 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConceptWeaver: Weaving Disentangled Concepts with Flow
Mar 30, 2026Pre-trained flow-based models excel at synthesizing complex scenes yet lack a direct mechanism for disentangling and customizing their underlying concepts from one-shot real-world sources. To demystify this process, we first introduce a novel differential probing technique to isolate and analyze the influence of individual concept tokens on the velocity field over time. This investigation yields a critical insight: the generative process is not monolithic but unfolds in three distinct stages. An initial \textbf{Blueprint Stage} establishes low-frequency structure, followed by a pivotal \textbf{Instantiation Stage} where content concepts emerge with peak intensity and become naturally disentangled, creating an optimal window for manipulation. A final concept-insensitive refinement stage then synthesizes fine-grained details. Guided by this discovery, we propose \textbf{ConceptWeaver}, a framework for one-shot concept disentanglement. ConceptWeaver learns concept-specific semantic offsets from a single reference image using a stage-aware optimization strategy that aligns with the three-stage framework. These learned offsets are then deployed during inference via our novel ConceptWeaver Guidance (CWG) mechanism, which strategically injects them at the appropriate generative stage. Extensive experiments validate that ConceptWeaver enables high-fidelity, compositional synthesis and editing, demonstrating that understanding and leveraging the intrinsic, staged nature of flow models is key to unlocking precise, multi-granularity content manipulation.
Heuristic Self-Paced Learning for Domain Adaptive Semantic Segmentation under Adverse Conditions
Mar 25, 2026The learning order of semantic classes significantly impacts unsupervised domain adaptation for semantic segmentation, especially under adverse weather conditions. Most existing curricula rely on handcrafted heuristics (e.g., fixed uncertainty metrics) and follow a static schedule, which fails to adapt to a model's evolving, high-dimensional training dynamics, leading to category bias. Inspired by Reinforcement Learning, we cast curriculum learning as a sequential decision problem and propose an autonomous class scheduler. This scheduler consists of two components: (i) a high-dimensional state encoder that maps the model's training status into a latent space and distills key features indicative of progress, and (ii) a category-fair policy-gradient objective that ensures balanced improvement across classes. Coupled with mixed source-target supervision, the learned class rankings direct the network's focus to the most informative classes at each stage, enabling more adaptive and dynamic learning. It is worth noting that our method achieves state-of-the-art performance on three widely used benchmarks (e.g., ACDC, Dark Zurich, and Nighttime Driving) and shows generalization ability in synthetic-to-real semantic segmentation.
Synthetic Data Generation for Brain-Computer Interfaces: Overview, Benchmarking, and Future Directions
Mar 11, 2026Deep learning has achieved transformative performance across diverse domains, largely driven by the large-scale, high-quality training data. In contrast, the development of brain-computer interfaces (BCIs) is fundamentally constrained by the limited, heterogeneous, and privacy-sensitive neural recordings. Generating synthetic yet physiologically plausible brain signals has therefore emerged as a compelling way to mitigate data scarcity and enhance model capacity. This survey provides a comprehensive review of brain signal generation for BCIs, covering methodological taxonomies, benchmark experiments, evaluation metrics, and key applications. We systematically categorize existing generative algorithms into four types: knowledge-based, feature-based, model-based, and translation-based approaches. Furthermore, we benchmark existing brain signal generation approaches across four representative BCI paradigms to provide an objective performance comparison. Finally, we discuss the potentials and challenges of current generation approaches and prospect future research on accurate, data-efficient, and privacy-aware BCI systems. The benchmark codebase is publicized at https://github.com/wzwvv/DG4BCI.
