 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Transformation: Towards Efficient and Model-Agnostic Unlearning for Dynamic Graph Neural Networks
May 23, 2024



Graph unlearning has emerged as an essential tool for safeguarding user privacy and mitigating the negative impacts of undesirable data. Meanwhile, the advent of dynamic graph neural networks (DGNNs) marks a significant advancement due to their superior capability in learning from dynamic graphs, which encapsulate spatial-temporal variations in diverse real-world applications (e.g., traffic forecasting). With the increasing prevalence of DGNNs, it becomes imperative to investigate the implementation of dynamic graph unlearning. However, current graph unlearning methodologies are designed for GNNs operating on static graphs and exhibit limitations including their serving in a pre-processing manner and impractical resource demands. Furthermore, the adaptation of these methods to DGNNs presents non-trivial challenges, owing to the distinctive nature of dynamic graphs. To this end, we propose an effective, efficient, model-agnostic, and post-processing method to implement DGNN unlearning. Specifically, we first define the unlearning requests and formulate dynamic graph unlearning in the context of continuous-time dynamic graphs. After conducting a role analysis on the unlearning data, the remaining data, and the target DGNN model, we propose a method called Gradient Transformation and a loss function to map the unlearning request to the desired parameter update. Evaluations on six real-world datasets and state-of-the-art DGNN backbones demonstrate its effectiveness (e.g., limited performance drop even obvious improvement) and efficiency (e.g., at most 7.23$\times$ speed-up) outperformance, and potential advantages in handling future unlearning requests (e.g., at most 32.59$\times$ speed-up).
GraphGuard: Detecting and Counteracting Training Data Misuse in Graph Neural Networks
Dec 13, 2023The emergence of Graph Neural Networks (GNNs) in graph data analysis and their deployment on Machine Learning as a Service platforms have raised critical concerns about data misuse during model training. This situation is further exacerbated due to the lack of transparency in local training processes, potentially leading to the unauthorized accumulation of large volumes of graph data, thereby infringing on the intellectual property rights of data owners. Existing methodologies often address either data misuse detection or mitigation, and are primarily designed for local GNN models rather than cloud-based MLaaS platforms. These limitations call for an effective and comprehensive solution that detects and mitigates data misuse without requiring exact training data while respecting the proprietary nature of such data. This paper introduces a pioneering approach called GraphGuard, to tackle these challenges. We propose a training-data-free method that not only detects graph data misuse but also mitigates its impact via targeted unlearning, all without relying on the original training data. Our innovative misuse detection technique employs membership inference with radioactive data, enhancing the distinguishability between member and non-member data distributions. For mitigation, we utilize synthetic graphs that emulate the characteristics previously learned by the target model, enabling effective unlearning even in the absence of exact graph data. We conduct comprehensive experiments utilizing four real-world graph datasets to demonstrate the efficacy of GraphGuard in both detection and unlearning. We show that GraphGuard attains a near-perfect detection rate of approximately 100% across these datasets with various GNN models. In addition, it performs unlearning by eliminating the impact of the unlearned graph with a marginal decrease in accuracy (less than 5%).
