving frontal facial images with aligned teeth. In addition, the original image color information is used to optimize the orthodontic outcomes, making the results more natural. We conduct extensive qualitative and clinical experiments and also a pilot study to validate our method.
AI-enabled Automatic Multimodal Fusion of Cone-Beam CT and Intraoral Scans for Intelligent 3D Tooth-Bone Reconstruction and Clinical Applications
Mar 11, 2022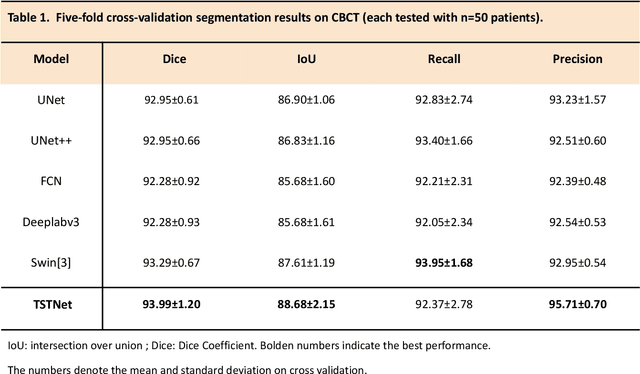
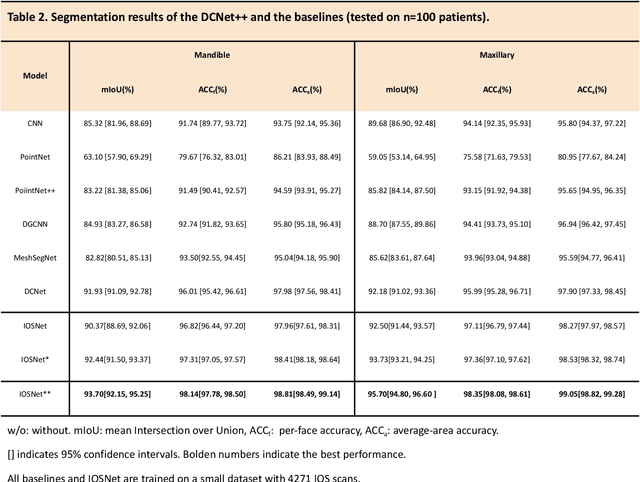

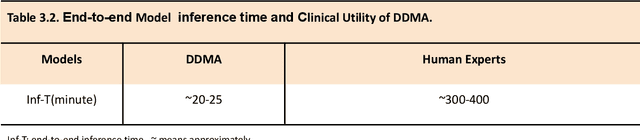
A critical step in virtual dental treatment planning is to accurately delineate all tooth-bone structures from CBCT with high fidelity and accurate anatomical information. Previous studies have established several methods for CBCT segmentation using deep learning. However, the inherent resolution discrepancy of CBCT and the loss of occlusal and dentition information largely limited its clinical applicability. Here, we present a Deep Dental Multimodal Analysis (DDMA) framework consisting of a CBCT segmentation model, an intraoral scan (IOS) segmentation model (the most accurate digital dental model), and a fusion model to generate 3D fused crown-root-bone structures with high fidelity and accurate occlusal and dentition information. Our model was trained with a large-scale dataset with 503 CBCT and 28,559 IOS meshes manually annotated by experienced human experts. For CBCT segmentation, we use a five-fold cross validation test, each with 50 CBCT, and our model achieves an average Dice coefficient and IoU of 93.99% and 88.68%, respectively, significantly outperforming the baselines. For IOS segmentations, our model achieves an mIoU of 93.07% and 95.70% on the maxillary and mandible on a test set of 200 IOS meshes, which are 1.77% and 3.52% higher than the state-of-art method. Our DDMA framework takes about 20 to 25 minutes to generate the fused 3D mesh model following the sequential processing order, compared to over 5 hours by human experts. Notably, our framework has been incorporated into a software by a clear aligner manufacturer, and real-world clinical cases demonstrate that our model can visualize crown-root-bone structures during the entire orthodontic treatment and can predict risks like dehiscence and fenestration. These findings demonstrate the potential of multi-modal deep learning to improve the quality of digital dental models and help dentists make better clinical decisions.
Vision-based Teleoperation of Shadow Dexterous Hand using End-to-End Deep Neural Network
Feb 18, 2019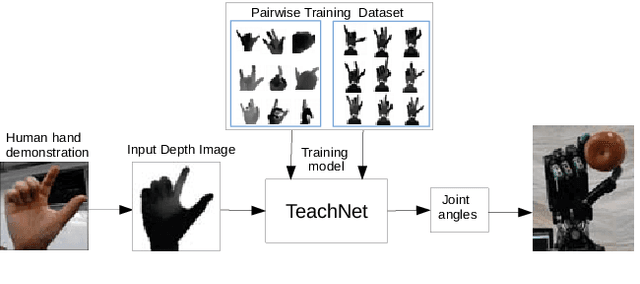
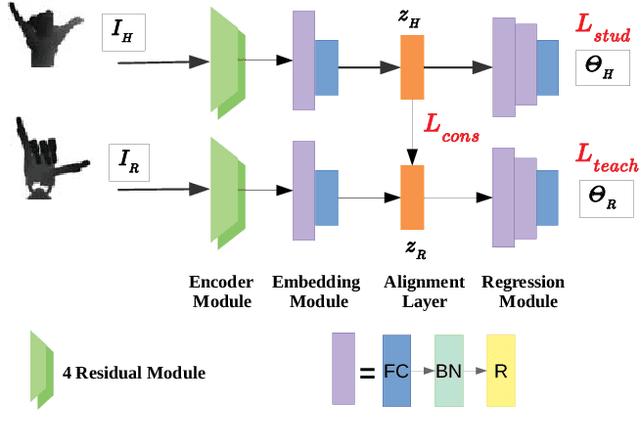
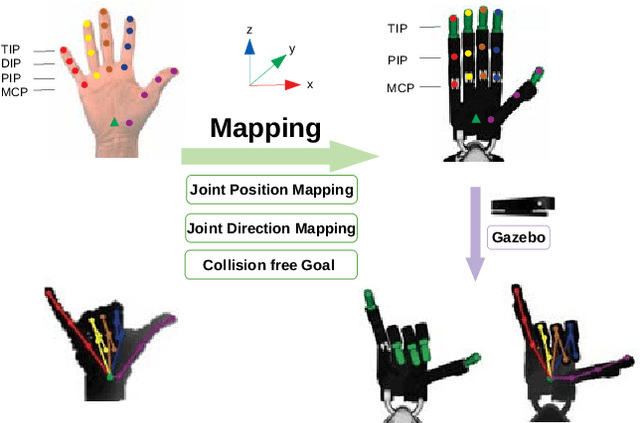

In this paper, we present TeachNet, a novel neural network architecture for intuitive and markerless vision-based teleoperation of dexterous robotic hands. Robot joint angles are directly generated from depth images of the human hand that produce visually similar robot hand poses in an end-to-end fashion. The special structure of TeachNet, combined with a consistency loss function, handles the differences in appearance and anatomy between human and robotic hands. A synchronized human-robot training set is generated from an existing dataset of labeled depth images of the human hand and simulated depth images of a robotic hand. The final training set includes 400K pairwise depth images and joint angles of a Shadow C6 robotic hand. The network evaluation results verify the superiority of TeachNet, especially regarding the high-precision condition. Imitation experiments and grasp tasks teleoperated by novice users demonstrate that TeachNet is more reliable and faster than the state-of-the-art vision-based teleoperation method.