 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Encoding and Decoding at Scale
Apr 14, 2025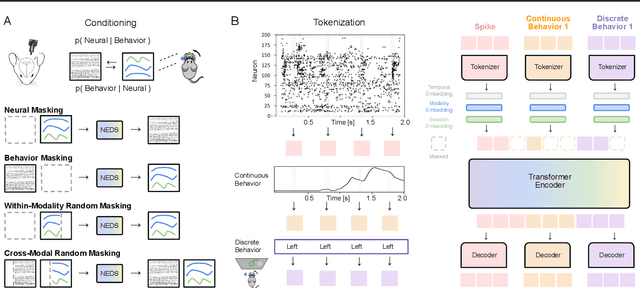

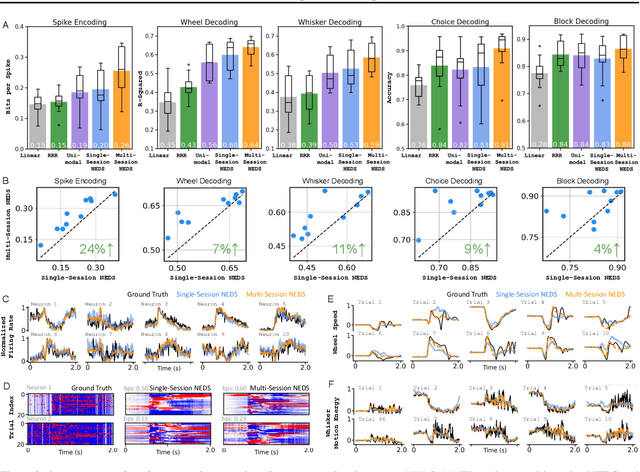
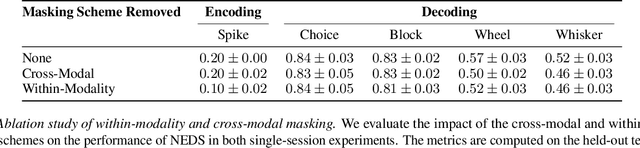
Recent work has demonstrated that large-scale, multi-animal models are powerful tools for characterizing the relationship between neural activity and behavior. Current large-scale approaches, however, focus exclusively on either predicting neural activity from behavior (encoding) or predicting behavior from neural activity (decoding), limiting their ability to capture the bidirectional relationship between neural activity and behavior. To bridge this gap, we introduce a multimodal, multi-task model that enables simultaneous Neural Encoding and Decoding at Scale (NEDS). Central to our approach is a novel multi-task-masking strategy, which alternates between neural, behavioral, within-modality, and cross-modality masking. We pretrain our method on the International Brain Laboratory (IBL) repeated site dataset, which includes recordings from 83 animals performing the same visual decision-making task. In comparison to other large-scale models, we demonstrate that NEDS achieves state-of-the-art performance for both encoding and decoding when pretrained on multi-animal data and then fine-tuned on new animals. Surprisingly, NEDS's learned embeddings exhibit emergent properties: even without explicit training, they are highly predictive of the brain regions in each recording. Altogether, our approach is a step towards a foundation model of the brain that enables seamless translation between neural activity and behavior.
Towards a "universal translator" for neural dynamics at single-cell, single-spike resolution
Jul 23, 2024Neuroscience research has made immense progress over the last decade, but our understanding of the brain remains fragmented and piecemeal: the dream of probing an arbitrary brain region and automatically reading out the information encoded in its neural activity remains out of reach. In this work, we build towards a first foundation model for neural spiking data that can solve a diverse set of tasks across multiple brain areas. We introduce a novel self-supervised modeling approach for population activity in which the model alternates between masking out and reconstructing neural activity across different time steps, neurons, and brain regions. To evaluate our approach, we design unsupervised and supervised prediction tasks using the International Brain Laboratory repeated site dataset, which is comprised of Neuropixels recordings targeting the same brain locations across 48 animals and experimental sessions. The prediction tasks include single-neuron and region-level activity prediction, forward prediction, and behavior decoding. We demonstrate that our multi-task-masking (MtM) approach significantly improves the performance of current state-of-the-art population models and enables multi-task learning. We also show that by training on multiple animals, we can improve the generalization ability of the model to unseen animals, paving the way for a foundation model of the brain at single-cell, single-spike resolution.
Building population models for large-scale neural recordings: opportunities and pitfalls
Feb 03, 2021
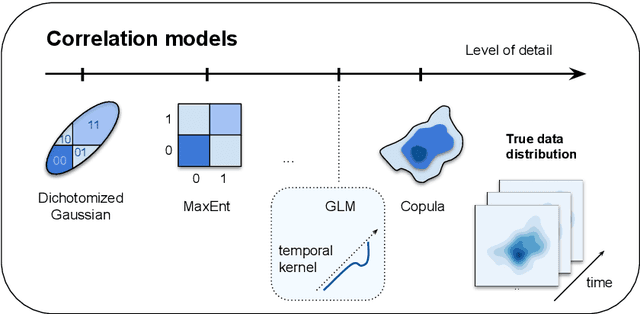
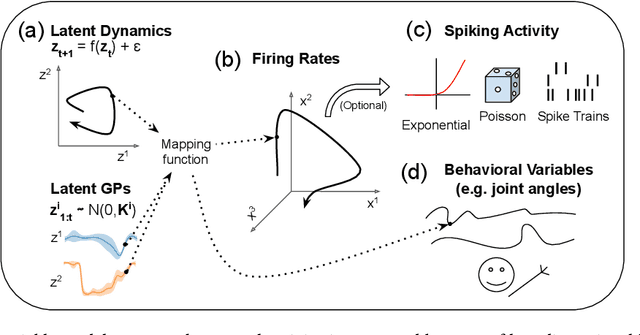
Modern extracellular recording technologies now enable simultaneous recording from large numbers of neurons. This has driven the development of new statistical models for analyzing and interpreting neural population activity. Here we provide a broad overview of recent developments in this area. We compare and contrast different approaches, highlight strengths and limitations, and discuss biological and mechanistic insights that these methods provide. While still an area of active development, there are already a number of powerful models for interpreting large scale neural recordings even in complex experimental settings.
Improving the Reconstruction of Disentangled Representation Learners via Multi-Stage Modelling
Oct 25, 2020

