 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgenot-so-BigGAN: Generating High-Fidelity Images on a Small Compute Budget
Paper and Code
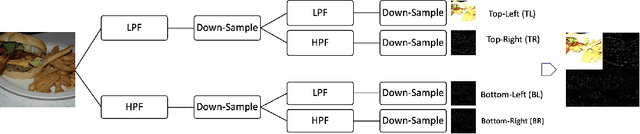
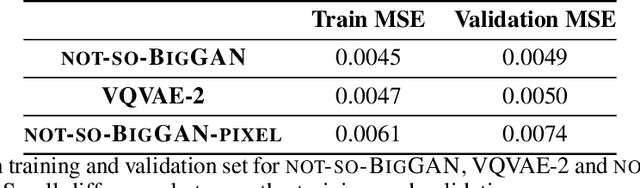
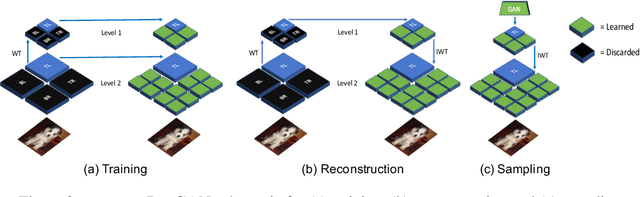

BigGAN is the state-of-the-art in high-resolution image generation, successfully leveraging advancements in scalable computing and theoretical understanding of generative adversarial methods to set new records in conditional image generation. A major part of BigGAN's success is due to its use of large mini-batch sizes during training in high dimensions. While effective, this technique requires an incredible amount of compute resources and/or time (256 TPU-v3 Cores), putting the model out of reach for the larger research community. In this paper, we present not-so-BigGAN, a simple and scalable framework for training deep generative models on high-dimensional natural images. Instead of modelling the image in pixel space like in BigGAN, not-so-BigGAN uses wavelet transformations to bypass the curse of dimensionality, reducing the overall compute requirement significantly. Through extensive empirical evaluation, we demonstrate that for a fixed compute budget, not-so-BigGAN converges several times faster than BigGAN, reaching competitive image quality with an order of magnitude lower compute budget (4 Telsa-V100 GPUs).