 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsyncShield: A Plug-and-Play Edge Adapter for Asynchronous Cloud-based VLA Navigation
Apr 27, 2026While Vision-Language-Action (VLA) models have been demonstrated possessing strong zero-shot generalization for robot control, their massive parameter sizes typically necessitate cloud-based deployment. However, cloud deployment introduces network jitter and inference latency, which can induce severe spatiotemporal misalignment in mobile navigation under continuous displacement, so that the stale intents expressed in past ego frames may become spatially incorrect in the current frame and lead to collisions. To address this issue, we propose AsyncShield, a plug-and-play asynchronous control framework. AsyncShield discards traditional black-box time-series prediction in favor of a deterministic physical white-box spatial mapping. By maintaining a temporal pose buffer and utilizing kinematic transformations, the system accurately converts temporal lag into spatial pose offsets to restore the VLA's original geometric intent. To balance intent restoration fidelity and physical safety, the edge adaptation is formulated as a constrained Markov decision process (CMDP). Solved via the PPO-Lagrangian algorithm, a reinforcement learning adapter dynamically trades off between tracking the VLA intent and responding to high-frequency LiDAR obstacle avoidance hard constraints. Furthermore, benefiting from a standardized universal sub-goal interface, domain randomization, and perception-level adaptation via Collision Radius Inflation, AsyncShield operates as a lightweight, plug-and-play module. Simulation and real-world experiments demonstrate that, without fine-tuning any cloud-based foundation models, the framework exhibits zero-shot and robust generalization capabilities, effectively improving the success rate and physical safety of asynchronous navigation.
Taming Momentum: Rethinking Optimizer States Through Low-Rank Approximation
Feb 27, 2026Modern optimizers like Adam and Muon are central to training large language models, but their reliance on first- and second-order momenta introduces significant memory overhead, which constrains scalability and computational efficiency. In this work, we reframe the exponential moving average (EMA) used in these momenta as the training of a linear regressor via online gradient flow. Building on this equivalence, we introduce LoRA-Pre, a novel low-rank optimizer designed for efficient pre-training. Specifically, LoRA-Pre reduces the optimizer's memory footprint by decomposing the full momentum matrix into a compact low-rank subspace within the online linear learner, thereby maintaining optimization performance while improving memory efficiency. We empirically validate LoRA-Pre's efficacy by pre-training models from the Llama architecture family, scaling from 60M to 1B parameters. LoRA-Pre achieves the highest performance across all model sizes. Notably, LoRA-Pre demonstrates remarkable rank efficiency, achieving comparable or superior results using only 1/8 the rank of baseline methods. Beyond pre-training, we evaluate LoRA-Pre's effectiveness in fine-tuning scenarios. With the same rank, LoRA-Pre consistently outperforms all efficient fine-tuning baselines. Specifically, compared to standard LoRA, LoRA-Pre achieves substantial improvements of 3.14 points on Llama-3.1-8B and 6.17 points on Llama-2-7B, validating our approach's effectiveness across both pre-training and fine-tuning paradigms. Our code is publicly available at https://github.com/mrflogs/LoRA-Pre.
ABot-N0: Technical Report on the VLA Foundation Model for Versatile Embodied Navigation
Feb 12, 2026Embodied navigation has long been fragmented by task-specific architectures. We introduce ABot-N0, a unified Vision-Language-Action (VLA) foundation model that achieves a ``Grand Unification'' across 5 core tasks: Point-Goal, Object-Goal, Instruction-Following, POI-Goal, and Person-Following. ABot-N0 utilizes a hierarchical ``Brain-Action'' architecture, pairing an LLM-based Cognitive Brain for semantic reasoning with a Flow Matching-based Action Expert for precise, continuous trajectory generation. To support large-scale learning, we developed the ABot-N0 Data Engine, curating 16.9M expert trajectories and 5.0M reasoning samples across 7,802 high-fidelity 3D scenes (10.7 $\text{km}^2$). ABot-N0 achieves new SOTA performance across 7 benchmarks, significantly outperforming specialized models. Furthermore, our Agentic Navigation System integrates a planner with hierarchical topological memory, enabling robust, long-horizon missions in dynamic real-world environments.