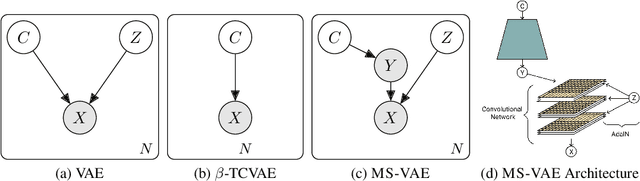

Current autoencoder-based disentangled representation learning methods achieve disentanglement by penalizing the (aggregate) posterior to encourage statistical independence of the latent factors. This approach introduces a trade-off between disentangled representation learning and reconstruction quality since the model does not have enough capacity to learn correlated latent variables that capture detail information present in most image data. To overcome this trade-off, we present a novel multi-stage modelling approach where the disentangled factors are first learned using a preexisting disentangled representation learning method (such as $\beta$-TCVAE); then, the low-quality reconstruction is improved with another deep generative model that is trained to model the missing correlated latent variables, adding detail information while maintaining conditioning on the previously learned disentangled factors. Taken together, our multi-stage modelling approach results in a single, coherent probabilistic model that is theoretically justified by the principal of D-separation and can be realized with a variety of model classes including likelihood-based models such as variational autoencoders, implicit models such as generative adversarial networks, and tractable models like normalizing flows or mixtures of Gaussians. We demonstrate that our multi-stage model has much higher reconstruction quality than current state-of-the-art methods with equivalent disentanglement performance across multiple standard benchmarks.
not-so-BigGAN: Generating High-Fidelity Images on a Small Compute Budget
Sep 09, 2020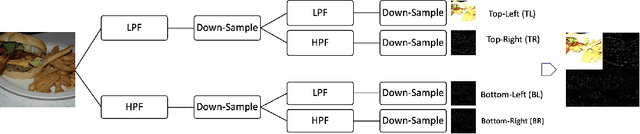
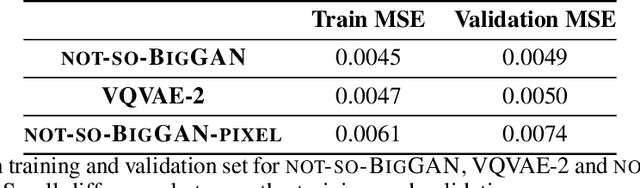
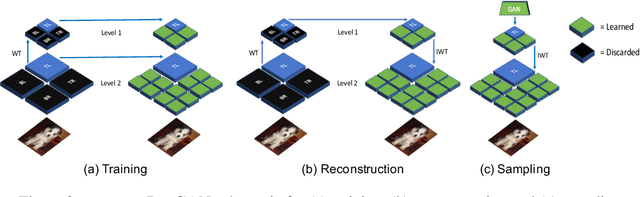

BigGAN is the state-of-the-art in high-resolution image generation, successfully leveraging advancements in scalable computing and theoretical understanding of generative adversarial methods to set new records in conditional image generation. A major part of BigGAN's success is due to its use of large mini-batch sizes during training in high dimensions. While effective, this technique requires an incredible amount of compute resources and/or time (256 TPU-v3 Cores), putting the model out of reach for the larger research community. In this paper, we present not-so-BigGAN, a simple and scalable framework for training deep generative models on high-dimensional natural images. Instead of modelling the image in pixel space like in BigGAN, not-so-BigGAN uses wavelet transformations to bypass the curse of dimensionality, reducing the overall compute requirement significantly. Through extensive empirical evaluation, we demonstrate that for a fixed compute budget, not-so-BigGAN converges several times faster than BigGAN, reaching competitive image quality with an order of magnitude lower compute budget (4 Telsa-V100 GPUs).