Trustworthy Graph Neural Networks: Aspects, Methods and Trends
May 16, 2022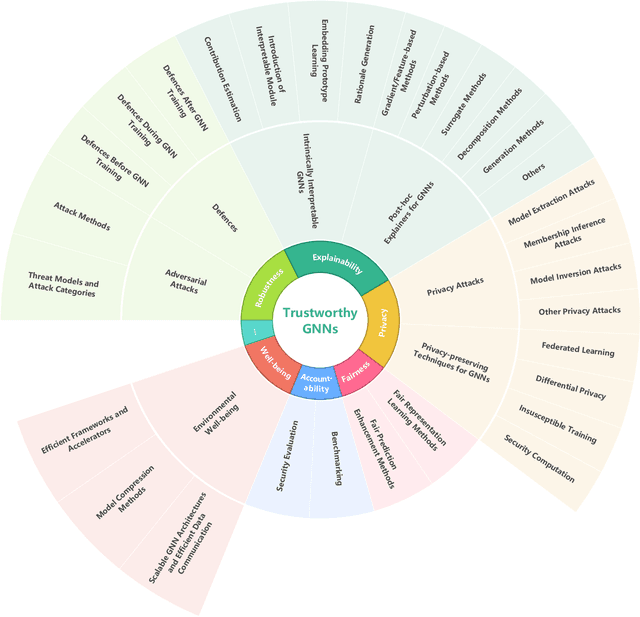
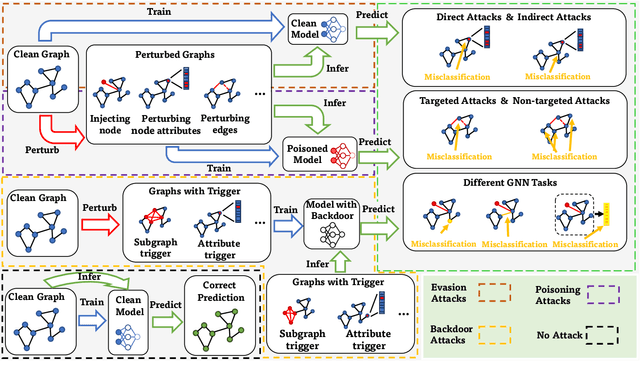
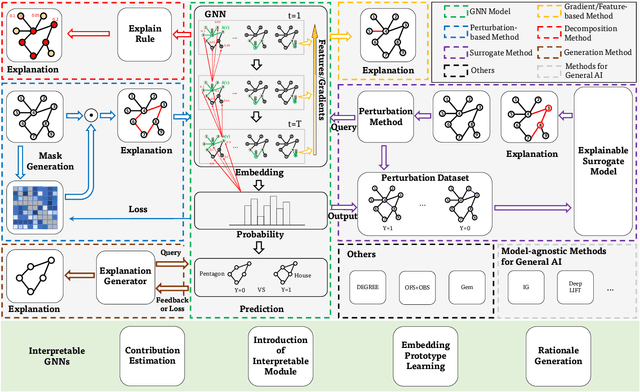
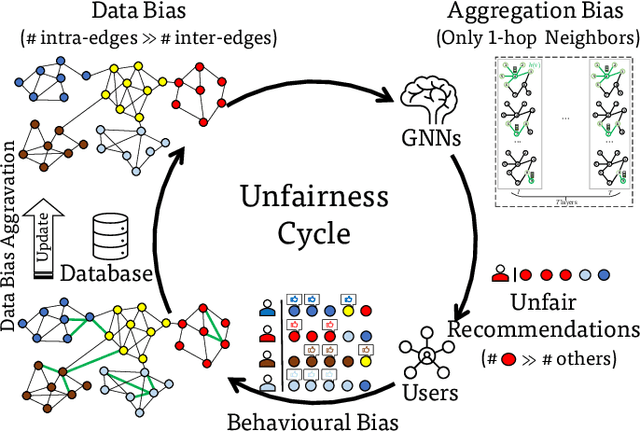
Graph neural networks (GNNs) have emerged as a series of competent graph learning methods for diverse real-world scenarios, ranging from daily applications like recommendation systems and question answering to cutting-edge technologies such as drug discovery in life sciences and n-body simulation in astrophysics. However, task performance is not the only requirement for GNNs. Performance-oriented GNNs have exhibited potential adverse effects like vulnerability to adversarial attacks, unexplainable discrimination against disadvantaged groups, or excessive resource consumption in edge computing environments. To avoid these unintentional harms, it is necessary to build competent GNNs characterised by trustworthiness. To this end, we propose a comprehensive roadmap to build trustworthy GNNs from the view of the various computing technologies involved. In this survey, we introduce basic concepts and comprehensively summarise existing efforts for trustworthy GNNs from six aspects, including robustness, explainability, privacy, fairness, accountability, and environmental well-being. Additionally, we highlight the intricate cross-aspect relations between the above six aspects of trustworthy GNNs. Finally, we present a thorough overview of trending directions for facilitating the research and industrialisation of trustworthy GNNs.
