 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore Optimal Fractional-Order Stochastic Gradient Descent for Non-Convex Optimization Problems
May 05, 2025Fractional-order stochastic gradient descent (FOSGD) leverages fractional exponents to capture long-memory effects in optimization. However, its utility is often limited by the difficulty of tuning and stabilizing these exponents. We propose 2SED Fractional-Order Stochastic Gradient Descent (2SEDFOSGD), which integrates the Two-Scale Effective Dimension (2SED) algorithm with FOSGD to adapt the fractional exponent in a data-driven manner. By tracking model sensitivity and effective dimensionality, 2SEDFOSGD dynamically modulates the exponent to mitigate oscillations and hasten convergence. Theoretically, for onoconvex optimization problems, this approach preserves the advantages of fractional memory without the sluggish or unstable behavior observed in na\"ive fractional SGD. Empirical evaluations in Gaussian and $\alpha$-stable noise scenarios using an autoregressive (AR) model highlight faster convergence and more robust parameter estimates compared to baseline methods, underscoring the potential of dimension-aware fractional techniques for advanced modeling and estimation tasks.
Effective Dimension Aware Fractional-Order Stochastic Gradient Descent for Convex Optimization Problems
Mar 17, 2025



Fractional-order stochastic gradient descent (FOSGD) leverages a fractional exponent to capture long-memory effects in optimization, yet its practical impact is often constrained by the difficulty of tuning and stabilizing this exponent. In this work, we introduce 2SED Fractional-Order Stochastic Gradient Descent (2SEDFOSGD), a novel method