 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-based Teleoperation of Shadow Dexterous Hand using End-to-End Deep Neural Network
Paper and Code
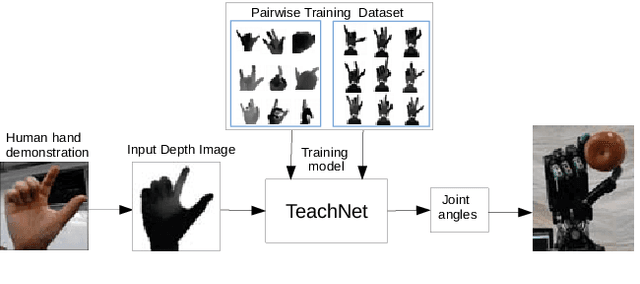
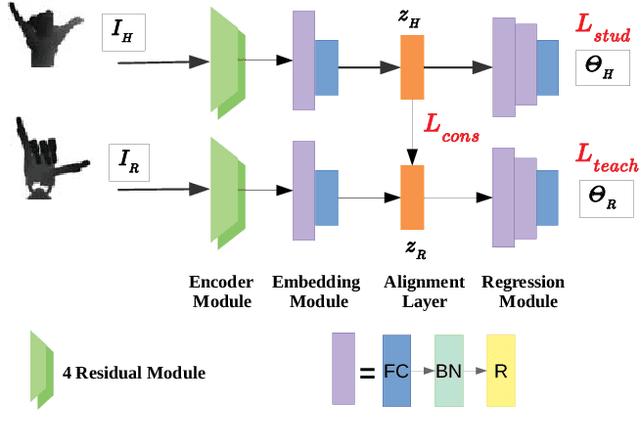
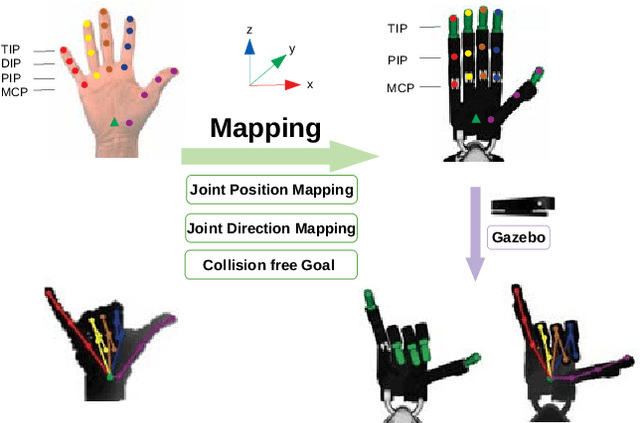

In this paper, we present TeachNet, a novel neural network architecture for intuitive and markerless vision-based teleoperation of dexterous robotic hands. Robot joint angles are directly generated from depth images of the human hand that produce visually similar robot hand poses in an end-to-end fashion. The special structure of TeachNet, combined with a consistency loss function, handles the differences in appearance and anatomy between human and robotic hands. A synchronized human-robot training set is generated from an existing dataset of labeled depth images of the human hand and simulated depth images of a robotic hand. The final training set includes 400K pairwise depth images and joint angles of a Shadow C6 robotic hand. The network evaluation results verify the superiority of TeachNet, especially regarding the high-precision condition. Imitation experiments and grasp tasks teleoperated by novice users demonstrate that TeachNet is more reliable and faster than the state-of-the-art vision-based teleoperation method.