 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Language-based solution to enable Metaverse Retrieval
Dec 22, 2023
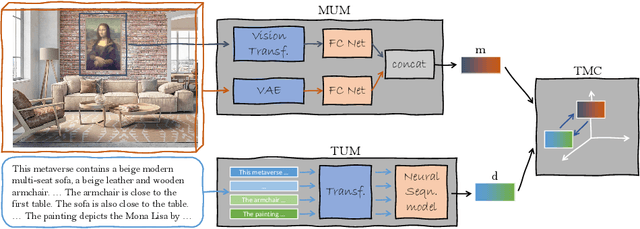

Recently, the Metaverse is becoming increasingly attractive, with millions of users accessing the many available virtual worlds. However, how do users find the one Metaverse which best fits their current interests? So far, the search process is mostly done by word of mouth, or by advertisement on technology-oriented websites. However, the lack of search engines similar to those available for other multimedia formats (e.g., YouTube for videos) is showing its limitations, since it is often cumbersome to find a Metaverse based on some specific interests using the available methods, while also making it difficult to discover user-created ones which lack strong advertisement. To address this limitation, we propose to use language to naturally describe the desired contents of the Metaverse a user wishes to find. Second, we highlight that, differently from more conventional 3D scenes, Metaverse scenarios represent a more complex data format since they often contain one or more types of multimedia which influence the relevance of the scenario itself to a user query. Therefore, in this work, we create a novel task, called Text-to-Metaverse retrieval, which aims at modeling these aspects while also taking the cross-modal relations with the textual data into account. Since we are the first ones to tackle this problem, we also collect a dataset of 33000 Metaverses, each of which consists of a 3D scene enriched with multimedia content. Finally, we design and implement a deep learning framework based on contrastive learning, resulting in a thorough experimental setup.
FArMARe: a Furniture-Aware Multi-task methodology for Recommending Apartments based on the user interests
Sep 06, 2023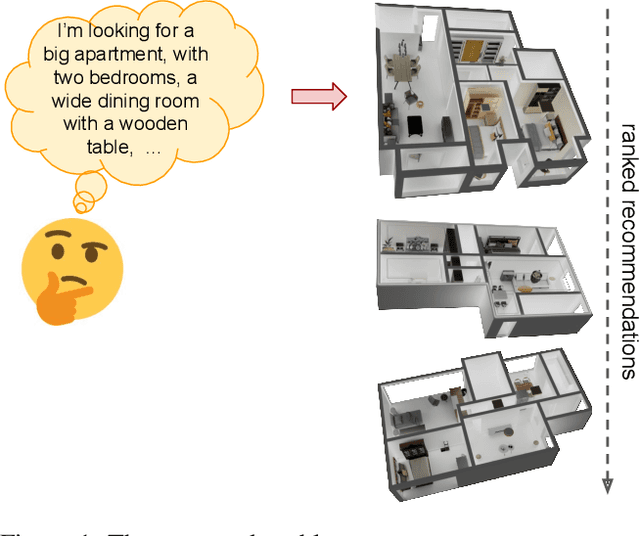



