 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrect Code, Vulnerable Dependencies: A Large Scale Measurement Study of LLM-Specified Library Versions
May 07, 2026Large language models (LLMs) are now largely involved in software development workflows, and the code they generate routinely includes third-party library (TPL) imports annotated with specific version identifiers. These version choices can carry security and compatibility risks, yet they have not been systematically studied. We present the first large-scale measurement study of version-level risk in LLM-generated Python code, evaluating 10 LLMs on PinTrace, a curated benchmark of 1,000 Stack Overflow programming tasks. LLMs tend to specify version identifiers when directly prompted at 26.83%-95.18%, while down to 6.45%-59.19% in creating a manifest file directly. Among the specified versions, 36.70%-55.70% of tasks contain at least one known CVE, and 62.75%-74.51% of them carry Critical or High severity ratings. In 72.27%-91.37% of cases, the associated CVEs were publicly disclosed before the model's knowledge cutoff. The statistics show all models converge on the same small set of risky release versions, indicating a systemic bias rather than isolated model error. Static compatibility rates range from 19.70% to 63.20%, with installation failure as the dominant cause. The dynamic test cases confirm the pattern by 6.49%-48.62% pass rates. Further experiments confirm that these failures are attributable to version selection rather than code quality, and that externally anchored version constraints substantially reduce both vulnerability exposure and compatibility failures. Our findings reveal LLM version selection as a first-class, previously overlooked risk surface in LLM-based development. We disclosed these findings to the community of the evaluated models, and several confirmed the issue. All the code and dataset have been released for open science at https://github.com/dw763j/PinTrace.
Towards Secure Agent Skills: Architecture, Threat Taxonomy, and Security Analysis
Apr 03, 2026Agent Skills is an emerging open standard that defines a modular, filesystem-based packaging format enabling LLM-based agents to acquire domain-specific expertise on demand. Despite rapid adoption across multiple agentic platforms and the emergence of large community marketplaces, the security properties of Agent Skills have not been systematically studied. This paper presents the first comprehensive security analysis of the Agent Skills framework. We define the full lifecycle of an Agent Skill across four phases -- Creation, Distribution, Deployment, and Execution -- and identify the structural attack surface each phase introduces. Building on this lifecycle analysis, we construct a threat taxonomy comprising seven categories and seventeen scenarios organized across three attack layers, grounded in both architectural analysis and real-world evidence. We validate the taxonomy through analysis of five confirmed security incidents in the Agent Skills ecosystem. Based on these findings, we discuss defense directions for each threat category, identify open research challenges, and provide actionable recommendations for stakeholders. Our analysis reveals that the most severe threats arise from structural properties of the framework itself, including the absence of a data-instruction boundary, a single-approval persistent trust model, and the lack of mandatory marketplace security review, and cannot be addressed through incremental mitigations alone.
RefGaussian: Disentangling Reflections from 3D Gaussian Splatting for Realistic Rendering
Jun 09, 2024



3D Gaussian Splatting (3D-GS) has made a notable advancement in the field of neural rendering, 3D scene reconstruction, and novel view synthesis. Nevertheless, 3D-GS encounters the main challenge when it comes to accurately representing physical reflections, especially in the case of total reflection and semi-reflection that are commonly found in real-world scenes. This limitation causes reflections to be mistakenly treated as independent elements with physical presence, leading to imprecise reconstructions. Herein, to tackle this challenge, we propose RefGaussian to disentangle reflections from 3D-GS for realistically modeling reflections. Specifically, we propose to split a scene into transmitted and reflected components and represent these components using two Spherical Harmonics (SH). Given that this decomposition is not fully determined, we employ local regularization techniques to ensure local smoothness for both the transmitted and reflected components, thereby achieving more plausible decomposition outcomes than 3D-GS. Experimental results demonstrate that our approach achieves superior novel view synthesis and accurate depth estimation outcomes. Furthermore, it enables the utilization of scene editing applications, ensuring both high-quality results and physical coherence.
