 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Feature Aggregation Networks for Video Action Recognition
Paper and Code
May 29, 2019

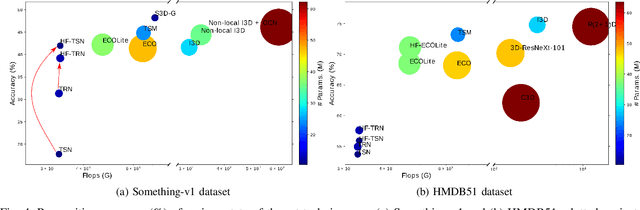

Most action recognition methods base on a) a late aggregation of frame level CNN features using average pooling, max pooling, or RNN, among others, or b) spatio-temporal aggregation via 3D convolutions. The first assume independence among frame features up to a certain level of abstraction and then perform higher-level aggregation, while the second extracts spatio-temporal features from grouped frames as early fusion. In this paper we explore the space in between these two, by letting adjacent feature branches interact as they develop into the higher level representation. The interaction happens between feature differencing and averaging at each level of the hierarchy, and it has convolutional structure that learns to select the appropriate mode locally in contrast to previous works that impose one of the modes globally (e.g. feature differencing) as a design choice. We further constrain this interaction to be conservative, e.g. a local feature subtraction in one branch is compensated by the addition on another, such that the total feature flow is preserved. We evaluate the performance of our proposal on a number of existing models, i.e. TSN, TRN and ECO, to show its flexibility and effectiveness in improving action recognition performance.