 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEPT: Decoupled Embeddings for Pre-training Language Models
Paper and Code
Oct 07, 2024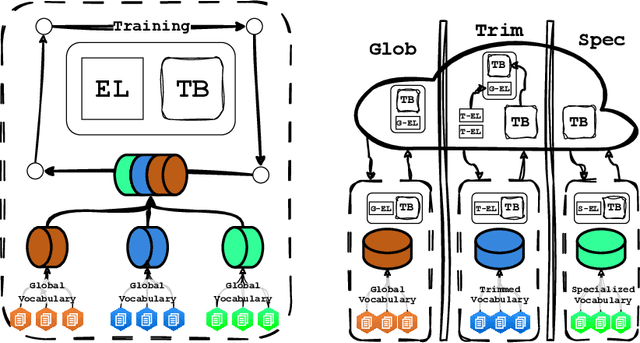
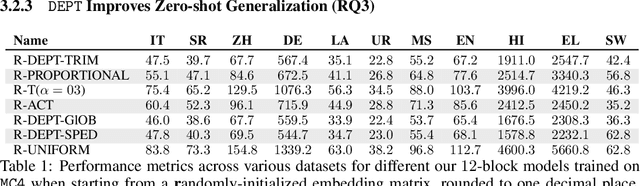


Language Model pre-training benefits from a broader data mixture to enhance performance across domains and languages. However, training on such heterogeneous text corpora is complex, requiring extensive and cost-intensive efforts. Since these data sources vary in lexical, syntactic, and semantic aspects, they cause negative interference or the "curse of multilinguality". We propose a novel pre-training framework to alleviate this curse. Our method, DEPT, decouples the embedding layers from the transformer body while simultaneously training the latter in multiple contexts. DEPT enables the model to train without being bound to a shared global vocabulary. DEPT: (1) can train robustly and effectively under significant data heterogeneity, (2) reduces the parameter count of the token embeddings by up to 80% and the communication costs by 675x for billion-scale models (3) enhances model generalization and plasticity in adapting to new languages and domains, and (4) allows training with custom optimized vocabulary per data source. We prove DEPT's potential by performing the first vocabulary-agnostic federated multilingual pre-training of a 1.3 billion-parameter model across high and low-resource languages, reducing its parameter count by 409 million.