 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Semantic Segmentation in Transformers using Hierarchical Inter-Level Attention
Jul 05, 2022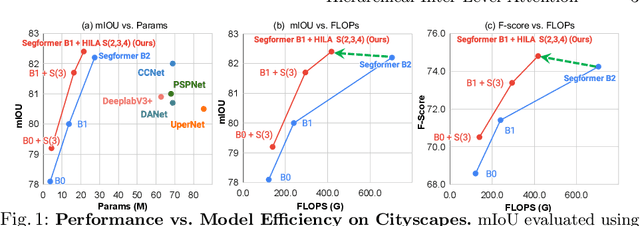
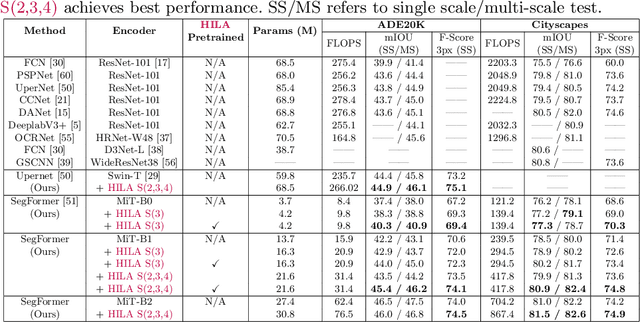
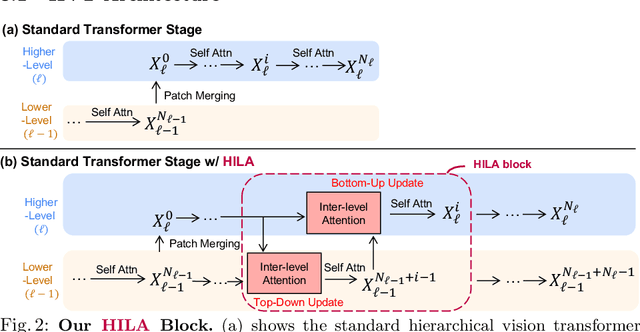
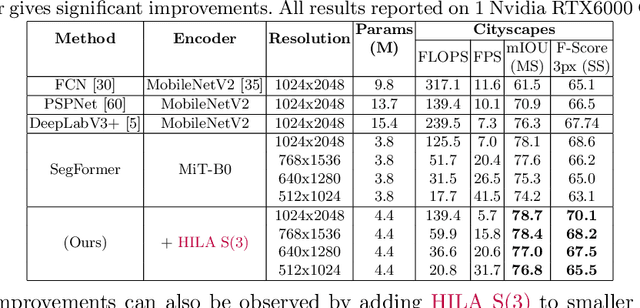
Existing transformer-based image backbones typically propagate feature information in one direction from lower to higher-levels. This may not be ideal since the localization ability to delineate accurate object boundaries, is most prominent in the lower, high-resolution feature maps, while the semantics that can disambiguate image signals belonging to one object vs. another, typically emerges in a higher level of processing. We present Hierarchical Inter-Level Attention (HILA), an attention-based method that captures Bottom-Up and Top-Down Updates between features of different levels. HILA extends hierarchical vision transformer architectures by adding local connections between features of higher and lower levels to the backbone encoder. In each iteration, we construct a hierarchy by having higher-level features compete for assignments to update lower-level features belonging to them, iteratively resolving object-part relationships. These improved lower-level features are then used to re-update the higher-level features. HILA can be integrated into the majority of hierarchical architectures without requiring any changes to the base model. We add HILA into SegFormer and the Swin Transformer and show notable improvements in accuracy in semantic segmentation with fewer parameters and FLOPS. Project website and code: https://www.cs.toronto.edu/~garyleung/hila/
VASTA: A Vision and Language-assisted Smartphone Task Automation System
Nov 04, 2019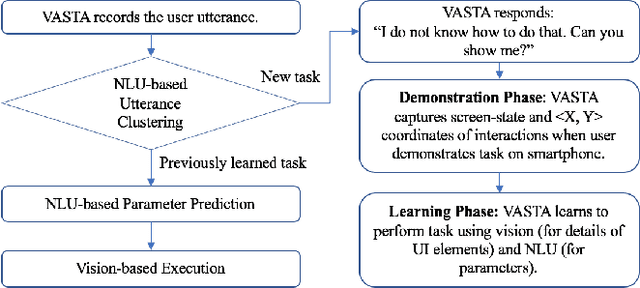

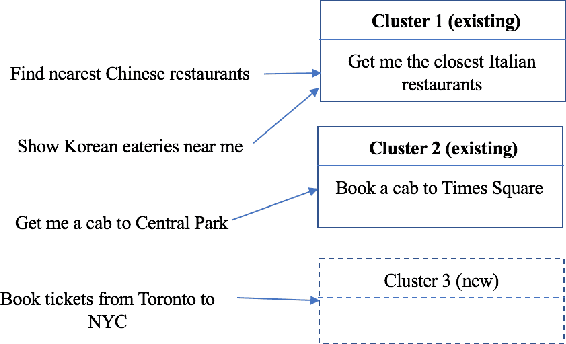
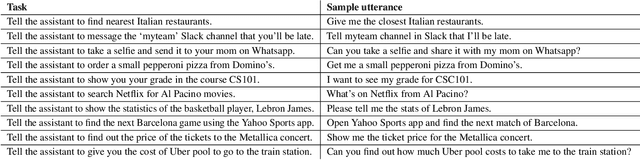
We present VASTA, a novel vision and language-assisted Programming By Demonstration (PBD) system for smartphone task automation. Development of a robust PBD automation system requires overcoming three key challenges: first, how to make a particular demonstration robust to positional and visual changes in the user interface (UI) elements; secondly, how to recognize changes in the automation parameters to make the demonstration as generalizable as possible; and thirdly, how to recognize from the user utterance what automation the user wishes to carry out. To address the first challenge, VASTA leverages state-of-the-art computer vision techniques, including object detection and optical character recognition, to accurately label interactions demonstrated by a user, without relying on the underlying UI structures. To address the second and third challenges, VASTA takes advantage of advanced natural language understanding algorithms for analyzing the user utterance to trigger the VASTA automation scripts, and to determine the automation parameters for generalization. We run an initial user study that demonstrates the effectiveness of VASTA at clustering user utterances, understanding changes in the automation parameters, detecting desired UI elements, and, most importantly, automating various tasks. A demo video of the system is available here: http://y2u.be/kr2xE-FixjI