 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelving into Differentially Private Transformer
May 29, 2024



Deep learning with differential privacy (DP) has garnered significant attention over the past years, leading to the development of numerous methods aimed at enhancing model accuracy and training efficiency. This paper delves into the problem of training Transformer models with differential privacy. Our treatment is modular: the logic is to `reduce' the problem of training DP Transformer to the more basic problem of training DP vanilla neural nets. The latter is better understood and amenable to many model-agnostic methods. Such `reduction' is done by first identifying the hardness unique to DP Transformer training: the attention distraction phenomenon and a lack of compatibility with existing techniques for efficient gradient clipping. To deal with these two issues, we propose the Re-Attention Mechanism and Phantom Clipping, respectively. We believe that our work not only casts new light on training DP Transformers but also promotes a modular treatment to advance research in the field of differentially private deep learning.
PAC Privacy Preserving Diffusion Models
Dec 02, 2023Data privacy protection is garnering increased attention among researchers. Diffusion models (DMs), particularly with strict differential privacy, can potentially produce images with both high privacy and visual quality. However, challenges arise in ensuring robust protection in privatizing specific data attributes, areas where current models often fall short. To address these challenges, we introduce the PAC Privacy Preserving Diffusion Model, a model leverages diffusion principles and ensure Probably Approximately Correct (PAC) privacy. We enhance privacy protection by integrating a private classifier guidance into the Langevin Sampling Process. Additionally, recognizing the gap in measuring the privacy of models, we have developed a novel metric to gauge privacy levels. Our model, assessed with this new metric and supported by Gaussian matrix computations for the PAC bound, has shown superior performance in privacy protection over existing leading private generative models according to benchmark tests.
DPFormer: Learning Differentially Private Transformer on Long-Tailed Data
May 28, 2023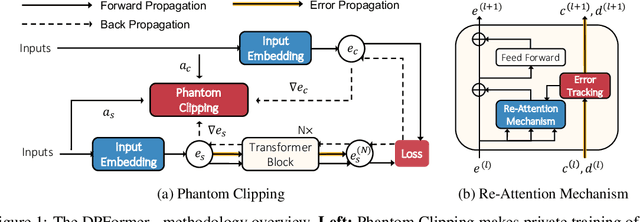



The Transformer has emerged as a versatile and effective architecture with broad applications. However, it still remains an open problem how to efficiently train a Transformer model of high utility with differential privacy guarantees. In this paper, we identify two key challenges in learning differentially private Transformers, i.e., heavy computation overhead due to per-sample gradient clipping and unintentional attention distraction within the attention mechanism. In response, we propose DPFormer, equipped with Phantom Clipping and Re-Attention Mechanism, to address these challenges. Our theoretical analysis shows that DPFormer can reduce computational costs during gradient clipping and effectively mitigate attention distraction (which could obstruct the training process and lead to a significant performance drop, especially in the presence of long-tailed data). Such analysis is further corroborated by empirical results on two real-world datasets, demonstrating the efficiency and effectiveness of the proposed DPFormer.
Revisiting Hyperparameter Tuning with Differential Privacy
Nov 03, 2022


Hyperparameter tuning is a common practice in the application of machine learning but is a typically ignored aspect in the literature on privacy-preserving machine learning due to its negative effect on the overall privacy parameter. In this paper, we aim to tackle this fundamental yet challenging problem by providing an effective hyperparameter tuning framework with differential privacy. The proposed method allows us to adopt a broader hyperparameter search space and even to perform a grid search over the whole space, since its privacy loss parameter is independent of the number of hyperparameter candidates. Interestingly, it instead correlates with the utility gained from hyperparameter searching, revealing an explicit and mandatory trade-off between privacy and utility. Theoretically, we show that its additional privacy loss bound incurred by hyperparameter tuning is upper-bounded by the squared root of the gained utility. However, we note that the additional privacy loss bound would empirically scale like a squared root of the logarithm of the utility term, benefiting from the design of doubling step.
An Efficient Industrial Federated Learning Framework for AIoT: A Face Recognition Application
Jun 30, 2022



Recently, the artificial intelligence of things (AIoT) has been gaining increasing attention, with an intriguing vision of providing highly intelligent services through the network connection of things, leading to an advanced AI-driven ecology. However, recent regulatory restrictions on data privacy preclude uploading sensitive local data to data centers and utilizing them in a centralized approach. Directly applying federated learning algorithms in this scenario could hardly meet the industrial requirements of both efficiency and accuracy. Therefore, we propose an efficient industrial federated learning framework for AIoT in terms of a face recognition application. Specifically, we propose to utilize the concept of transfer learning to speed up federated training on devices and further present a novel design of a private projector that helps protect shared gradients without incurring additional memory consumption or computational cost. Empirical studies on a private Asian face dataset show that our approach can achieve high recognition accuracy in only 20 communication rounds, demonstrating its effectiveness in prediction and its efficiency in training.