 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVASTA: A Vision and Language-assisted Smartphone Task Automation System
Nov 04, 2019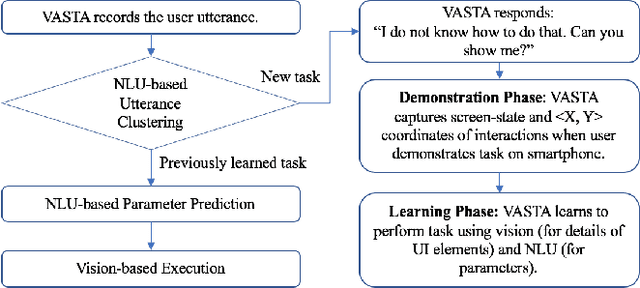

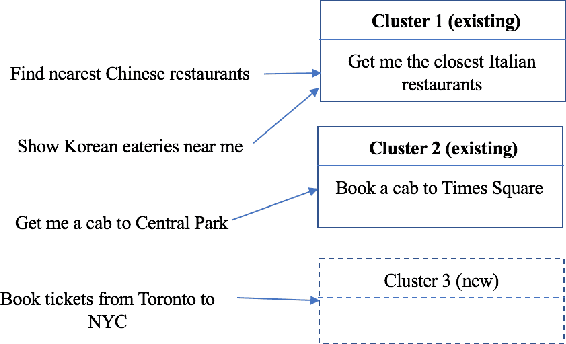
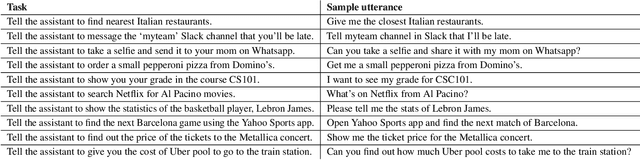
We present VASTA, a novel vision and language-assisted Programming By Demonstration (PBD) system for smartphone task automation. Development of a robust PBD automation system requires overcoming three key challenges: first, how to make a particular demonstration robust to positional and visual changes in the user interface (UI) elements; secondly, how to recognize changes in the automation parameters to make the demonstration as generalizable as possible; and thirdly, how to recognize from the user utterance what automation the user wishes to carry out. To address the first challenge, VASTA leverages state-of-the-art computer vision techniques, including object detection and optical character recognition, to accurately label interactions demonstrated by a user, without relying on the underlying UI structures. To address the second and third challenges, VASTA takes advantage of advanced natural language understanding algorithms for analyzing the user utterance to trigger the VASTA automation scripts, and to determine the automation parameters for generalization. We run an initial user study that demonstrates the effectiveness of VASTA at clustering user utterances, understanding changes in the automation parameters, detecting desired UI elements, and, most importantly, automating various tasks. A demo video of the system is available here: http://y2u.be/kr2xE-FixjI
Semi-supervised and Unsupervised Methods for Categorizing Posts in Web Discussion Forums
Apr 24, 2016
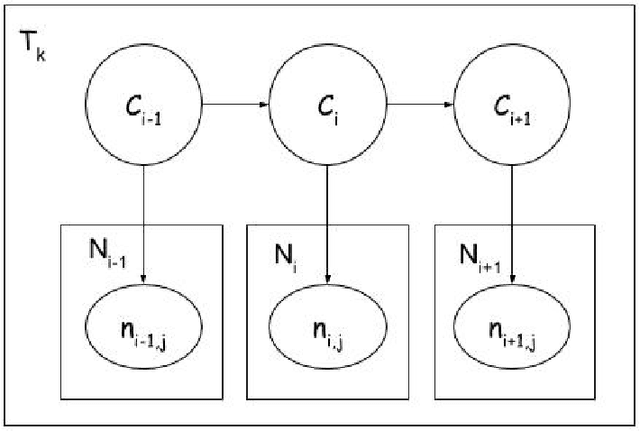
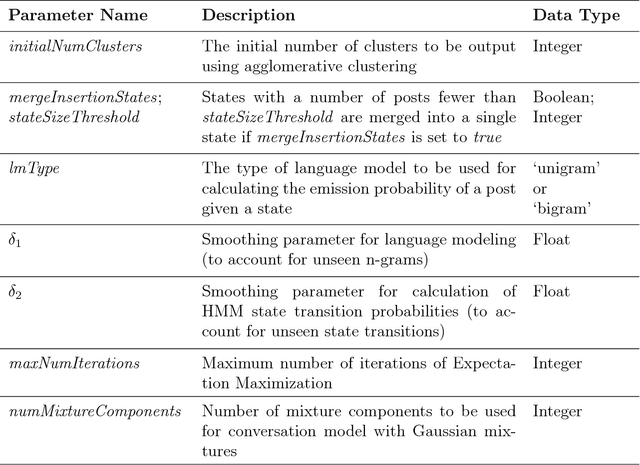
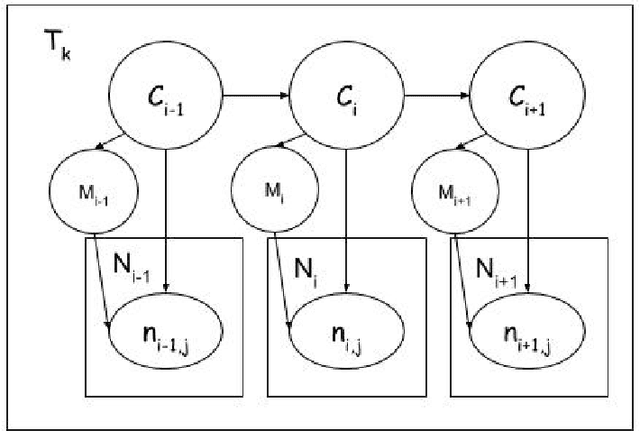
Web discussion forums are used by millions of people worldwide to share information belonging to a variety of domains such as automotive vehicles, pets, sports, etc. They typically contain posts that fall into different categories such as problem, solution, feedback, spam, etc. Automatic identification of these categories can aid information retrieval that is tailored for specific user requirements. Previously, a number of supervised methods have attempted to solve this problem; however, these depend on the availability of abundant training data. A few existing unsupervised and semi-supervised approaches are either focused on identifying a single category or do not report category-specific performance. In contrast, this work proposes unsupervised and semi-supervised methods that require no or minimal training data to achieve this objective without compromising on performance. A fine-grained analysis is also carried out to discuss their limitations. The proposed methods are based on sequence models (specifically, Hidden Markov Models) that can model language for each category using word and part-of-speech probability distributions, and manually specified features. Empirical evaluations across domains demonstrate that the proposed methods are better suited for this task than existing ones.