RAICL: Retrieval-Augmented In-Context Learning for Vision-Language-Model Based EEG Seizure Detection
Jan 25, 2026Electroencephalogram (EEG) decoding is a critical component of medical diagnostics, rehabilitation engineering, and brain-computer interfaces. However, contemporary decoding methodologies remain heavily dependent on task-specific datasets to train specialized neural network architectures. Consequently, limited data availability impedes the development of generalizable large brain decoding models. In this work, we propose a paradigm shift from conventional signal-based decoding by leveraging large-scale vision-language models (VLMs) to analyze EEG waveform plots. By converting multivariate EEG signals into stacked waveform images and integrating neuroscience domain expertise into textual prompts, we demonstrate that foundational VLMs can effectively differentiate between different patterns in the human brain. To address the inherent non-stationarity of EEG signals, we introduce a Retrieval-Augmented In-Context Learning (RAICL) approach, which dynamically selects the most representative and relevant few-shot examples to condition the autoregressive outputs of the VLM. Experiments on EEG-based seizure detection indicate that state-of-the-art VLMs under RAICL achieved better or comparable performance with traditional time series based approaches. These findings suggest a new direction in physiological signal processing that effectively bridges the modalities of vision, language, and neural activities. Furthermore, the utilization of off-the-shelf VLMs, without the need for retraining or downstream architecture construction, offers a readily deployable solution for clinical applications.
SAFE: Secure and Accurate Federated Learning for Privacy-Preserving Brain-Computer Interfaces
Jan 09, 2026Electroencephalogram (EEG)-based brain-computer interfaces (BCIs) are widely adopted due to their efficiency and portability; however, their decoding algorithms still face multiple challenges, including inadequate generalization, adversarial vulnerability, and privacy leakage. This paper proposes Secure and Accurate FEderated learning (SAFE), a federated learning-based approach that protects user privacy by keeping data local during model training. SAFE employs local batch-specific normalization to mitigate cross-subject feature distribution shifts and hence improves model generalization. It further enhances adversarial robustness by introducing perturbations in both the input space and the parameter space through federated adversarial training and adversarial weight perturbation. Experiments on five EEG datasets from motor imagery (MI) and event-related potential (ERP) BCI paradigms demonstrated that SAFE consistently outperformed 14 state-of-the-art approaches in both decoding accuracy and adversarial robustness, while ensuring privacy protection. Notably, it even outperformed centralized training approaches that do not consider privacy protection at all. To our knowledge, SAFE is the first algorithm to simultaneously achieve high decoding accuracy, strong adversarial robustness, and reliable privacy protection without using any calibration data from the target subject, making it highly desirable for real-world BCIs.
AFPM: Alignment-based Frame Patch Modeling for Cross-Dataset EEG Decoding
Jul 16, 2025Electroencephalogram (EEG) decoding models for brain-computer interfaces (BCIs) struggle with cross-dataset learning and generalization due to channel layout inconsistencies, non-stationary signal distributions, and limited neurophysiological prior integration. To address these issues, we propose a plug-and-play Alignment-Based Frame-Patch Modeling (AFPM) framework, which has two main components: 1) Spatial Alignment, which selects task-relevant channels based on brain-region priors, aligns EEG distributions across domains, and remaps the selected channels to a unified layout; and, 2) Frame-Patch Encoding, which models multi-dataset signals into unified spatiotemporal patches for EEG decoding. Compared to 17 state-of-the-art approaches that need dataset-specific tuning, the proposed calibration-free AFPM achieves performance gains of up to 4.40% on motor imagery and 3.58% on event-related potential tasks. To our knowledge, this is the first calibration-free cross-dataset EEG decoding framework, substantially enhancing the practicalness of BCIs in real-world applications.
Multi-View Contrastive Network (MVCNet) for Motor Imagery Classification
Feb 27, 2025Objective: An electroencephalography (EEG)-based brain-computer interface (BCI) serves as a direct communication pathway between the human brain and an external device. While supervised learning has been extensively explored for motor imagery (MI) EEG classification, small data quantity has been a key factor limiting the performance of deep feature learning. Methods: This paper proposes a knowledge-driven time-space-frequency based multi-view contrastive network (MVCNet) for MI EEG decoding in BCIs. MVCNet integrates knowledge from the time, space, and frequency domains into the training process through data augmentations from multiple views, fostering more discriminative feature learning of the characteristics of EEG data. We introduce a cross-view contrasting module to learn from different augmented views and a cross-model contrasting module to enhance the consistency of features extracted between knowledge-guided and data-driven models. Results: The combination of EEG data augmentation strategies was systematically investigated for more informative supervised contrastive learning. Experiments on four public MI datasets and three different architectures demonstrated that MVCNet outperformed 10 existing approaches. Significance: Our approach can significantly boost EEG classification performance beyond designated networks, showcasing the potential to enhance the feature learning process for better EEG decoding.