that synergistically combines the Two-Scale Effective Dimension (2SED) algorithm with FOSGD to automatically calibrate the fractional exponent in a data-driven manner. By continuously gauging model sensitivity and effective dimensionality, 2SED dynamically adjusts the exponent to curb erratic oscillations and enhance convergence rates. Theoretically, we demonstrate how this dimension-aware adaptation retains the benefits of fractional memory while averting the sluggish or unstable behaviors frequently observed in naive fractional SGD. Empirical evaluations across multiple benchmarks confirm that our 2SED-driven fractional exponent approach not only converges faster but also achieves more robust final performance, suggesting broad applicability for fractional-order methodologies in large-scale machine learning and related domains.
Self-optimizing loop sifting and majorization for 3D reconstruction
Apr 22, 2021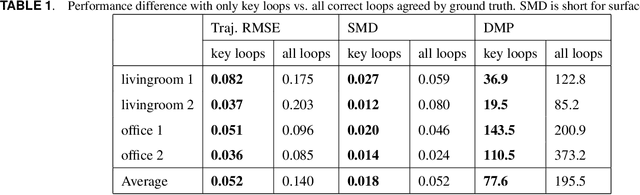
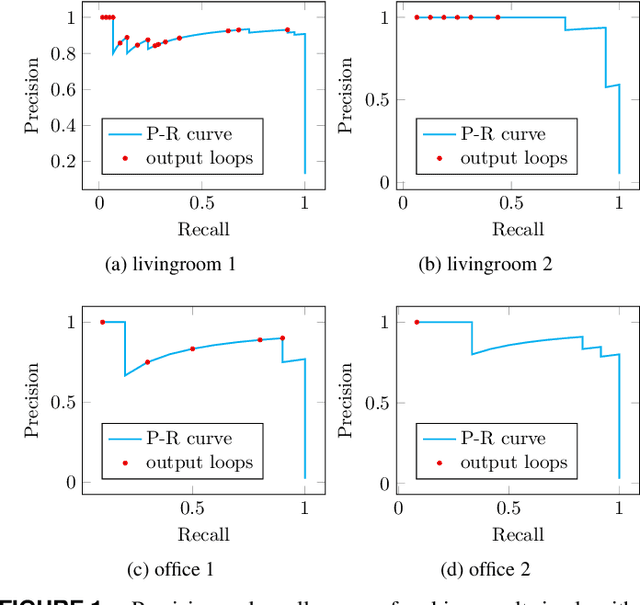
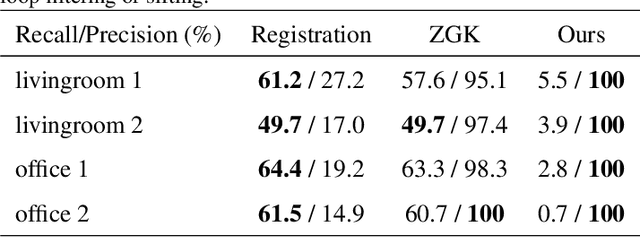

Visual simultaneous localization and mapping (vSLAM) and 3D reconstruction methods have gone through impressive progress. These methods are very promising for autonomous vehicle and consumer robot applications because they can map large-scale environments such as cities and indoor environments without the need for much human effort. However, when it comes to loop detection and optimization, there is still room for improvement. vSLAM systems tend to add the loops very conservatively to reduce the severe influence of the false loops. These conservative checks usually lead to correct loops rejected, thus decrease performance. In this paper, an algorithm that can