 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Efficient Federated Learning Methods for Foundation Model Training
Jan 09, 2024



Federated Learning (FL) has become an established technique to facilitate privacy-preserving collaborative training. However, new approaches to FL often discuss their contributions involving small deep-learning models only. With the tremendous success of transformer models, the following question arises: What is necessary to operationalize foundation models in an FL application? Knowing that computation and communication often take up similar amounts of time in FL, we introduce a novel taxonomy focused on computational and communication efficiency methods in FL applications. This said, these methods aim to optimize the training time and reduce communication between clients and the server. We also look at the current state of widely used FL frameworks and discuss future research potentials based on existing approaches in FL research and beyond.
Federated Fine-Tuning of LLMs on the Very Edge: The Good, the Bad, the Ugly
Oct 04, 2023



Large Language Models (LLM) and foundation models are popular as they offer new opportunities for individuals and businesses to improve natural language processing, interact with data, and retrieve information faster. However, training or fine-tuning LLMs requires a vast amount of data, which can be challenging to access due to legal or technical restrictions and may require private computing resources. Federated Learning (FL) is a solution designed to overcome these challenges and expand data access for deep learning applications. This paper takes a hardware-centric approach to explore how LLMs can be brought to modern edge computing systems. Our study fine-tunes the FLAN-T5 model family, ranging from 80M to 3B parameters, using FL for a text summarization task. We provide a micro-level hardware benchmark, compare the model FLOP utilization to a state-of-the-art data center GPU, and study the network utilization in realistic conditions. Our contribution is twofold: First, we evaluate the current capabilities of edge computing systems and their potential for LLM FL workloads. Second, by comparing these systems with a data-center GPU, we demonstrate the potential for improvement and the next steps toward achieving greater computational efficiency at the edge.
FLEdge: Benchmarking Federated Machine Learning Applications in Edge Computing Systems
Jun 13, 2023



Federated Machine Learning (FL) has received considerable attention in recent years. FL benchmarks are predominantly explored in either simulated systems or data center environments, neglecting the setups of real-world systems, which are often closely linked to edge computing. We close this research gap by introducing FLEdge, a benchmark targeting FL workloads in edge computing systems. We systematically study hardware heterogeneity, energy efficiency during training, and the effect of various differential privacy levels on training in FL systems. To make this benchmark applicable to real-world scenarios, we evaluate the impact of client dropouts on state-of-the-art FL strategies with failure rates as high as 50%. FLEdge provides new insights, such as that training state-of-the-art FL workloads on older GPU-accelerated embedded devices is up to 3x more energy efficient than on modern server-grade GPUs.
How Can We Train Deep Learning Models Across Clouds and Continents? An Experimental Study
Jun 05, 2023Training deep learning models in the cloud or on dedicated hardware is expensive. A more cost-efficient option are hyperscale clouds offering spot instances, a cheap but ephemeral alternative to on-demand resources. As spot instance availability can change depending on the time of day, continent, and cloud provider, it could be more cost-efficient to distribute resources over the world. Still, it has not been investigated whether geo-distributed, data-parallel spot deep learning training could be a more cost-efficient alternative to centralized training. This paper aims to answer the question: Can deep learning models be cost-efficiently trained on a global market of spot VMs spanning different data centers and cloud providers? To provide guidance, we extensively evaluate the cost and throughput implications of training in different zones, continents, and clouds for representative CV and NLP models. To expand the current training options further, we compare the scalability potential for hybrid-cloud scenarios by adding cloud resources to on-premise hardware to improve training throughput. Finally, we show how leveraging spot instance pricing enables a new cost-efficient way to train models with multiple cheap VMs, trumping both more centralized and powerful hardware and even on-demand cloud offerings at competitive prices.
Where Is My Training Bottleneck? Hidden Trade-Offs in Deep Learning Preprocessing Pipelines
Feb 25, 2022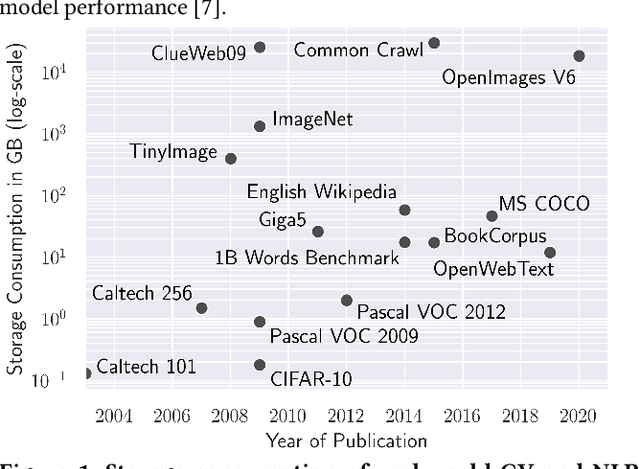

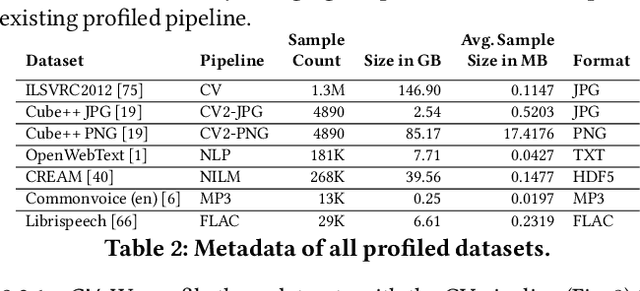

Preprocessing pipelines in deep learning aim to provide sufficient data throughput to keep the training processes busy. Maximizing resource utilization is becoming more challenging as the throughput of training processes increases with hardware innovations (e.g., faster GPUs, TPUs, and inter-connects) and advanced parallelization techniques that yield better scalability. At the same time, the amount of training data needed in order to train increasingly complex models is growing. As a consequence of this development, data preprocessing and provisioning are becoming a severe bottleneck in end-to-end deep learning pipelines. In this paper, we provide an in-depth analysis of data preprocessing pipelines from four different machine learning domains. We introduce a new perspective on efficiently preparing datasets for end-to-end deep learning pipelines and extract individual trade-offs to optimize throughput, preprocessing time, and storage consumption. Additionally, we provide an open-source profiling library that can automatically decide on a suitable preprocessing strategy to maximize throughput. By applying our generated insights to real-world use-cases, we obtain an increased throughput of 3x to 13x compared to an untuned system while keeping the pipeline functionally identical. These findings show the enormous potential of data pipeline tuning.