 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Membership Inference Attacks to GNN for Graph Classification: Approaches and Implications
Paper and Code
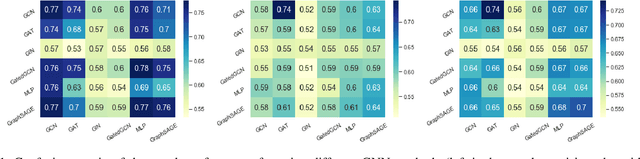
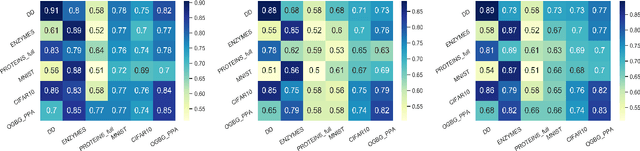
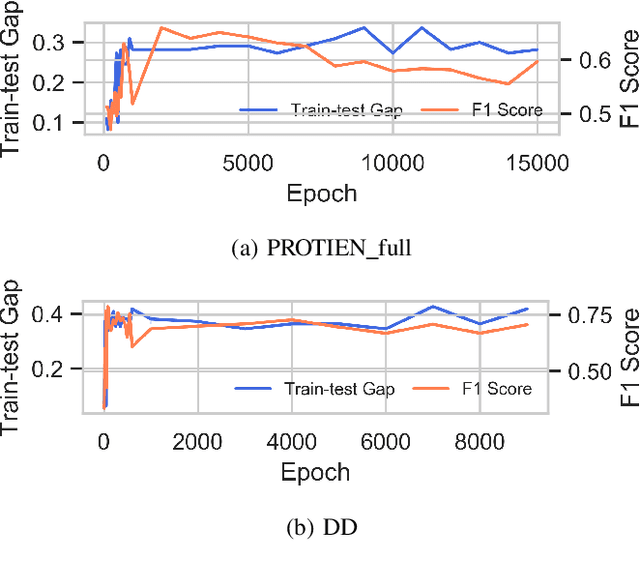
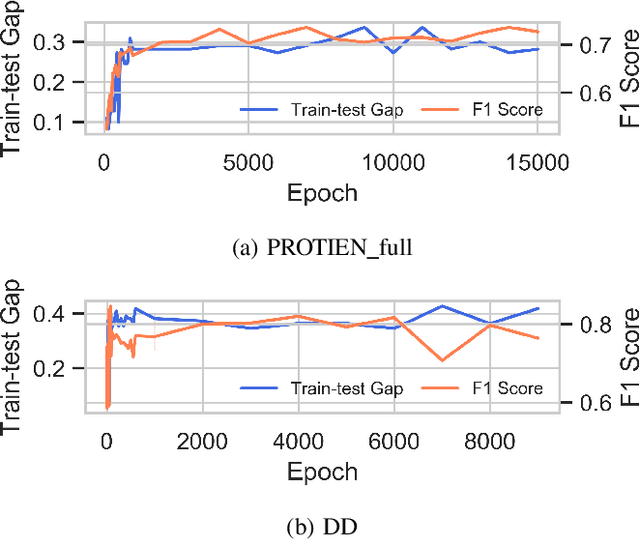
Graph Neural Networks (GNNs) are widely adopted to analyse non-Euclidean data, such as chemical networks, brain networks, and social networks, modelling complex relationships and interdependency between objects. Recently, Membership Inference Attack (MIA) against GNNs raises severe privacy concerns, where training data can be leaked from trained GNN models. However, prior studies focus on inferring the membership of only the components in a graph, e.g., an individual node or edge. How to infer the membership of an entire graph record is yet to be explored. In this paper, we take the first step in MIA against GNNs for graph-level classification. Our objective is to infer whether a graph sample has been used for training a GNN model. We present and implement two types of attacks, i.e., training-based attacks and threshold-based attacks from different adversarial capabilities. We perform comprehensive experiments to evaluate our attacks in seven real-world datasets using five representative GNN models. Both our attacks are shown effective and can achieve high performance, i.e., reaching over 0.7 attack F1 scores in most cases. Furthermore, we analyse the implications behind the MIA against GNNs. Our findings confirm that GNNs can be even more vulnerable to MIA than the models with non-graph structures. And unlike the node-level classifier, MIAs on graph-level classification tasks are more co-related with the overfitting level of GNNs rather than the statistic property of their training graphs.