sift and majorize loop detections is proposed. Our proposed algorithm can compare the usefulness and effectiveness of different loops with the dense map posterior (DMP) metric. The algorithm tests and decides the acceptance of each loop without a single user-defined threshold. Thus it is adaptive to different data conditions. The proposed method is general and agnostic to sensor type (as long as depth or LiDAR reading presents), loop detection, and optimization methods. Neither does it require a specific type of SLAM system. Thus it has great potential to be applied to various application scenarios. Experiments are conducted on public datasets. Results show that the proposed method outperforms state-of-the-art methods.
A metric for evaluating 3D reconstruction and mapping performance with no ground truthing
Jan 25, 2021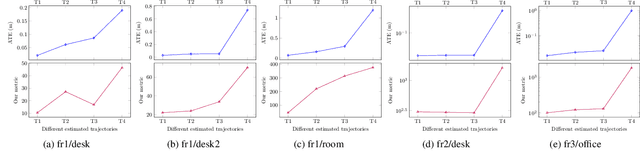
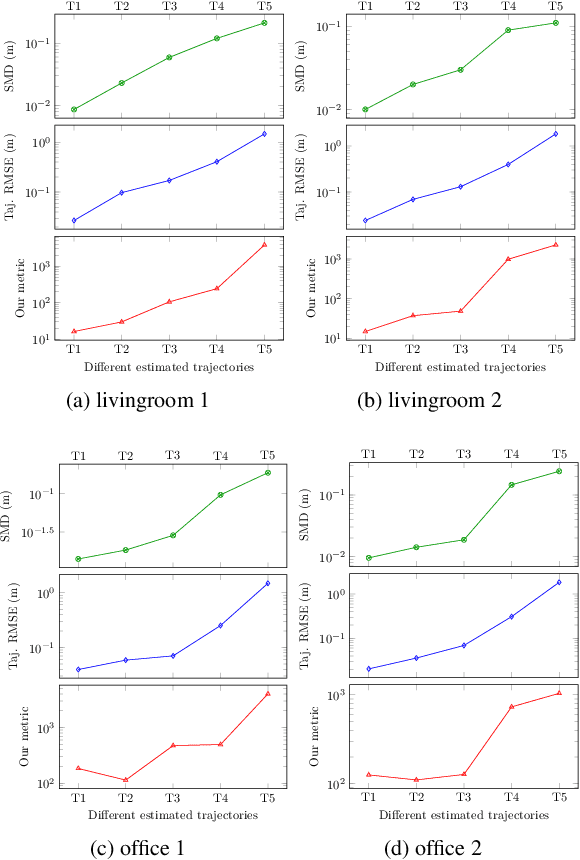
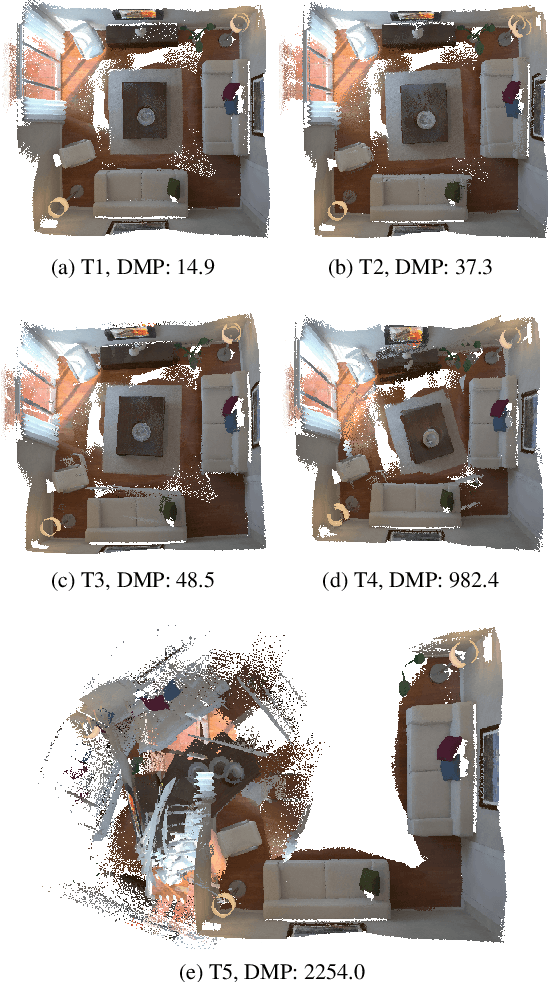
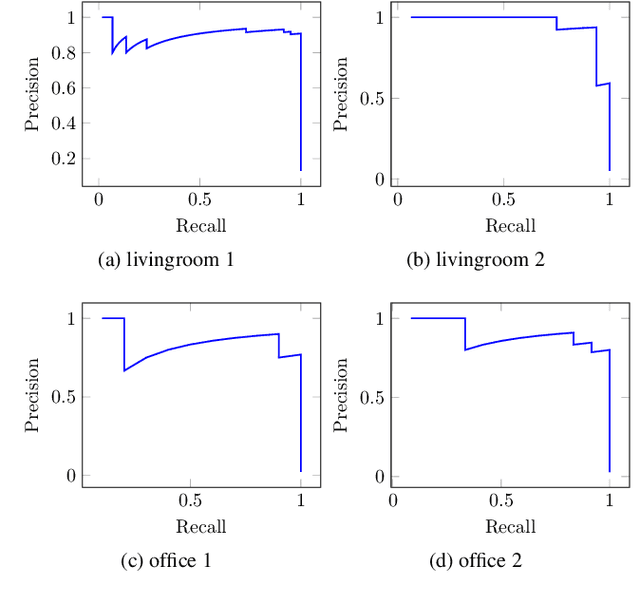
It is not easy when evaluating 3D mapping performance because existing metrics require ground truth data that can only be collected with special instruments. In this paper, we propose a metric, dense map posterior (DMP), for this evaluation. It can work without any ground truth data. Instead, it calculates a comparable value, reflecting a map posterior probability, from dense point cloud observations. In our experiments, the proposed DMP is benchmarked against ground truth-based metrics. Results show that DMP can provide a similar evaluation capability. The proposed metric makes evaluating different methods more flexible and opens many new possibilities, such as self-supervised methods and more available datasets.