Self-supervised Learning for Pre-Training 3D Point Clouds: A Survey
May 08, 2023Point cloud data has been extensively studied due to its compact form and flexibility in representing complex 3D structures. The ability of point cloud data to accurately capture and represent intricate 3D geometry makes it an ideal choice for a wide range of applications, including computer vision, robotics, and autonomous driving, all of which require an understanding of the underlying spatial structures. Given the challenges associated with annotating large-scale point clouds, self-supervised point cloud representation learning has attracted increasing attention in recent years. This approach aims to learn generic and useful point cloud representations from unlabeled data, circumventing the need for extensive manual annotations. In this paper, we present a comprehensive survey of self-supervised point cloud representation learning using DNNs. We begin by presenting the motivation and general trends in recent research. We then briefly introduce the commonly used datasets and evaluation metrics. Following that, we delve into an extensive exploration of self-supervised point cloud representation learning methods based on these techniques. Finally, we share our thoughts on some of the challenges and potential issues that future research in self-supervised learning for pre-training 3D point clouds may encounter.
Generative Diffusion Prior for Unified Image Restoration and Enhancement
Apr 03, 2023
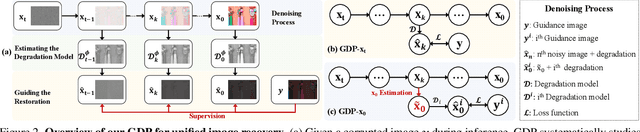
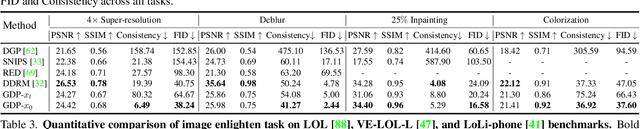

Existing image restoration methods mostly leverage the posterior distribution of natural images. However, they often assume known degradation and also require supervised training, which restricts their adaptation to complex real applications. In this work, we propose the Generative Diffusion Prior (GDP) to effectively model the posterior distributions in an unsupervised sampling manner. GDP utilizes a pre-train denoising diffusion generative model (DDPM) for solving linear inverse, non-linear, or blind problems. Specifically, GDP systematically explores a protocol of conditional guidance, which is verified more practical than the commonly used guidance way. Furthermore, GDP is strength at optimizing the parameters of degradation model during the denoising process, achieving blind image restoration. Besides, we devise hierarchical guidance and patch-based methods, enabling the GDP to generate images of arbitrary resolutions. Experimentally, we demonstrate GDP's versatility on several image datasets for linear problems, such