 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocalized Uncertainty Attacks
Jun 17, 2021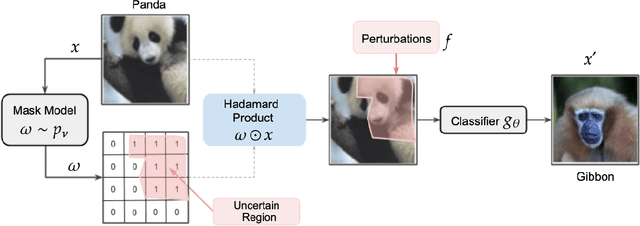
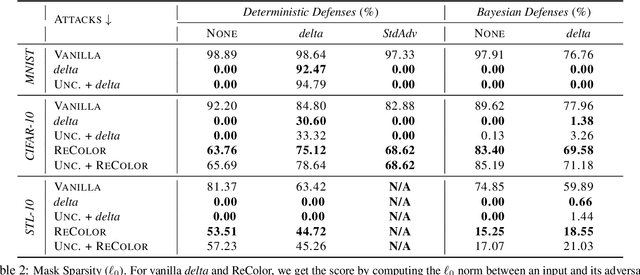
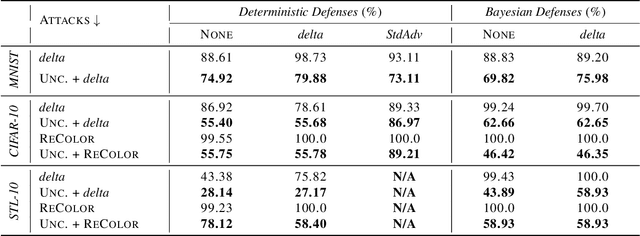

The susceptibility of deep learning models to adversarial perturbations has stirred renewed attention in adversarial examples resulting in a number of attacks. However, most of these attacks fail to encompass a large spectrum of adversarial perturbations that are imperceptible to humans. In this paper, we present localized uncertainty attacks, a novel class of threat models against deterministic and stochastic classifiers. Under this threat model, we create adversarial examples by perturbing only regions in the inputs where a classifier is uncertain. To find such regions, we utilize the predictive uncertainty of the classifier when the classifier is stochastic or, we learn a surrogate model to amortize the uncertainty when it is deterministic. Unlike $\ell_p$ ball or functional attacks which perturb inputs indiscriminately, our targeted changes can be less perceptible. When considered under our threat model, these attacks still produce strong adversarial examples; with the examples retaining a greater degree of similarity with the inputs.
Manifold Preserving Adversarial Learning
Mar 14, 2019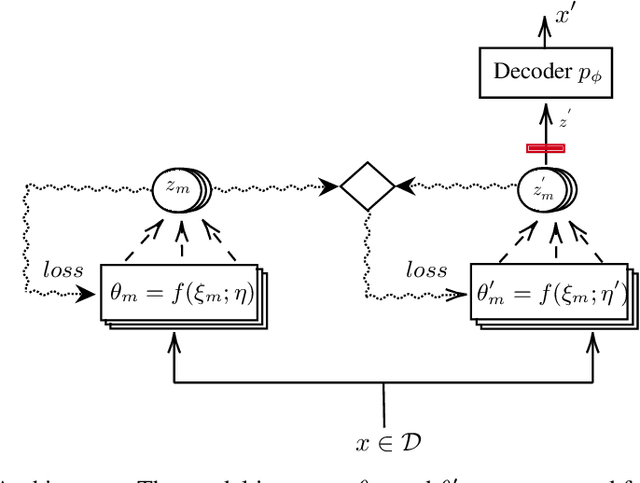



How to generate semantically meaningful and structurally sound adversarial examples? We propose to answer this question by restricting the search for adversaries in the true data manifold. To this end, we introduce a stochastic variational inference method to learn the data manifold, in the presence of continuous latent variables with intractable posterior distributions, without requiring an a priori form for the data underlying distribution. We then propose a manifold perturbation strategy that ensures the cases we perturb remain in the manifold of the original examples and thereby generate the adversaries. We evaluate our approach on a number of image and text datasets. Our results show the effectiveness of our approach in producing coherent, and realistic-looking adversaries that can evade strong defenses known to be resilient to traditional adversarial attacks