Nowadays, many people frequently have to search for new accommodation options. Searching for a suitable apartment is a time-consuming process, especially because visiting them is often mandatory to assess the truthfulness of the advertisements found on the Web. While this process could be alleviated by visiting the apartments in the metaverse, the Web-based recommendation platforms are not suitable for the task. To address this shortcoming, in this paper, we define a new problem called text-to-apartment recommendation, which requires ranking the apartments based on their relevance to a textual query expressing the user's interests. To tackle this problem, we introduce FArMARe, a multi-task approach that supports cross-modal contrastive training with a furniture-aware objective. Since public datasets related to indoor scenes do not contain detailed descriptions of the furniture, we collect and annotate a dataset comprising more than 6000 apartments. A thorough experimentation with three different methods and two raw feature extraction procedures reveals the effectiveness of FArMARe in dealing with the problem at hand.
Speeding Up Action Recognition Using Dynamic Accumulation of Residuals in Compressed Domain
Sep 29, 2022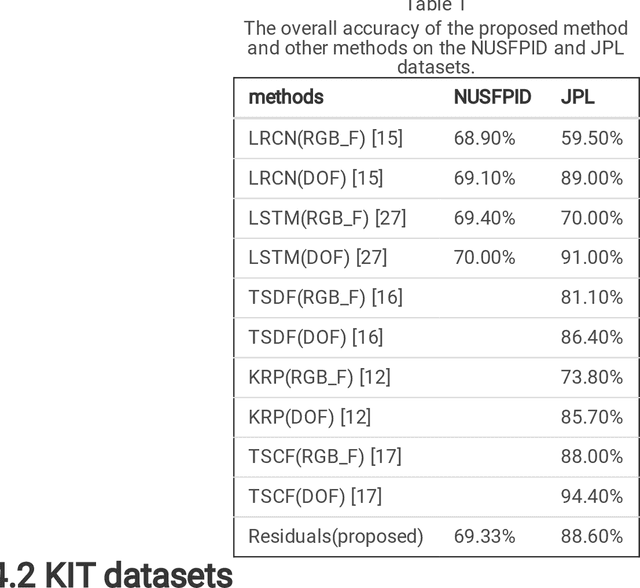
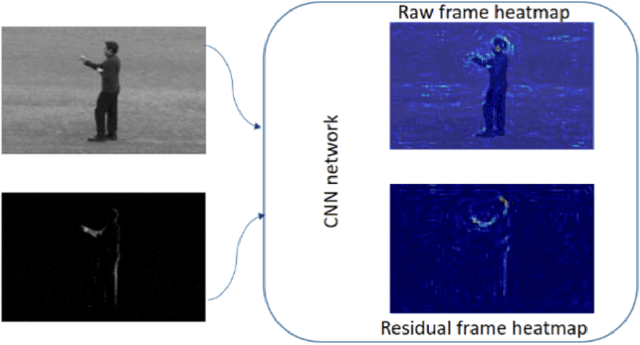
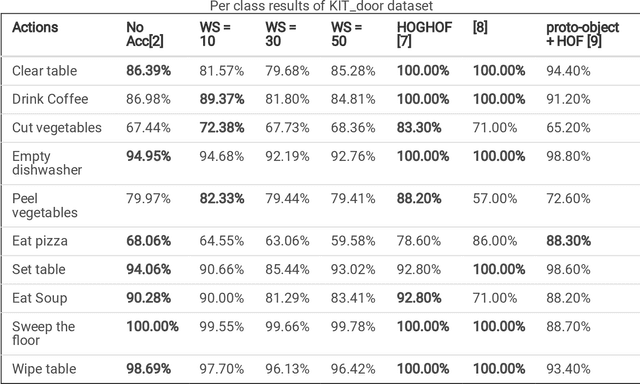

With the widespread use of installed cameras, video-based monitoring approaches have seized considerable attention for different purposes like assisted living. Temporal redundancy and the sheer size of raw videos are the two most common problematic issues related to video processing algorithms. Most of the existing methods mainly focused on increasing accuracy by exploring consecutive frames, which is laborious and cannot be considered for real-time applications. Since videos are mostly stored and transmitted in compressed format, these kinds of videos are available on many devices. Compressed videos contain a multitude of beneficial information, such as motion vectors and quantized coefficients. Proper use of this available information can greatly improve the video understanding methods' performance. This paper presents an approach for using residual data, available in compressed videos directly, which can be obtained by a light partially decoding procedure. In addition, a method for accumulating similar residuals is proposed, which dramatically reduces the number of processed frames for action recognition. Applying neural networks exclusively for accumulated residuals in the compressed domain accelerates performance, while the classification results are highly competitive with raw video approaches.