More Informed Random Sample Consensus
Nov 18, 2020
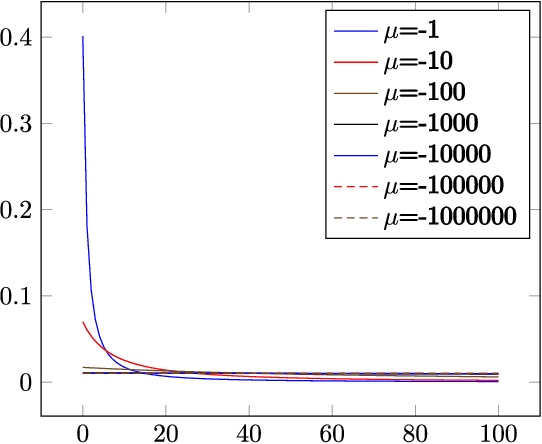
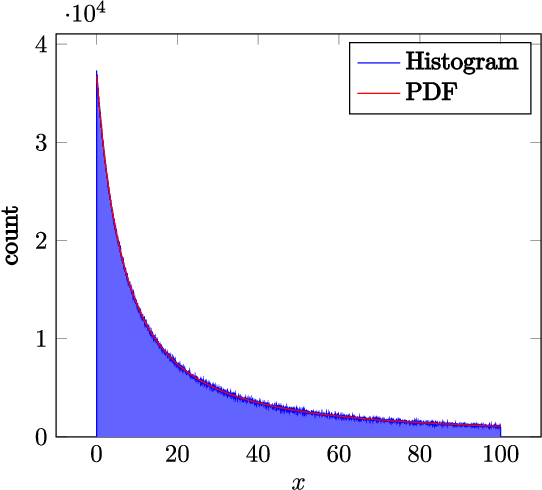
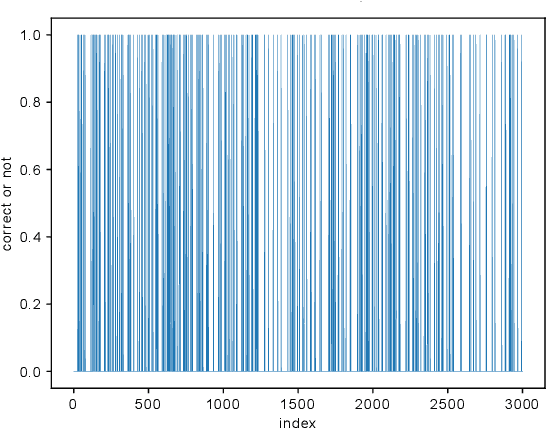
Random sample consensus (RANSAC) is a robust model-fitting algorithm. It is widely used in many fields including image-stitching and point cloud registration. In RANSAC, data is uniformly sampled for hypothesis generation. However, this uniform sampling strategy does not fully utilize all the information on many problems. In this paper, we propose a method that samples data with a L\'{e}vy distribution together with a data sorting algorithm. In the hypothesis sampling step of the proposed method, data is sorted with a sorting algorithm we proposed, which sorts data based on the likelihood of a data point being in the inlier set. Then, hypotheses are sampled from the sorted data with L\'{e}vy distribution. The proposed method is evaluated on both simulation and real-world public datasets. Our method shows better results compared with the uniform baseline method.
FaultFace: Deep Convolutional Generative Adversarial Network (DCGAN) based Ball-Bearing Failure Detection Method
Jul 30, 2020



Failure detection is employed in the industry to improve system performance and reduce costs due to unexpected malfunction events. So, a good dataset of the system is desirable for designing an automated failure detection system. However, industrial process datasets are unbalanced and contain little information about failure behavior due to the uniqueness of these events and the high cost for running the system just to get information about the undesired behaviors. For this reason, performing correct training and validation of automated failure detection methods is challenging. This paper proposes a methodology called FaultFace for failure detection on Ball-Bearing joints for rotational shafts using deep learning techniques to create balanced datasets. The FaultFace methodology uses 2D representations of vibration signals denominated faceportraits obtained by time-frequency transformation techniques. From the obtained faceportraits, a Deep Convolutional Generative Adversarial Network is employed to produce new faceportraits of the nominal and failure behaviors to get a balanced dataset. A Convolutional Neural Network is trained for fault detection employing the balanced dataset. The FaultFace methodology is compared with other deep learning techniques to evaluate its performance in for fault detection with unbalanced datasets. Obtained results show that FaultFace methodology has a good performance for failure detection for unbalanced datasets.
