 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore Optimal Fractional-Order Stochastic Gradient Descent for Non-Convex Optimization Problems
May 05, 2025Fractional-order stochastic gradient descent (FOSGD) leverages fractional exponents to capture long-memory effects in optimization. However, its utility is often limited by the difficulty of tuning and stabilizing these exponents. We propose 2SED Fractional-Order Stochastic Gradient Descent (2SEDFOSGD), which integrates the Two-Scale Effective Dimension (2SED) algorithm with FOSGD to adapt the fractional exponent in a data-driven manner. By tracking model sensitivity and effective dimensionality, 2SEDFOSGD dynamically modulates the exponent to mitigate oscillations and hasten convergence. Theoretically, for onoconvex optimization problems, this approach preserves the advantages of fractional memory without the sluggish or unstable behavior observed in na\"ive fractional SGD. Empirical evaluations in Gaussian and $\alpha$-stable noise scenarios using an autoregressive (AR) model highlight faster convergence and more robust parameter estimates compared to baseline methods, underscoring the potential of dimension-aware fractional techniques for advanced modeling and estimation tasks.
Effective Dimension Aware Fractional-Order Stochastic Gradient Descent for Convex Optimization Problems
Mar 17, 2025



Fractional-order stochastic gradient descent (FOSGD) leverages a fractional exponent to capture long-memory effects in optimization, yet its practical impact is often constrained by the difficulty of tuning and stabilizing this exponent. In this work, we introduce 2SED Fractional-Order Stochastic Gradient Descent (2SEDFOSGD), a novel method that synergistically combines the Two-Scale Effective Dimension (2SED) algorithm with FOSGD to automatically calibrate the fractional exponent in a data-driven manner. By continuously gauging model sensitivity and effective dimensionality, 2SED dynamically adjusts the exponent to curb erratic oscillations and enhance convergence rates. Theoretically, we demonstrate how this dimension-aware adaptation retains the benefits of fractional memory while averting the sluggish or unstable behaviors frequently observed in naive fractional SGD. Empirical evaluations across multiple benchmarks confirm that our 2SED-driven fractional exponent approach not only converges faster but also achieves more robust final performance, suggesting broad applicability for fractional-order methodologies in large-scale machine learning and related domains.
Symmetric Rank-One Quasi-Newton Methods for Deep Learning Using Cubic Regularization
Feb 17, 2025Stochastic gradient descent and other first-order variants, such as Adam and AdaGrad, are commonly used in the field of deep learning due to their computational efficiency and low-storage memory requirements. However, these methods do not exploit curvature information. Consequently, iterates can converge to saddle points or poor local minima. On the other hand, Quasi-Newton methods compute Hessian approximations which exploit this information with a comparable computational budget. Quasi-Newton methods re-use previously computed iterates and gradients to compute a low-rank structured update. The most widely used quasi-Newton update is the L-BFGS, which guarantees a positive semi-definite Hessian approximation, making it suitable in a line search setting. However, the loss functions in DNNs are non-convex, where the Hessian is potentially non-positive definite. In this paper, we propose using a limited-memory symmetric rank-one quasi-Newton approach which allows for indefinite Hessian approximations, enabling directions of negative curvature to be exploited. Furthermore, we use a modified adaptive regularized cubics approach, which generates a sequence of cubic subproblems that have closed-form solutions with suitable regularization choices. We investigate the performance of our proposed method on autoencoders and feed-forward neural network models and compare our approach to state-of-the-art first-order adaptive stochastic methods as well as other quasi-Newton methods.x
Sequential anomaly detection in the presence of noise and limited feedback
Mar 13, 2012
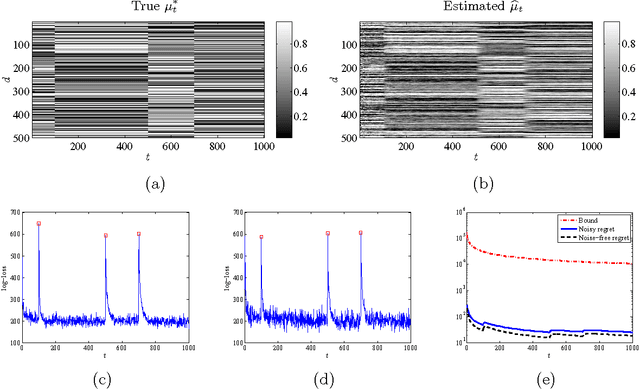
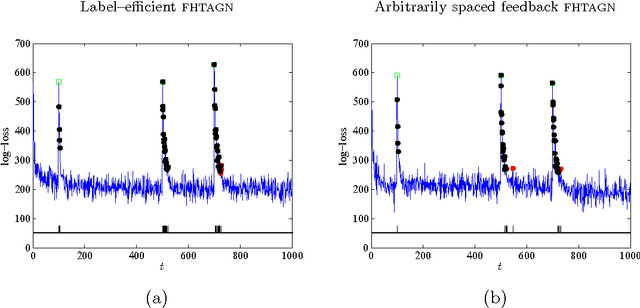

This paper describes a methodology for detecting anomalies from sequentially observed and potentially noisy data. The proposed approach consists of two main elements: (1) {\em filtering}, or assigning a belief or likelihood to each successive measurement based upon our ability to predict it from previous noisy observations, and (2) {\em hedging}, or flagging potential anomalies by comparing the current belief against a time-varying and data-adaptive threshold. The threshold is adjusted based on the available feedback from an end user. Our algorithms, which combine universal prediction with recent work on online convex programming, do not require computing posterior distributions given all current observations and involve simple primal-dual parameter updates. At the heart of the proposed approach lie exponential-family models which can be used in a wide variety of contexts and applications, and which yield methods that achieve sublinear per-round regret against both static and slowly varying product distributions with marginals drawn from the same exponential family. Moreover, the regret against static distributions coincides with the minimax value of the corresponding online strongly convex game. We also prove bounds on the number of mistakes made during the hedging step relative to the best offline choice of the threshold with access to all estimated beliefs and feedback signals. We validate the theory on synthetic data drawn from a time-varying distribution over binary vectors of high dimensionality, as well as on the Enron email dataset.