Adapting Membership Inference Attacks to GNN for Graph Classification: Approaches and Implications
Oct 17, 2021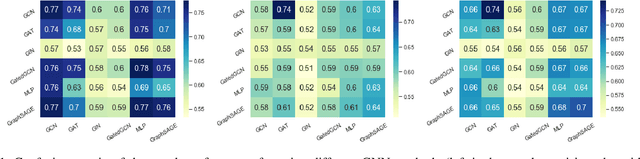
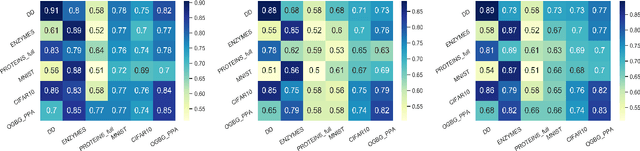
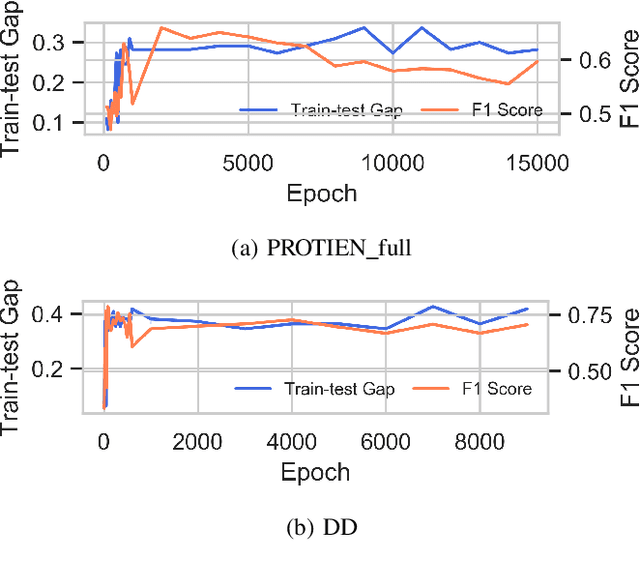
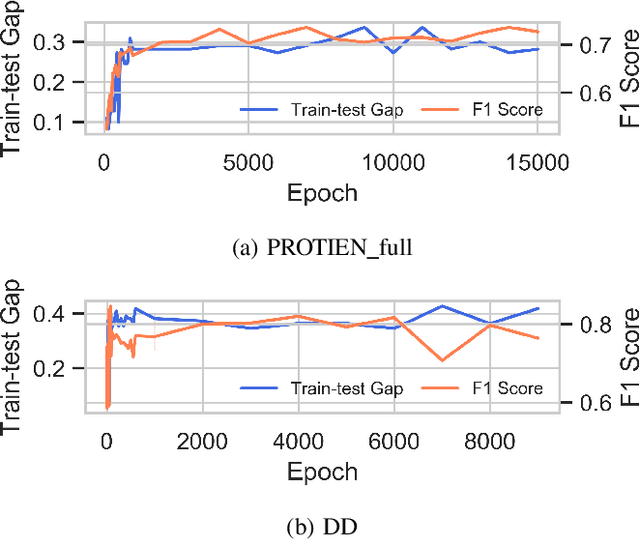
Graph Neural Networks (GNNs) are widely adopted to analyse non-Euclidean data, such as chemical networks, brain networks, and social networks, modelling complex relationships and interdependency between objects. Recently, Membership Inference Attack (MIA) against GNNs raises severe privacy concerns, where training data can be leaked from trained GNN models. However, prior studies focus on inferring the membership of only the components in a graph, e.g., an individual node or edge. How to infer the membership of an entire graph record is yet to be explored. In this paper, we take the first step in MIA against GNNs for graph-level classification. Our objective is to infer whether a graph sample has been used for training a GNN model. We present and implement two types of attacks, i.e., training-based attacks and threshold-based attacks from different adversarial capabilities. We perform comprehensive experiments to evaluate our attacks in seven real-world datasets using five representative GNN models. Both our attacks are shown effective and can achieve high performance, i.e., reaching over 0.7 attack F1 scores in most cases. Furthermore, we analyse the implications behind the MIA against GNNs. Our findings confirm that GNNs can be even more vulnerable to MIA than the models with non-graph structures. And unlike the node-level classifier, MIAs on graph-level classification tasks are more co-related with the overfitting level of GNNs rather than the statistic property of their training graphs.
