 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKling-Omni Technical Report
Dec 18, 2025



We present Kling-Omni, a generalist generative framework designed to synthesize high-fidelity videos directly from multimodal visual language inputs. Adopting an end-to-end perspective, Kling-Omni bridges the functional separation among diverse video generation, editing, and intelligent reasoning tasks, integrating them into a holistic system. Unlike disjointed pipeline approaches, Kling-Omni supports a diverse range of user inputs, including text instructions, reference images, and video contexts, processing them into a unified multimodal representation to deliver cinematic-quality and highly-intelligent video content creation. To support these capabilities, we constructed a comprehensive data system that serves as the foundation for multimodal video creation. The framework is further empowered by efficient large-scale pre-training strategies and infrastructure optimizations for inference. Comprehensive evaluations reveal that Kling-Omni demonstrates exceptional capabilities in in-context generation, reasoning-based editing, and multimodal instruction following. Moving beyond a content creation tool, we believe Kling-Omni is a pivotal advancement toward multimodal world simulators capable of perceiving, reasoning, generating and interacting with the dynamic and complex worlds.
Preparing Lessons: Improve Knowledge Distillation with Better Supervision
Nov 18, 2019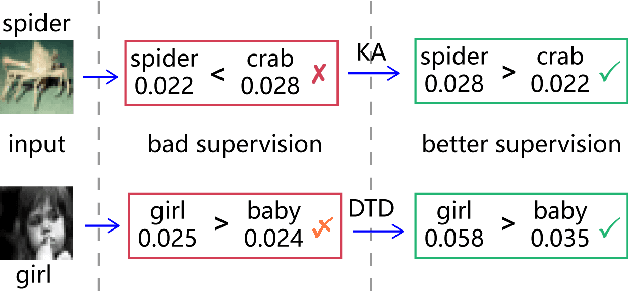


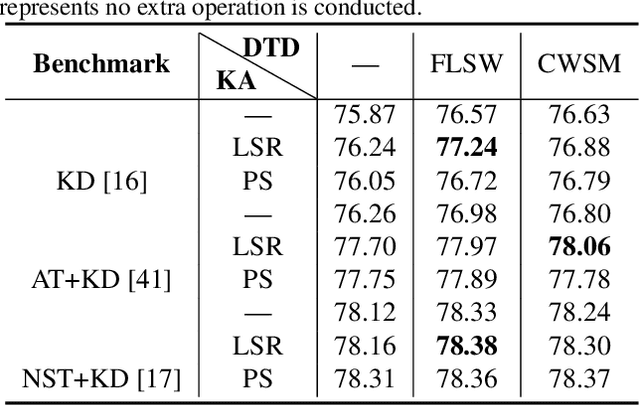
Knowledge distillation (KD) is widely used for training a compact model with the supervision of another large model, which could effectively improve the performance. Previous methods mainly focus on two aspects: 1) training the student to mimic representation space of the teacher; 2) training the model progressively or adding extra module like discriminator. Knowledge from teacher is useful, but it is still not exactly right compared with ground truth. Besides, overly uncertain supervision also influences the result. We introduce two novel approaches, Knowledge Adjustment (KA) and Dynamic Temperature Distillation (DTD), to penalize bad supervision and improve student model. Experiments on CIFAR-100, CINIC-10 and Tiny ImageNet show that our methods get encouraging performance compared with state-of-the-art methods. When combined with other KD-based methods, the performance will be further improved.