LoopSmart: Smart Visual SLAM Through Surface Loop Closure
Jan 04, 2018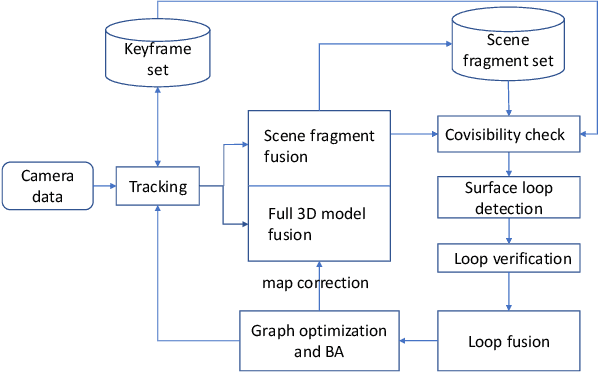

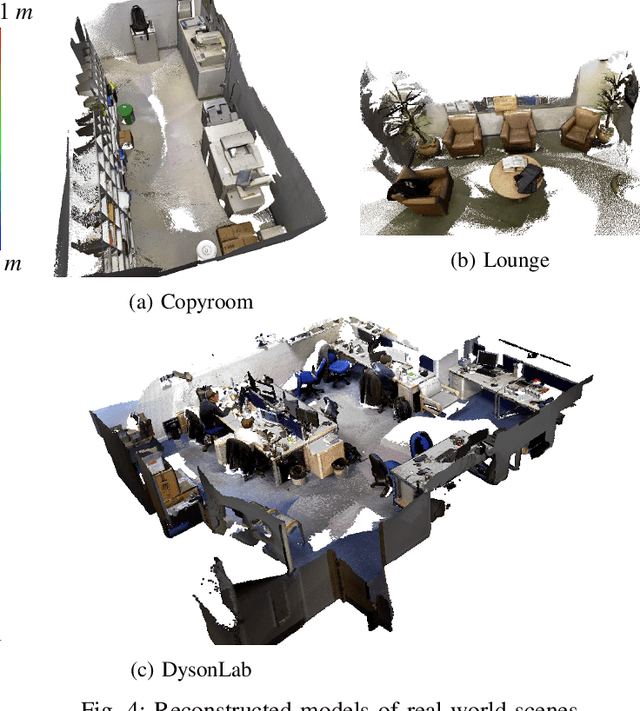

We present a visual simultaneous localization and mapping (SLAM) framework of closing surface loops. It combines both sparse feature matching and dense surface alignment. Sparse feature matching is used for visual odometry and globally camera pose fine-tuning when dense loops are detected, while dense surface alignment is the way of closing large loops and solving surface mismatching problem. To achieve smart dense surface loop closure, a highly efficient CUDA-based global point cloud registration method and a map content dependent loop verification method are proposed. We run extensive experiments on different datasets, our method outperforms state-of-the-art ones in terms of both camera trajectory and surface reconstruction accuracy.
Single image super-resolution using self-optimizing mask via fractional-order gradient interpolation and reconstruction
Mar 18, 2017

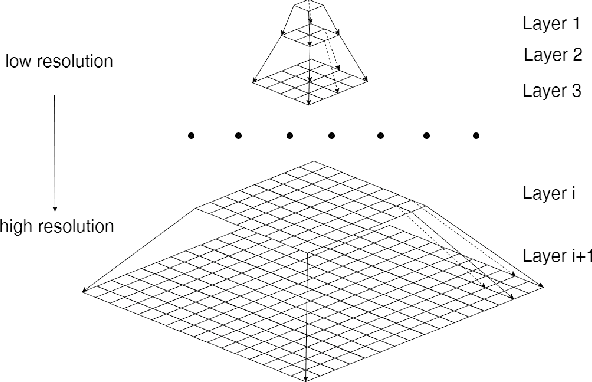
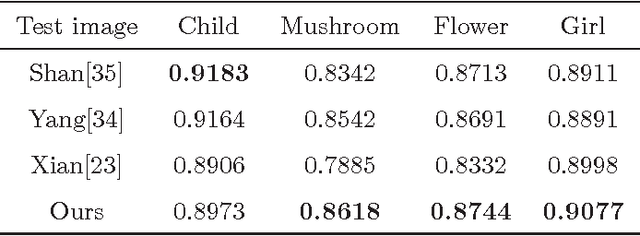
Image super-resolution using self-optimizing mask via fractional-order gradient interpolation and reconstruction aims to recover detailed information from low-resolution images and reconstruct them into high-resolution images. Due to the limited amount of data and information retrieved from low-resolution images, it is difficult to restore clear, artifact-free images, while still preserving enough structure of the image such as the texture. This paper presents a new single image super-resolution method which is based on adaptive fractional-order gradient interpolation and reconstruction. The interpolated image gradient via optimal fractional-order gradient is first constructed according to the image similarity and afterwards the minimum energy function is employed to reconstruct the final high-resolution image. Fractional-order gradient based interpolation methods provide an additional degree of freedom which helps optimize the implementation quality due to the fact that an extra free parameter $\alpha$-order is being used. The proposed method is able to produce a rich texture detail while still being able to maintain structural similarity even under large zoom conditions. Experimental results show that the proposed method performs better than current single image super-resolution techniques.
