 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoal-Oriented Framework for Optical Flow-based Multi-User Multi-Task Video Transmission
Mar 20, 2026Efficient multi-user multi-task video transmission is an important research topic within the realm of current wireless communication systems. To reduce the transmission burden and save communication resources, we propose a goal-oriented semantic communication framework for optical flow-based multi-user multi-task video transmission (OF-GSC). At the transmitter, we design a semantic encoder that consists of a motion extractor and a patch-level optical flow-based semantic representation extractor to effectively identify and select important semantic representations. At the receiver, we design a transformer-based semantic decoder for high-quality video reconstruction and video classification tasks. To minimize the communication time, we develop a deep deterministic policy gradient (DDPG)-based bandwidth allocation algorithm for multi-user transmission. For video reconstruction tasks, our OF-GSC framework achieves a significant improvement in the received video quality, as evidenced by a 13.47% increase in the structural similarity index measure (SSIM) score in comparison to DeepJSCC. For video classification tasks, OF-GSC achieves a Top-1 accuracy slightly surpassing the performance of VideoMAE with only 25% required data under the same mask ratio of 0.3. For bandwidth allocation optimization, our DDPG-based algorithm reduces the maximum transmission time by 25.97% compared with the baseline equal-bandwidth allocation scheme.
Safety-guaranteed and Goal-oriented Semantic Sensing, Communication, and Control for Robotics
Mar 13, 2026Wirelessly-connected robotic system empowers robots with real-time intelligence by leveraging remote computing resources for decision-making. However, the data exchange between robots and base stations often overwhelms communication links, introducing latency that undermines real-time response. To tackle this, goal-oriented semantic communication (GSC) has been introduced into wirelessly-connected robotic systems to extract and transmit only goal-relevant semantic representations, enhancing communication efficiency and task effectiveness. However, existing GSC approaches focused primarily on optimizing effectiveness metrics while overlooking safety requirements, which should be treated as the top priority in real-world robotic systems. To bridge this gap, we propose safety-guaranteed and goal-oriented semantic communication for wirelessly-connected robotic system, aiming to maximize the robotic task effectiveness subject to practical operational safety requirements. We first summarize the general safety requirements and effectiveness metrics across typical robotic tasks, including robot arm grasping, unmanned aerial vehicle (UAV)-assisted tasks, and multi-robot exploration. We then systematically analyze the unique safety and effectiveness challenges faced by wirelessly-connected robotic system in sensing, communication, and control. Based on these, we further present potential safety-guaranteed and goal-oriented sensing, communication, and control solutions. Finally, a UAV target tracking case study validates that our proposed GSC solutions can significantly improve safety rate and tracking success rate by more than 2 times and 4.5 times, respectively.
Goal-oriented Communication for Fast and Robust Robotic Fault Detection and Recovery
Jan 26, 2026Autonomous robotic systems are widely deployed in smart factories and operate in dynamic, uncertain, and human-involved environments that require low-latency and robust fault detection and recovery (FDR). However, existing FDR frameworks exhibit various limitations, such as significant delays in communication and computation, and unreliability in robot motion/trajectory generation, mainly because the communication-computation-control (3C) loop is designed without considering the downstream FDR goal. To address this, we propose a novel Goal-oriented Communication (GoC) framework that jointly designs the 3C loop tailored for fast and robust robotic FDR, with the goal of minimising the FDR time while maximising the robotic task (e.g., workpiece sorting) success rate. For fault detection, our GoC framework innovatively defines and extracts the 3D scene graph (3D-SG) as the semantic representation via our designed representation extractor, and detects faults by monitoring spatial relationship changes in the 3D-SG. For fault recovery, we fine-tune a small language model (SLM) via Low-Rank Adaptation (LoRA) and enhance its reasoning and generalization capabilities via knowledge distillation to generate recovery motions for robots. We also design a lightweight goal-oriented digital twin reconstruction module to refine the recovery motions generated by the SLM when fine-grained robotic control is required, using only task-relevant object contours for digital twin reconstruction. Extensive simulations demonstrate that our GoC framework reduces the FDR time by up to 82.6% and improves the task success rate by up to 76%, compared to the state-of-the-art frameworks that rely on vision language models for fault detection and large language models for fault recovery.
