 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEAMM: One-Shot Emotional Talking Face via Audio-Based Emotion-Aware Motion Model
Paper and Code

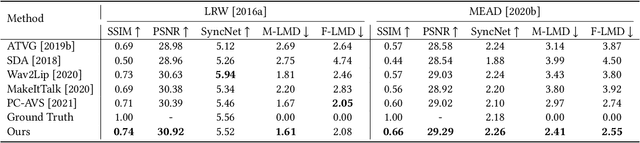
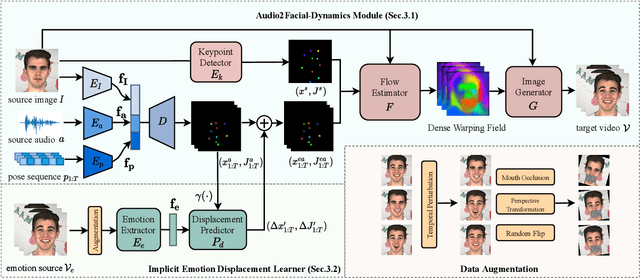

Although significant progress has been made to audio-driven talking face generation, existing methods either neglect facial emotion or cannot be applied to arbitrary subjects. In this paper, we propose the Emotion-Aware Motion Model (EAMM) to generate one-shot emotional talking faces by involving an emotion source video. Specifically, we first propose an Audio2Facial-Dynamics module, which renders talking faces from audio-driven unsupervised zero- and first-order key-points motion. Then through exploring the motion model's properties, we further propose an Implicit Emotion Displacement Learner to represent emotion-related facial dynamics as linearly additive displacements to the previously acquired motion representations. Comprehensive experiments demonstrate that by incorporating the results from both modules, our method can generate satisfactory talking face results on arbitrary subjects with realistic emotion patterns.