A Unified Study of LoRA Variants: Taxonomy, Review, Codebase, and Empirical Evaluation
Jan 30, 2026Low-Rank Adaptation (LoRA) is a fundamental parameter-efficient fine-tuning method that balances efficiency and performance in large-scale neural networks. However, the proliferation of LoRA variants has led to fragmentation in methodology, theory, code, and evaluation. To this end, this work presents the first unified study of LoRA variants, offering a systematic taxonomy, unified theoretical review, structured codebase, and standardized empirical assessment. First, we categorize LoRA variants along four principal axes: rank, optimization dynamics, initialization, and integration with Mixture-of-Experts. Then, we review their relationships and evolution within a common theoretical framework focused on low-rank update dynamics. Further, we introduce LoRAFactory, a modular codebase that implements variants through a unified interface, supporting plug-and-play experimentation and fine-grained analysis. Last, using this codebase, we conduct a large-scale evaluation across natural language generation, natural language understanding, and image classification tasks, systematically exploring key hyperparameters. Our results uncover several findings, notably: LoRA and its variants exhibit pronounced sensitivity to the choices of learning rate compared to other hyperparameters; moreover, with proper hyperparameter configurations, LoRA consistently matches or surpasses the performance of most of its variants.
Towards Compatible Fine-tuning for Vision-Language Model Updates
Dec 30, 2024



So far, efficient fine-tuning has become a popular strategy for enhancing the capabilities of foundation models on downstream tasks by learning plug-and-play modules. However, existing methods overlook a crucial issue: if the underlying foundation model is updated, are these plug-and-play modules still effective? In this paper, we first conduct a detailed analysis of various fine-tuning methods on the CLIP in terms of their compatibility with model updates. The study reveals that many high-performing fine-tuning methods fail to be compatible with the upgraded models. To address this, we propose a novel approach, Class-conditioned Context Optimization (ContCoOp), which integrates learnable prompts with class embeddings using an attention layer before inputting them into the text encoder. Consequently, the prompts can dynamically adapt to the changes in embedding space (due to model updates), ensuring continued effectiveness. Extensive experiments over 15 datasets show that our ContCoOp achieves the highest compatibility over the baseline methods, and exhibits robust out-of-distribution generalization.
LoRA-Pro: Are Low-Rank Adapters Properly Optimized?
Jul 25, 2024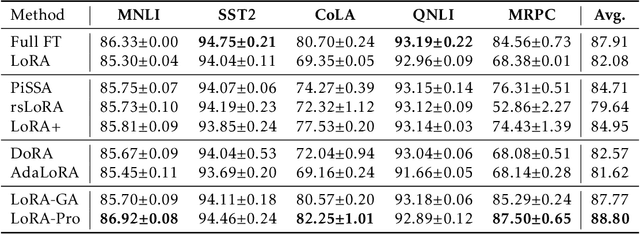
Low-Rank Adaptation, also known as LoRA, has emerged as a prominent method for parameter-efficient fine-tuning foundation models by re-parameterizing the original matrix into the product of two low-rank matrices. Despite its efficiency, LoRA often yields inferior performance compared to full fine-tuning. In this paper, we propose LoRA-Pro to bridge this performance gap. Firstly, we delve into the optimization processes in LoRA and full fine-tuning. We reveal that while LoRA employs low-rank approximation, it neglects to approximate the optimization process of full fine-tuning. To address this, we introduce a novel concept called the "equivalent gradient." This virtual gradient makes the optimization process on the re-parameterized matrix equivalent to LoRA, which can be used to quantify the differences between LoRA and full fine-tuning. The equivalent gradient is derived from the gradients of matrices $A$ and $B$. To narrow the performance gap, our approach minimizes the differences between the equivalent gradient and the gradient obtained from full fine-tuning during the optimization process. By solving this objective, we derive optimal closed-form solutions for updating matrices $A$ and $B$. Our method constrains the optimization process, shrinking the performance gap between LoRA and full fine-tuning. Extensive experiments on natural language processing tasks validate the effectiveness of our method.