as super-resolution, deblurring, inpainting, and colorization, as well as non-linear and blind issues, such as low-light enhancement and HDR image recovery. GDP outperforms the current leading unsupervised methods on the diverse benchmarks in reconstruction quality and perceptual quality. Moreover, GDP also generalizes well for natural images or synthesized images with arbitrary sizes from various tasks out of the distribution of the ImageNet training set.
Adversarial Attacks against Windows PE Malware Detection: A Survey of the State-of-the-Art
Dec 23, 2021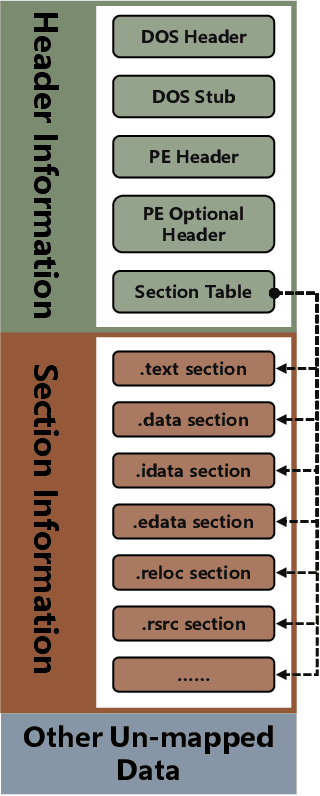
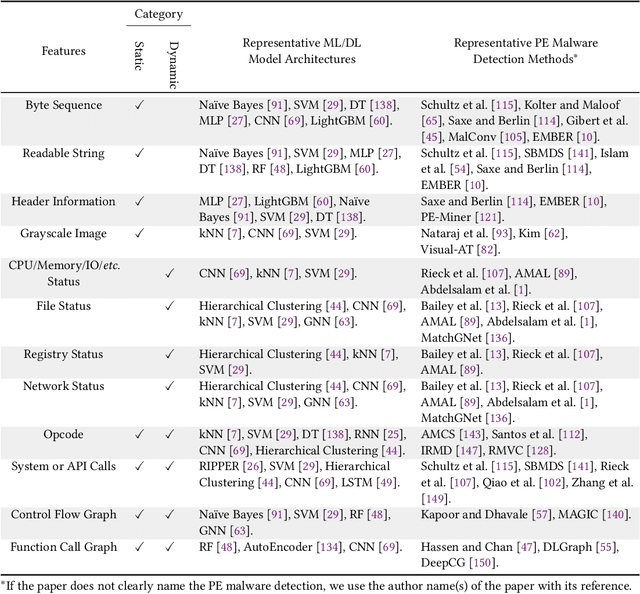
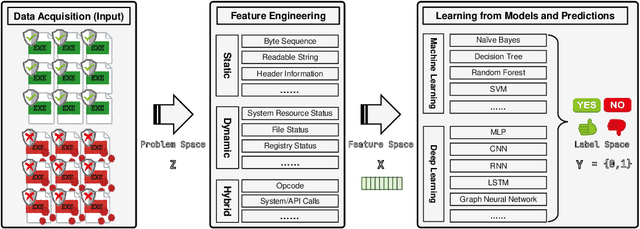
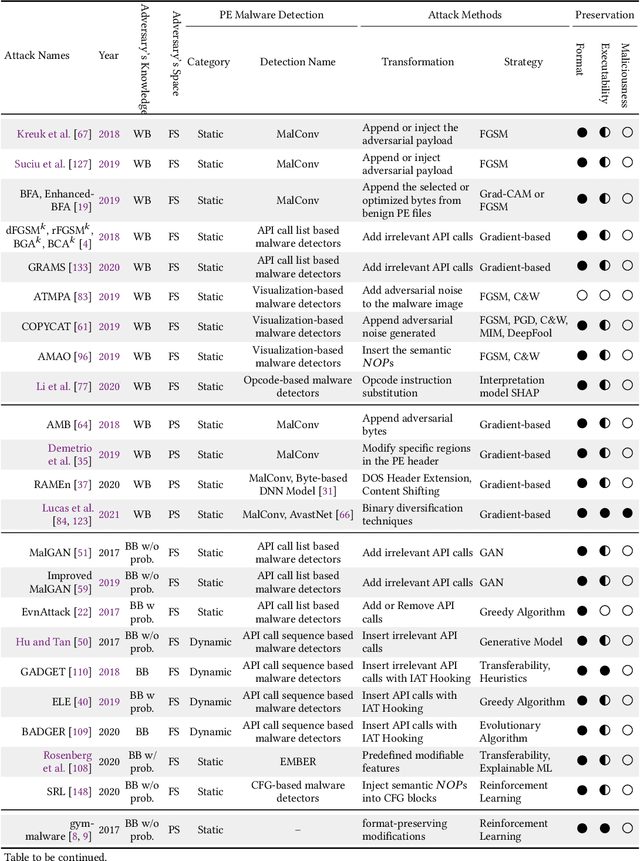
The malware has been being one of the most damaging threats to computers that span across multiple operating systems and various file formats. To defend against the ever-increasing and ever-evolving threats of malware, tremendous efforts have been made to propose a variety of malware detection methods that attempt to effectively and efficiently detect malware. Recent studies have shown that, on the one hand, existing ML and DL enable the superior detection of newly emerging and previously unseen malware. However, on the other hand, ML and DL models are inherently vulnerable to adversarial attacks in the form of adversarial examples, which are maliciously generated by slightly and carefully perturbing the legitimate inputs to confuse the targeted models. Basically, adversarial attacks are initially extensively studied in the domain of computer vision, and some quickly expanded to other domains, including NLP, speech recognition and even malware detection. In this paper, we focus on malware with the file format of portable executable (PE) in the family of Windows operating systems, namely Windows PE malware, as a representative case to study the adversarial attack methods in such adversarial settings. To be specific, we start by first outlining the general learning framework of Windows PE malware detection based on ML/DL and subsequently highlighting three unique challenges of performing adversarial attacks in the context of PE malware. We then conduct a comprehensive and systematic review to categorize the state-of-the-art adversarial attacks against PE malware detection, as well as corresponding defenses to increase the robustness of PE malware detection. We conclude the paper by first presenting other related attacks against Windows PE malware detection beyond the adversarial attacks and then shedding light on future research directions and opportunities.