 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkeleton-Contrastive 3D Action Representation Learning
Paper and Code
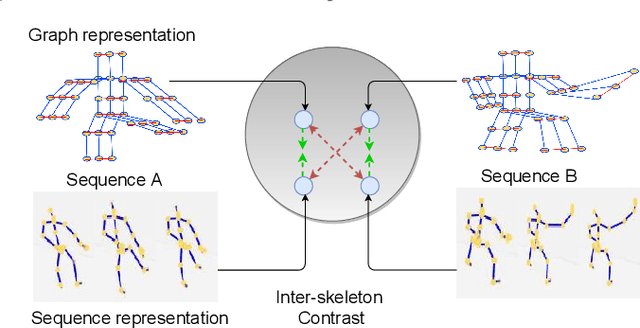
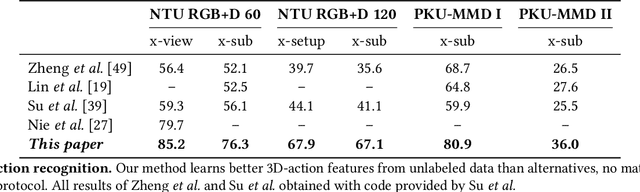
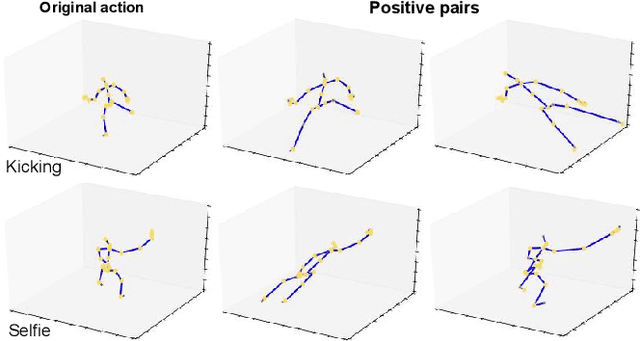
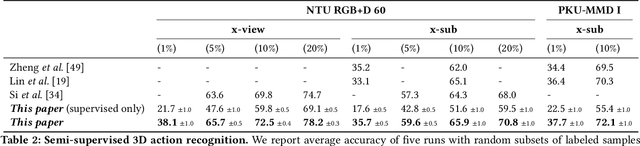
This paper strives for self-supervised learning of a feature space suitable for skeleton-based action recognition. Our proposal is built upon learning invariances to input skeleton representations and various skeleton augmentations via a noise contrastive estimation. In particular, we propose inter-skeleton contrastive learning, which learns from multiple different input skeleton representations in a cross-contrastive manner. In addition, we contribute several skeleton-specific spatial and temporal augmentations which further encourage the model to learn the spatio-temporal dynamics of skeleton data. By learning similarities between different skeleton representations as well as augmented views of the same sequence, the network is encouraged to learn higher-level semantics of the skeleton data than when only using the augmented views. Our approach achieves state-of-the-art performance for self-supervised learning from skeleton data on the challenging PKU and NTU datasets with multiple downstream tasks, including action recognition, action retrieval and semi-supervised learning. Code is available at https://github.com/fmthoker/skeleton-contrast.