 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocalized Uncertainty Attacks
Jun 17, 2021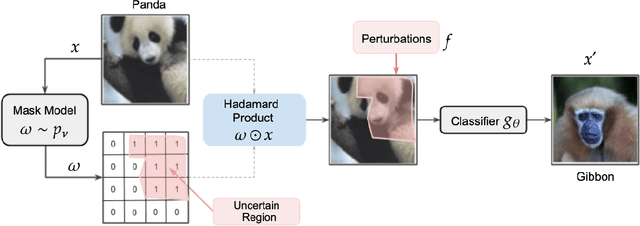
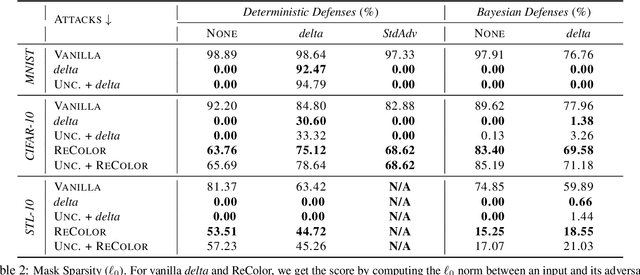
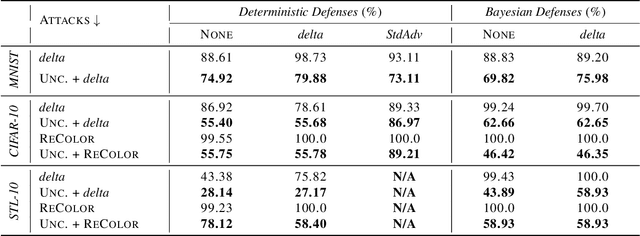

The susceptibility of deep learning models to adversarial perturbations has stirred renewed attention in adversarial examples resulting in a number of attacks. However, most of these attacks fail to encompass a large spectrum of adversarial perturbations that are imperceptible to humans. In this paper, we present localized uncertainty attacks, a novel class of threat models against deterministic and stochastic classifiers. Under this threat model, we create adversarial examples by perturbing only regions in the inputs where a classifier is uncertain. To find such regions, we utilize the predictive uncertainty of the classifier when the classifier is stochastic or, we learn a surrogate model to amortize the uncertainty when it is deterministic. Unlike $\ell_p$ ball or functional attacks which perturb inputs indiscriminately, our targeted changes can be less perceptible. When considered under our threat model, these attacks still produce strong adversarial examples; with the examples retaining a greater degree of similarity with the inputs.
Multi-Task Learning with Incomplete Data for Healthcare
Jul 06, 2018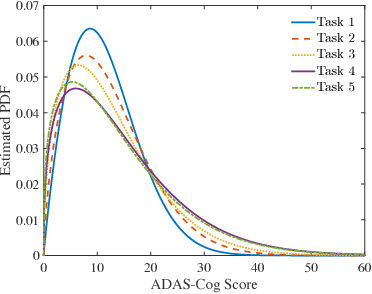

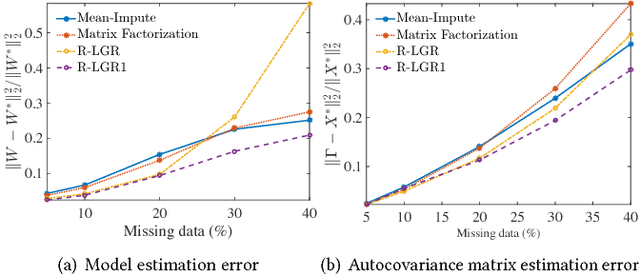
Multi-task learning is a type of transfer learning that trains multiple tasks simultaneously and leverages the shared information between related tasks to improve the generalization performance. However, missing features in the input matrix is a much more difficult problem which needs to be carefully addressed. Removing records with missing values can significantly reduce the sample size, which is impractical for datasets with large percentage of missing values. Popular imputation methods often distort the covariance structure of the data, which causes inaccurate inference. In this paper we propose using plug-in covariance matrix estimators to tackle the challenge of missing features. Specifically, we analyze the plug-in estimators under the framework of robust multi-task learning with LASSO and graph regularization, which captures the relatedness between tasks via graph regularization. We use the Alzheimer's disease progression dataset as an example to show how the proposed framework is effective for prediction and model estimation when missing data is present.
RULLS: Randomized Union of Locally Linear Subspaces for Feature Engineering
Apr 25, 2018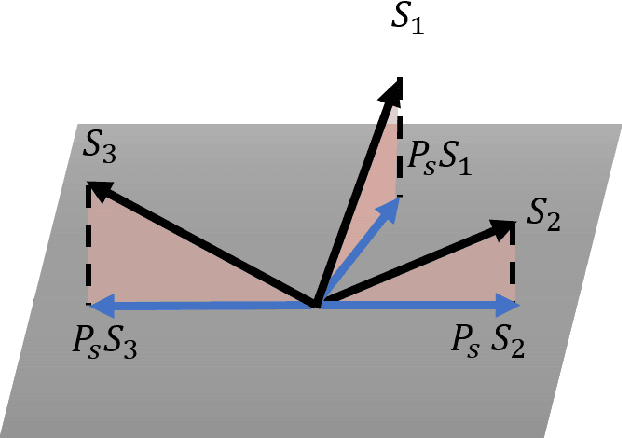
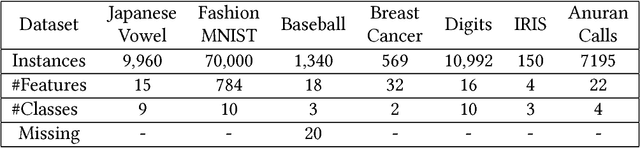
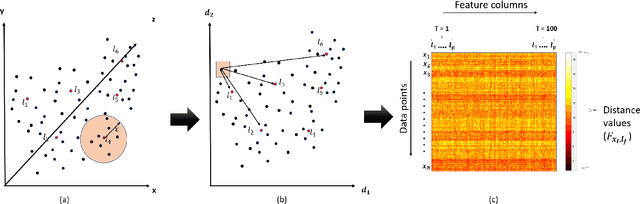
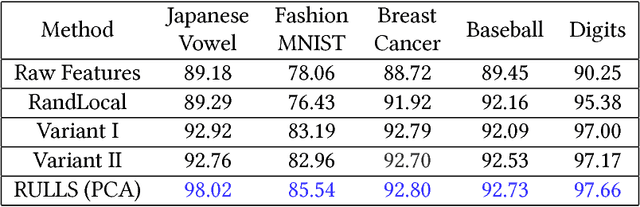
Feature engineering plays an important role in the success of a machine learning model. Most of the effort in training a model goes into data preparation and choosing the right representation. In this paper, we propose a robust feature engineering method, Randomized Union of Locally Linear Subspaces (RULLS). We generate sparse, non-negative, and rotation invariant features in an unsupervised fashion. RULLS aggregates features from a random union of subspaces by describing each point using globally chosen landmarks. These landmarks serve as anchor points for choosing subspaces. Our method provides a way to select features that are relevant in the neighborhood around these chosen landmarks. Distances from each data point to $k$ closest landmarks are encoded in the feature matrix. The final feature representation is a union of features from all chosen subspaces. The effectiveness of our algorithm is shown on various real-world datasets for tasks such as clustering and classification of raw data and in the presence of noise. We compare our method with existing feature generation methods. Results show a high performance of our method on both classification and clustering tasks.