 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Gap Between Prototypes and Images in Cross-domain Finetuning
Oct 16, 2024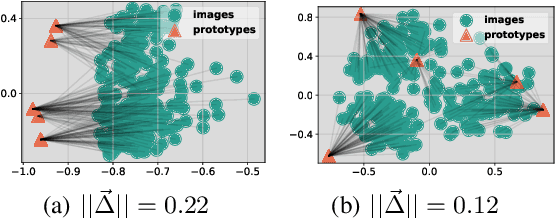
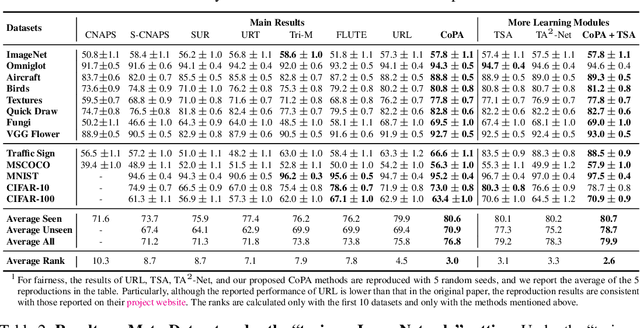
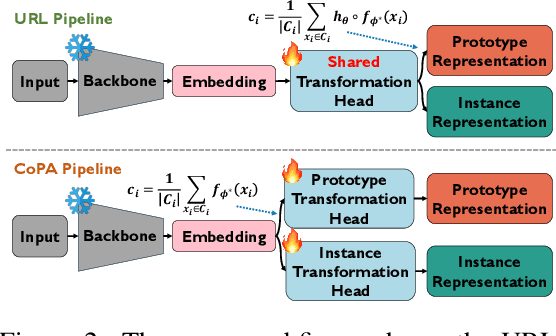
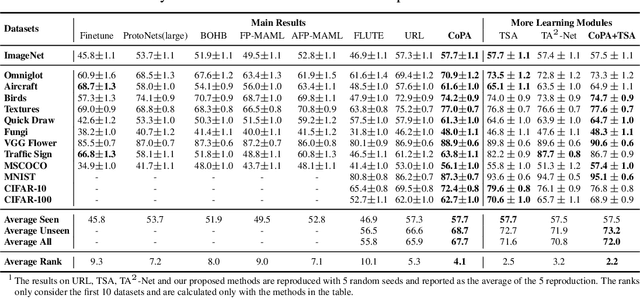
In cross-domain few-shot classification (CFC), recent works mainly focus on adapting a simple transformation head on top of a frozen pre-trained backbone with few labeled data to project embeddings into a task-specific metric space where classification can be performed by measuring similarities between image instance and prototype representations. Technically, an assumption implicitly adopted in such a framework is that the prototype and image instance embeddings share the same representation transformation. However, in this paper, we find that there naturally exists a gap, which resembles the modality gap, between the prototype and image instance embeddings extracted from the frozen pre-trained backbone, and simply applying the same transformation during the adaptation phase constrains exploring the optimal representations and shrinks the gap between prototype and image representations. To solve this problem, we propose a simple yet effective method, contrastive prototype-image adaptation (CoPA), to adapt different transformations respectively for prototypes and images similarly to CLIP by treating prototypes as text prompts. Extensive experiments on Meta-Dataset demonstrate that CoPA achieves the state-of-the-art performance more efficiently. Meanwhile, further analyses also indicate that CoPA can learn better representation clusters, enlarge the gap, and achieve minimal validation loss at the enlarged gap.
MOKD: Cross-domain Finetuning for Few-shot Classification via Maximizing Optimized Kernel Dependence
May 29, 2024



In cross-domain few-shot classification, \emph{nearest centroid classifier} (NCC) aims to learn representations to construct a metric space where few-shot classification can be performed by measuring the similarities between samples and the prototype of each class. An intuition behind NCC is that each sample is pulled closer to the class centroid it belongs to while pushed away from those of other classes. However, in this paper, we find that there exist high similarities between NCC-learned representations of two samples from different classes. In order to address this problem, we propose a bi-level optimization framework, \emph{maximizing optimized kernel dependence} (MOKD) to learn a set of class-specific representations that match the cluster structures indicated by labeled data of the given task. Specifically, MOKD first optimizes the kernel adopted in \emph{Hilbert-Schmidt independence criterion} (HSIC) to obtain the optimized kernel HSIC (opt-HSIC) that can capture the dependence more precisely. Then, an optimization problem regarding the opt-HSIC is addressed to simultaneously maximize the dependence between representations and labels and minimize the dependence among all samples. Extensive experiments on Meta-Dataset demonstrate that MOKD can not only achieve better generalization performance on unseen domains in most cases but also learn better data representation clusters. The project repository of MOKD is available at: \href{https://github.com/tmlr-group/MOKD}{https://github.com/tmlr-group/MOKD}.
Meta-Learning with Network Pruning
Jul 07, 2020



Meta-learning is a powerful paradigm for few-shot learning. Although with remarkable success witnessed in many applications, the existing optimization based meta-learning models with over-parameterized neural networks have been evidenced to ovetfit on training tasks. To remedy this deficiency, we propose a network pruning based meta-learning approach for overfitting reduction via explicitly controlling the capacity of network. A uniform concentration analysis reveals the benefit of network capacity constraint for reducing generalization gap of the proposed meta-learner. We have implemented our approach on top of Reptile assembled with two network pruning routines: Dense-Sparse-Dense (DSD) and Iterative Hard Thresholding (IHT). Extensive experimental results on benchmark datasets with different over-parameterized deep networks demonstrate that our method not only effectively alleviates meta-overfitting but also in many cases improves the overall generalization performance when applied to few-shot classification tasks.