 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges in Variable Importance Ranking Under Correlation
Feb 05, 2024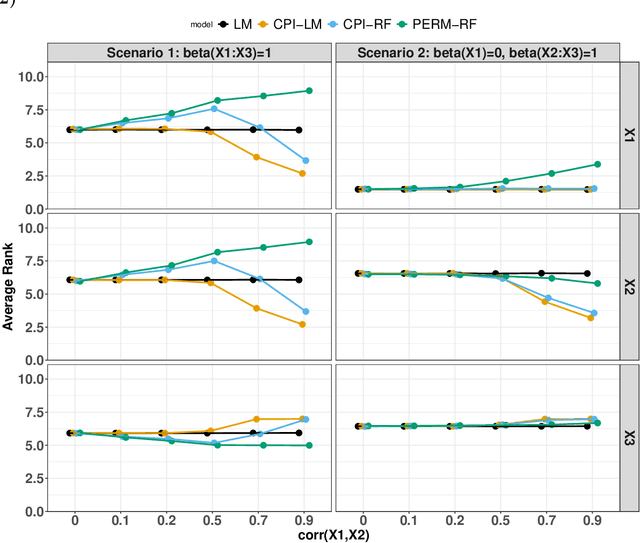
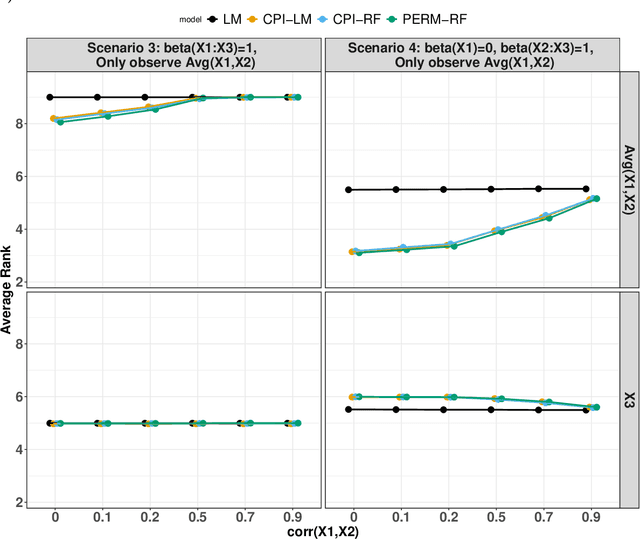
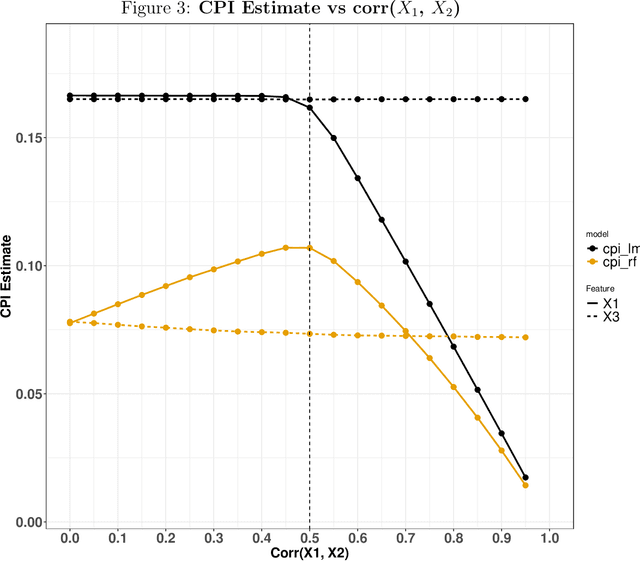
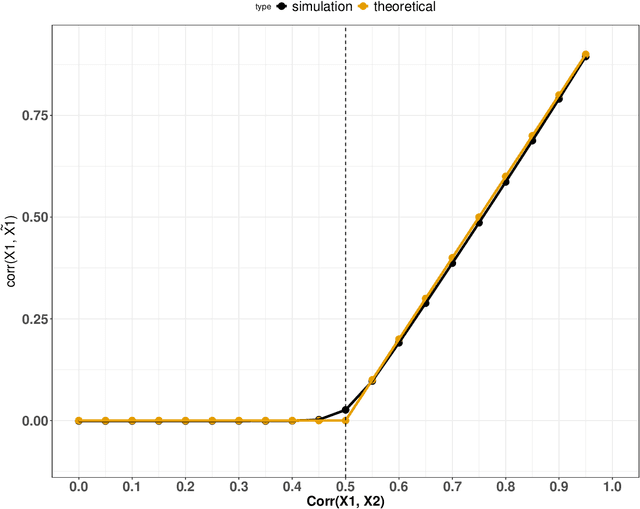
Variable importance plays a pivotal role in interpretable machine learning as it helps measure the impact of factors on the output of the prediction model. Model agnostic methods based on the generation of "null" features via permutation (or related approaches) can be applied. Such analysis is often utilized in pharmaceutical applications due to its ability to interpret black-box models, including tree-based ensembles. A major challenge and significant confounder in variable importance estimation however is the presence of between-feature correlation. Recently, several adjustments to marginal permutation utilizing feature knockoffs were proposed to address this issue, such as the variable importance measure known as conditional predictive impact (CPI). Assessment and evaluation of such approaches is the focus of our work. We first present a comprehensive simulation study investigating the impact of feature correlation on the assessment of variable importance. We then theoretically prove the limitation that highly correlated features pose for the CPI through the knockoff construction. While we expect that there is always no correlation between knockoff variables and its corresponding predictor variables, we prove that the correlation increases linearly beyond a certain correlation threshold between the predictor variables. Our findings emphasize the absence of free lunch when dealing with high feature correlation, as well as the necessity of understanding the utility and limitations behind methods in variable importance estimation.