Multimodal Brain-Computer Interfaces: AI-powered Decoding Methodologies
Feb 05, 2025



Brain-computer interfaces (BCIs) enable direct communication between the brain and external devices. This review highlights the core decoding algorithms that enable multimodal BCIs, including a dissection of the elements, a unified view of diversified approaches, and a comprehensive analysis of the present state of the field. We emphasize algorithmic advancements in cross-modality mapping, sequential modeling, besides classic multi-modality fusion, illustrating how these novel AI approaches enhance decoding of brain data. The current literature of BCI applications on visual, speech, and affective decoding are comprehensively explored. Looking forward, we draw attention on the impact of emerging architectures like multimodal Transformers, and discuss challenges such as brain data heterogeneity and common errors. This review also serves as a bridge in this interdisciplinary field for experts with neuroscience background and experts that study AI, aiming to provide a comprehensive understanding for AI-powered multimodal BCIs.
Accurate, Robust and Privacy-Preserving Brain-Computer Interface Decoding
Dec 16, 2024



An electroencephalogram (EEG) based brain-computer interface (BCI) enables direct communication between the brain and external devices. However, EEG-based BCIs face at least three major challenges in real-world applications: data scarcity and individual differences, adversarial vulnerability, and data privacy. While previous studies have addressed one or two of these issues, simultaneous accommodation of all three challenges remains challenging and unexplored. This paper fills this gap, by proposing an Augmented Robustness Ensemble (ARE) algorithm and integrating it into three privacy protection scenarios (centralized source-free transfer, federated source-free transfer, and source data perturbation), achieving simultaneously accurate decoding, adversarial robustness, and privacy protection of EEG-based BCIs. Experiments on three public EEG datasets demonstrated that our proposed approach outperformed over 10 classic and state-of-the-art approaches in both accuracy and robustness in all three privacy-preserving scenarios, even outperforming state-of-the-art transfer learning approaches that do not consider privacy protection at all. This is the first time that three major challenges in EEG-based BCIs can be addressed simultaneously, significantly improving the practicalness of EEG decoding in real-world BCIs.
Adversarial Filtering Based Evasion and Backdoor Attacks to EEG-Based Brain-Computer Interfaces
Dec 10, 2024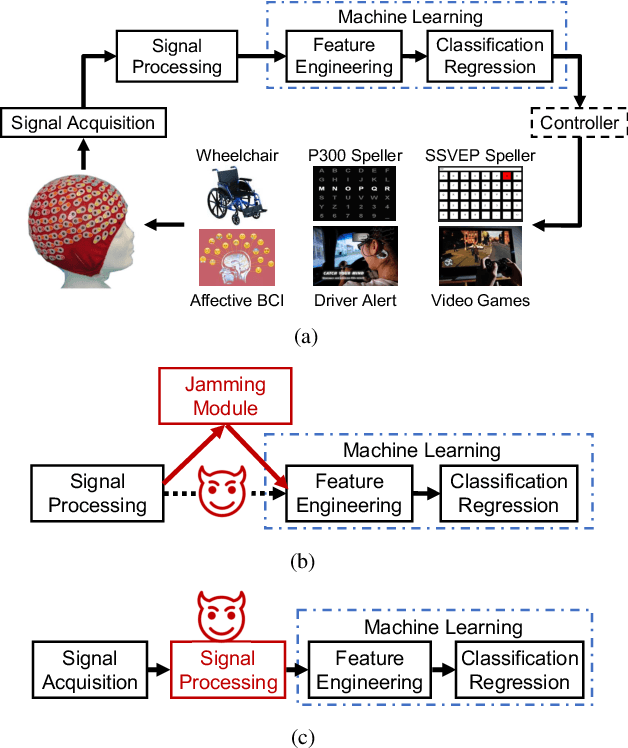
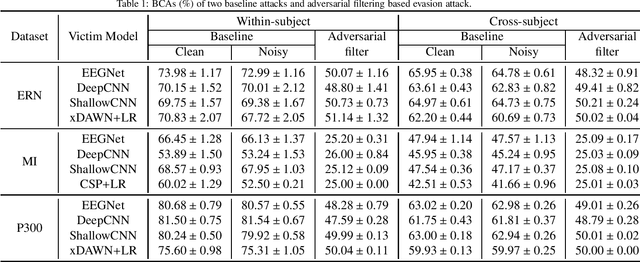
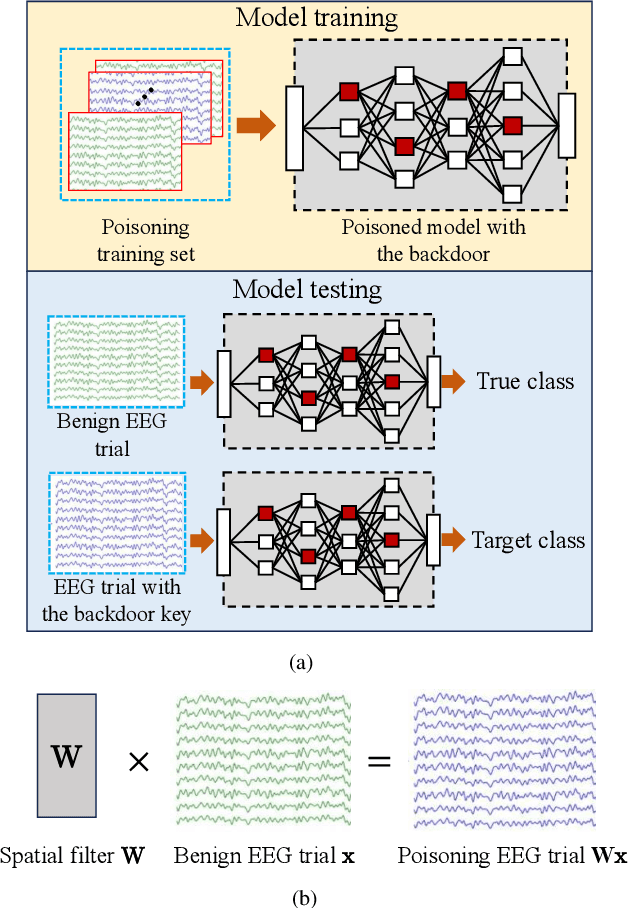
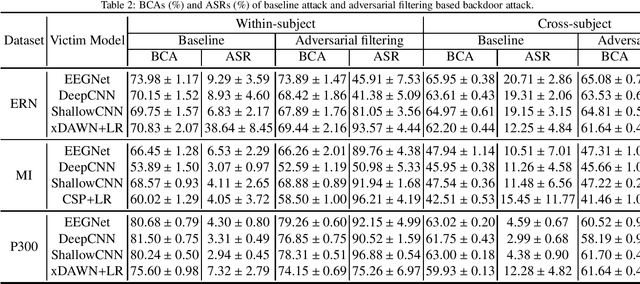
A brain-computer interface (BCI) enables direct communication between the brain and an external device. Electroencephalogram (EEG) is a common input signal for BCIs, due to its convenience and low cost. Most research on EEG-based BCIs focuses on the accurate decoding of EEG signals, while ignoring their security. Recent studies have shown that machine learning models in BCIs are vulnerable to adversarial attacks. This paper proposes adversarial filtering based evasion and backdoor attacks to EEG-based BCIs, which are very easy to implement. Experiments on three datasets from different BCI paradigms demonstrated the effectiveness of our proposed attack approaches. To our knowledge, this is the first study on adversarial filtering for EEG-based BCIs, raising a new security concern and calling for more attention on the security of BCIs.