Fractional Calculus In Image Processing: A Review
Aug 10, 2016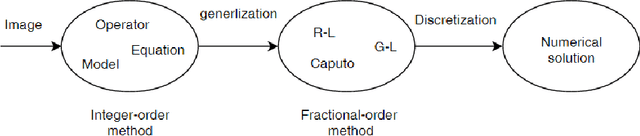
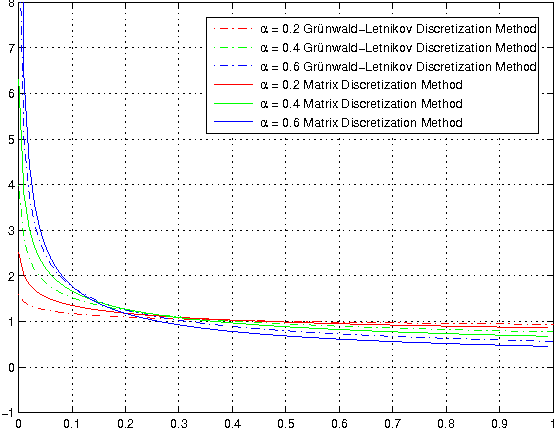

Over the last decade, it has been demonstrated that many systems in science and engineering can be modeled more accurately by fractional-order than integer-order derivatives, and many methods are developed to solve the problem of fractional systems. Due to the extra free parameter order, fractional-order based methods provide additional degree of freedom in optimization performance. Not surprisingly, many fractional-order based methods have been used in image processing field. Herein recent studies are reviewed in ten sub-fields, which include image enhancement, image denoising, image edge detection, image segmentation, image registration, image recognition, image fusion, image encryption, image compression and image restoration. In sum, it is well proved that as a fundamental mathematic tool, fractional-order derivative shows great success in image processing.
Blind Detection and Compensation of Camera Lens Geometric Distortions
May 25, 2004

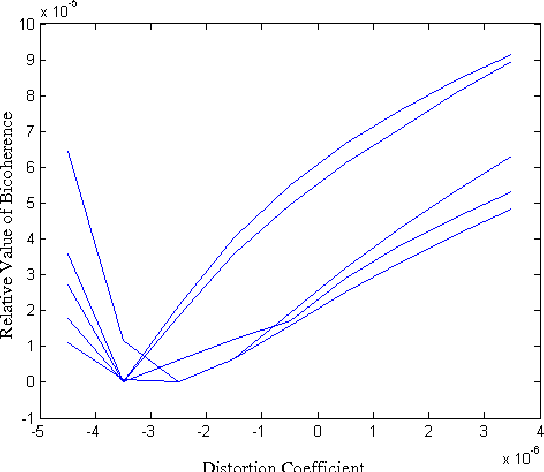
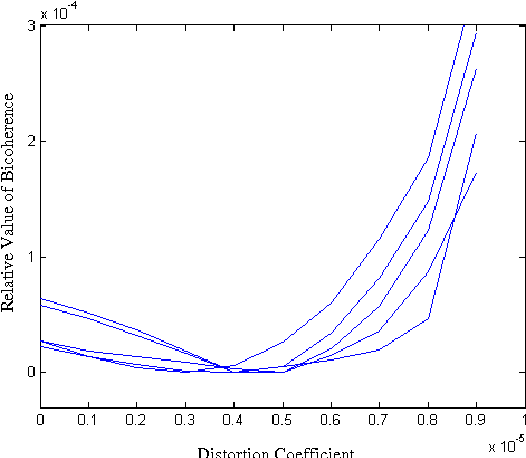
This paper presents a blind detection and compensation technique for camera lens geometric distortions. The lens distortion introduces higher-order correlations in the frequency domain and in turn it can be detected using higher-order spectral analysis tools without assuming any specific calibration target. The existing blind lens distortion removal method only considered a single-coefficient radial distortion model. In this paper, two coefficients are considered to model approximately the geometric distortion. All the models considered have analytical closed-form inverse formulae.
* 6 pages, 4 figures, 2 tables