Model Extraction Attacks on Graph Neural Networks: Taxonomy and Realization
Oct 24, 2020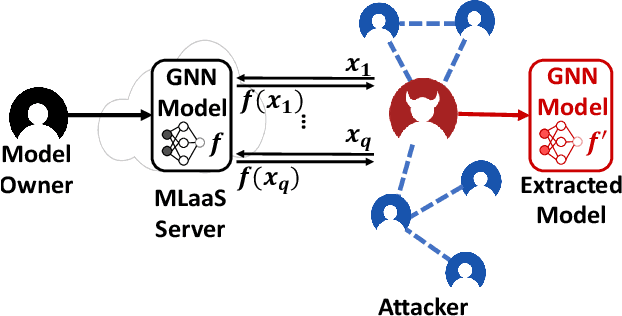

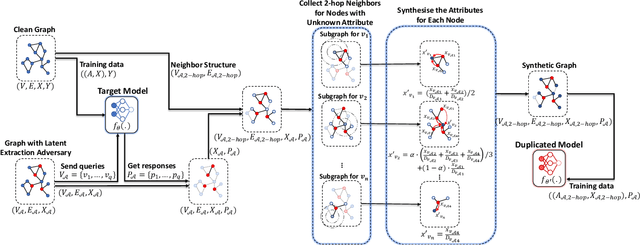
Graph neural networks (GNNs) have been widely used to analyze the graph-structured data in various application domains, e.g., social networks, molecular biology, and anomaly detection. With great power, the GNN models, usually as valuable Intellectual Properties of their owners, also become attractive targets of the attacker. Recent studies show that machine learning models are facing a severe threat called Model Extraction Attacks, where a well-trained private model owned by a service provider can be stolen by the attacker pretending as a client. Unfortunately, existing works focus on the models trained on the Euclidean space, e.g., images and texts, while how to extract a GNN model that contains a graph structure and node features is yet to be explored. In this paper, we explore and develop model extraction attacks against GNN models. Given only black-box access to a target GNN model, the attacker aims to reconstruct a duplicated one via several nodes he obtained (called attacker nodes). We first systematically formalise the threat modeling in the context of GNN model extraction and classify the adversarial threats into seven categories by considering different background knowledge of the attacker, e.g., attributes and/or neighbor connectives of the attacker nodes. Then we present the detailed methods which utilize the accessible knowledge in each threat to implement the attacks. By evaluating over three real-world datasets, our attacks are shown to extract duplicated models effectively, i.e., more than 89% inputs in the target domain have the same output predictions as the victim model.