A Hard-to-Beat Baseline for Training-free CLIP-based Adaptation
Feb 06, 2024



Contrastive Language-Image Pretraining (CLIP) has gained popularity for its remarkable zero-shot capacity. Recent research has focused on developing efficient fine-tuning methods, such as prompt learning and adapter, to enhance CLIP's performance in downstream tasks. However, these methods still require additional training time and computational resources, which is undesirable for devices with limited resources. In this paper, we revisit a classical algorithm, Gaussian Discriminant Analysis (GDA), and apply it to the downstream classification of CLIP. Typically, GDA assumes that features of each class follow Gaussian distributions with identical covariance. By leveraging Bayes' formula, the classifier can be expressed in terms of the class means and covariance, which can be estimated from the data without the need for training. To integrate knowledge from both visual and textual modalities, we ensemble it with the original zero-shot classifier within CLIP. Extensive results on 17 datasets validate that our method surpasses or achieves comparable results with state-of-the-art methods on few-shot classification, imbalanced learning, and out-of-distribution generalization. In addition, we extend our method to base-to-new generalization and unsupervised learning, once again demonstrating its superiority over competing approaches. Our code is publicly available at \url{https://github.com/mrflogs/ICLR24}.
Connecting the Dots: Collaborative Fine-tuning for Black-Box Vision-Language Models
Feb 06, 2024With the emergence of pretrained vision-language models (VLMs), considerable efforts have been devoted to fine-tuning them for downstream tasks. Despite the progress made in designing efficient fine-tuning methods, such methods require access to the model's parameters, which can be challenging as model owners often opt to provide their models as a black box to safeguard model ownership. This paper proposes a \textbf{C}ollabo\textbf{ra}tive \textbf{F}ine-\textbf{T}uning (\textbf{CraFT}) approach for fine-tuning black-box VLMs to downstream tasks, where one only has access to the input prompts and the output predictions of the model. CraFT comprises two modules, a prompt generation module for learning text prompts and a prediction refinement module for enhancing output predictions in residual style. Additionally, we introduce an auxiliary prediction-consistent loss to promote consistent optimization across these modules. These modules are optimized by a novel collaborative training algorithm. Extensive experiments on few-shot classification over 15 datasets demonstrate the superiority of CraFT. The results show that CraFT achieves a decent gain of about 12\% with 16-shot datasets and only 8,000 queries. Moreover, CraFT trains faster and uses only about 1/80 of the memory footprint for deployment, while sacrificing only 1.62\% compared to the white-box method.
Self-training solutions for the ICCV 2023 GeoNet Challenge
Nov 28, 2023


GeoNet is a recently proposed domain adaptation benchmark consisting of three challenges (i.e., GeoUniDA, GeoImNet, and GeoPlaces). Each challenge contains images collected from the USA and Asia where there are huge geographical gaps. Our solution adopts a two-stage source-free domain adaptation framework with a Swin Transformer backbone to achieve knowledge transfer from the USA (source) domain to Asia (target) domain. In the first stage, we train a source model using labeled source data with a re-sampling strategy and two types of cross-entropy loss. In the second stage, we generate pseudo labels for unlabeled target data to fine-tune the model. Our method achieves an H-score of 74.56% and ultimately ranks 1st in the GeoUniDA challenge. In GeoImNet and GeoPlaces challenges, our solution also reaches a top-3 accuracy of 64.46% and 51.23%, respectively.
Towards Realistic Unsupervised Fine-tuning with CLIP
Aug 24, 2023



The emergence of vision-language models (VLMs), such as CLIP, has spurred a significant research effort towards their application for downstream supervised learning tasks. Although some previous studies have explored the unsupervised fine-tuning of CLIP, they often rely on prior knowledge in the form of class names associated with ground truth labels. In this paper, we delve into a realistic unsupervised fine-tuning scenario by assuming that the unlabeled data might contain out-of-distribution samples from unknown classes. Furthermore, we emphasize the importance of simultaneously enhancing out-of-distribution detection capabilities alongside the recognition of instances associated with predefined class labels. To tackle this problem, we present a simple, efficient, and effective fine-tuning approach called Universal Entropy Optimization (UEO). UEO leverages sample-level confidence to approximately minimize the conditional entropy of confident instances and maximize the marginal entropy of less confident instances. Apart from optimizing the textual prompts, UEO also incorporates optimization of channel-wise affine transformations within the visual branch of CLIP. Through extensive experiments conducted across 15 domains and 4 different types of prior knowledge, we demonstrate that UEO surpasses baseline methods in terms of both generalization and out-of-distribution detection.