FedMerge: Federated Personalization via Model Merging
Apr 09, 2025One global model in federated learning (FL) might not be sufficient to serve many clients with non-IID tasks and distributions. While there has been advances in FL to train multiple global models for better personalization, they only provide limited choices to clients so local finetuning is still indispensable. In this paper, we propose a novel ``FedMerge'' approach that can create a personalized model per client by simply merging multiple global models with automatically optimized and customized weights. In FedMerge, a few global models can serve many non-IID clients, even without further local finetuning. We formulate this problem as a joint optimization of global models and the merging weights for each client. Unlike existing FL approaches where the server broadcasts one or multiple global models to all clients, the server only needs to send a customized, merged model to each client. Moreover, instead of periodically interrupting the local training and re-initializing it to a global model, the merged model aligns better with each client's task and data distribution, smoothening the local-global gap between consecutive rounds caused by client drift. We evaluate FedMerge on three different non-IID settings applied to different domains with diverse tasks and data types, in which FedMerge consistently outperforms existing FL approaches, including clustering-based and mixture-of-experts (MoE) based methods.
Estimating Individual Dose-Response Curves under Unobserved Confounders from Observational Data
Oct 21, 2024



Estimating an individual's potential response to continuously varied treatments is crucial for addressing causal questions across diverse domains, from healthcare to social sciences. However, existing methods are limited either to estimating causal effects of binary treatments, or scenarios where all confounding variables are measurable. In this work, we present ContiVAE, a novel framework for estimating causal effects of continuous treatments, measured by individual dose-response curves, considering the presence of unobserved confounders using observational data. Leveraging a variational auto-encoder with a Tilted Gaussian prior distribution, ContiVAE models the hidden confounders as latent variables, and is able to predict the potential outcome of any treatment level for each individual while effectively capture the heterogeneity among individuals. Experiments on semi-synthetic datasets show that ContiVAE outperforms existing methods by up to 62%, demonstrating its robustness and flexibility. Application on a real-world dataset illustrates its practical utility.
Multi-Level Additive Modeling for Structured Non-IID Federated Learning
May 26, 2024
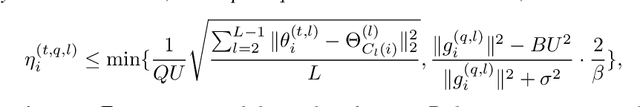


The primary challenge in Federated Learning (FL) is to model non-IID distributions across clients, whose fine-grained structure is important to improve knowledge sharing. For example, some knowledge is globally shared across all clients, some is only transferable within a subgroup of clients, and some are client-specific. To capture and exploit this structure, we train models organized in a multi-level structure, called ``Multi-level Additive Models (MAM)'', for better knowledge-sharing across heterogeneous clients and their personalization. In federated MAM (FeMAM), each client is assigned to at most one model per level and its personalized prediction sums up the outputs of models assigned to it across all levels. For the top level, FeMAM trains one global model shared by all clients as FedAvg. For every mid-level, it learns multiple models each assigned to a subgroup of clients, as clustered FL. Every bottom-level model is trained for one client only. In the training objective, each model aims to minimize the residual of the additive predictions by the other models assigned to each client. To approximate the arbitrary structure of non-IID across clients, FeMAM introduces more flexibility and adaptivity to FL by incrementally adding new models to the prediction of each client and reassigning another if necessary, automatically optimizing the knowledge-sharing structure. Extensive experiments show that FeMAM surpasses existing clustered FL and personalized FL methods in various non-IID settings. Our code is available at https://github.com/shutong043/FeMAM.