Defending Against Misclassification Attacks in Transfer Learning
Sep 12, 2019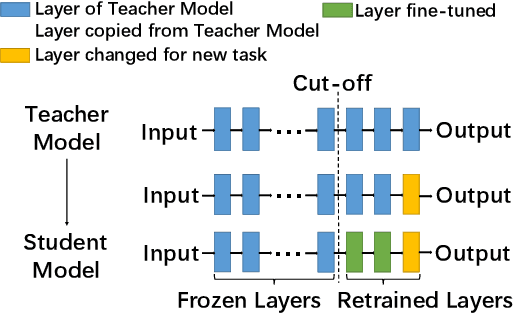
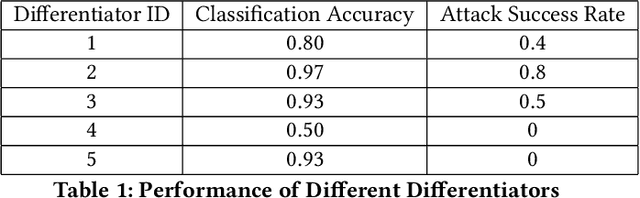
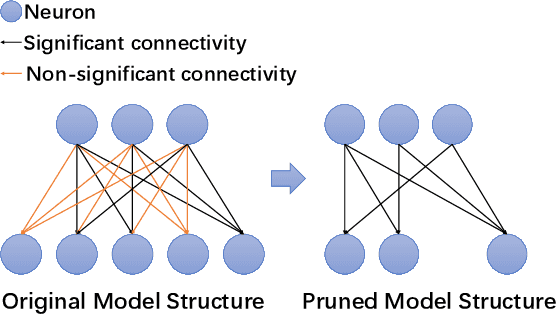
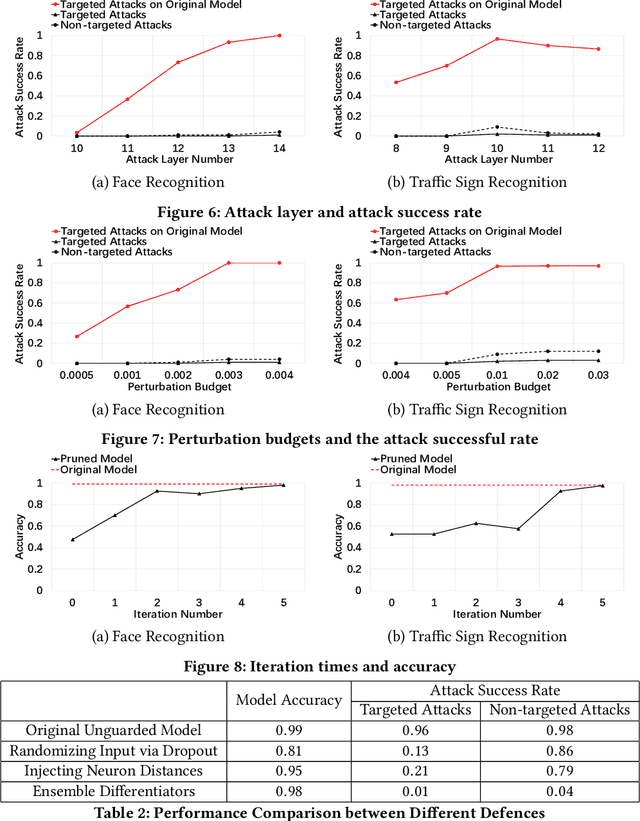
Transfer learning accelerates the development of new models (Student Models). It applies relevant knowledge from a pre-trained model (Teacher Model) to the new ones with a small amount of training data, yet without affecting the model accuracy. However, these Teacher Models are normally open in order to facilitate sharing and reuse, which creates an attack plane in transfer learning systems. Among others, recent emerging attacks demonstrate that adversarial inputs can be built with negligible perturbations to the normal inputs. Such inputs can mimic the internal features of the student models directly based on the knowledge of the Teacher Models and cause misclassification in final predictions. In this paper, we propose an effective defence against the above misclassification attacks in transfer learning. First, we propose a distilled differentiator that can address the targeted attacks, where adversarial inputs are misclassified to a specific class. Specifically, this dedicated differentiator is designed with network activation pruning and retraining in a fine-tuned manner, so as to reach high defence rates and high model accuracy. To address the non-targeted attacks that misclassify adversarial inputs to randomly selected classes, we further employ an ensemble structure from the differentiators to cover all possible misclassification. Our evaluations over common image recognition tasks confirm that the student models applying our defence can reject most of the adversarial inputs with a marginal accuracy loss. We also show that our defence outperforms prior approaches in both targeted and non-targeted attacks.