Development and Evaluation of Conformal Prediction Methods for QSAR
Apr 03, 2023


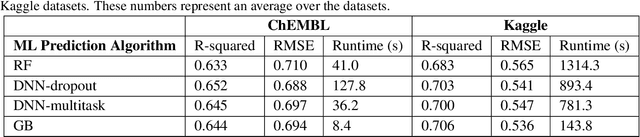
The quantitative structure-activity relationship (QSAR) regression model is a commonly used technique for predicting biological activities of compounds using their molecular descriptors. Predictions from QSAR models can help, for example, to optimize molecular structure; prioritize compounds for further experimental testing; and estimate their toxicity. In addition to the accurate estimation of the activity, it is highly desirable to obtain some estimate of the uncertainty associated with the prediction, e.g., calculate a prediction interval (PI) containing the true molecular activity with a pre-specified probability, say 70%, 90% or 95%. The challenge is that most machine learning (ML) algorithms that achieve superior predictive performance require some add-on methods for estimating uncertainty of their prediction. The development of these algorithms is an active area of research by statistical and ML communities but their implementation for QSAR modeling remains limited. Conformal prediction (CP) is a promising approach. It is agnostic to the prediction algorithm and can produce valid prediction intervals under some weak assumptions on the data distribution. We proposed computationally efficient CP algorithms tailored to the most advanced ML models, including Deep Neural Networks and Gradient Boosting Machines. The validity and efficiency of proposed conformal predictors are demonstrated on a diverse collection of QSAR datasets as well as simulation studies.
Light Gradient Boosting Machine as a Regression Method for Quantitative Structure-Activity Relationships
Apr 28, 2021
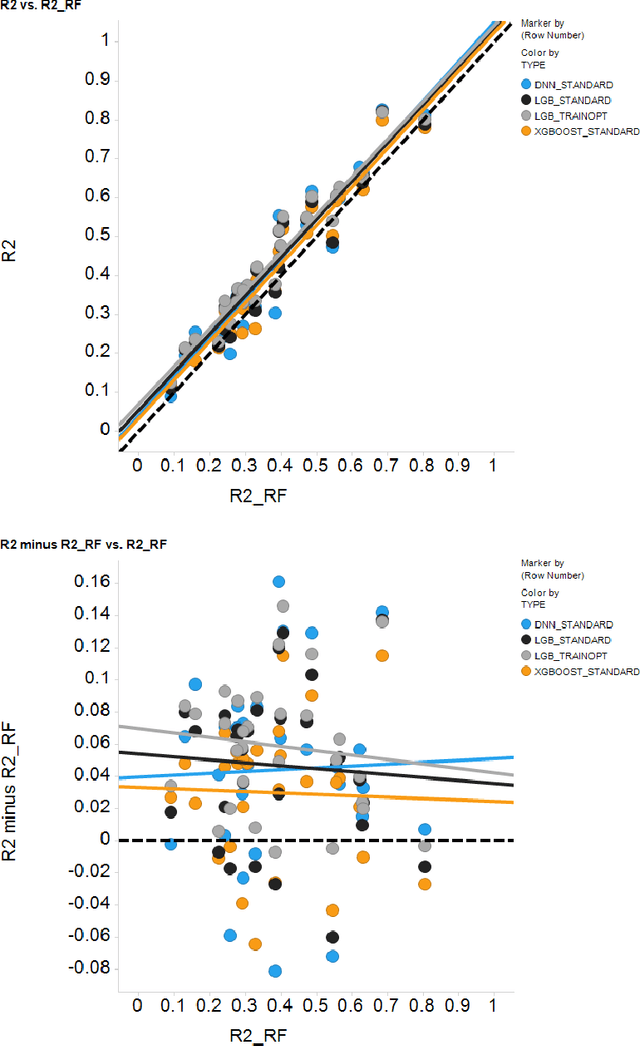

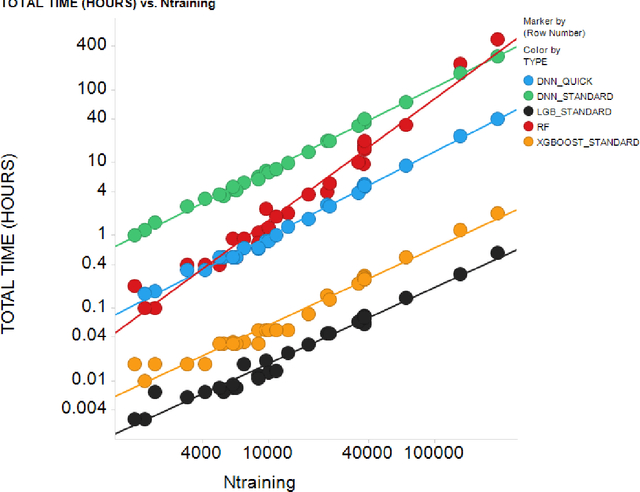
In the pharmaceutical industry, where it is common to generate many QSAR models with large numbers of molecules and descriptors, the best QSAR methods are those that can generate the most accurate predictions but that are also insensitive to hyperparameters and are computationally efficient. Here we compare Light Gradient Boosting Machine (LightGBM) to random forest, single-task deep neural nets, and Extreme Gradient Boosting (XGBoost) on 30 in-house data sets. While any boosting algorithm has many adjustable hyperparameters, we can define a set of standard hyperparameters at which LightGBM makes predictions about as accurate as single-task deep neural nets, but is a factor of 1000-fold faster than random forest and ~4-fold faster than XGBoost in terms of total computational time for the largest models. Another very useful feature of LightGBM is that it includes a native method for estimating prediction intervals.