 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelatIF: Identifying Explanatory Training Examples via Relative Influence
Mar 25, 2020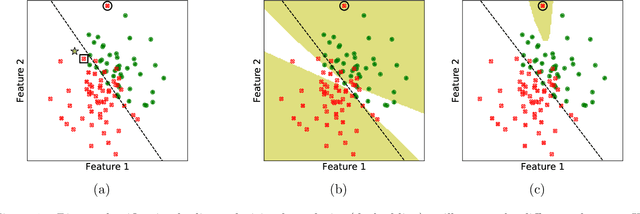
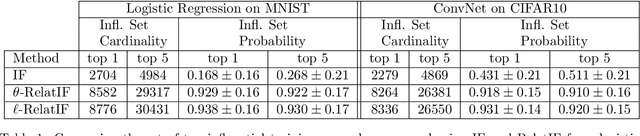
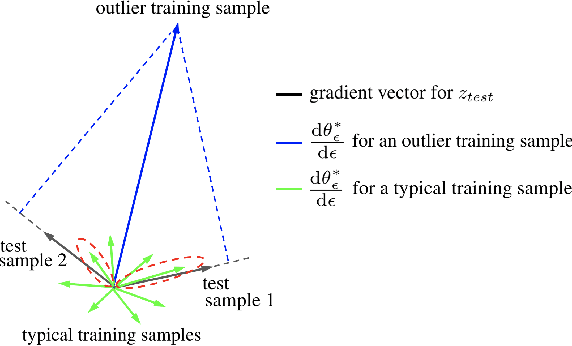
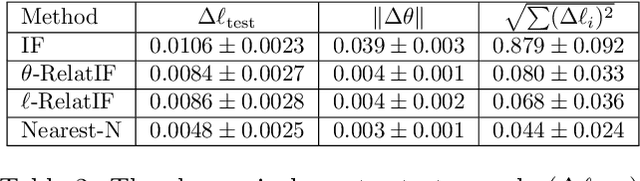
In this work, we focus on the use of influence functions to identify relevant training examples that one might hope "explain" the predictions of a machine learning model. One shortcoming of influence functions is that the training examples deemed most "influential" are often outliers or mislabelled, making them poor choices for explanation. In order to address this shortcoming, we separate the role of global versus local influence. We introduce RelatIF, a new class of criteria for choosing relevant training examples by way of an optimization objective that places a constraint on global influence. RelatIF considers the local influence that an explanatory example has on a prediction relative to its global effects on the model. In empirical evaluations, we find that the examples returned by RelatIF are more intuitive when compared to those found using influence functions.
Manifold Preserving Adversarial Learning
Mar 14, 2019



How to generate semantically meaningful and structurally sound adversarial examples? We propose to answer this question by restricting the search for adversaries in the true data manifold. To this end, we introduce a stochastic variational inference method to learn the data manifold, in the presence of continuous latent variables with intractable posterior distributions, without requiring an a priori form for the data underlying distribution. We then propose a manifold perturbation strategy that ensures the cases we perturb remain in the manifold of the original examples and thereby generate the adversaries. We evaluate our approach on a number of image and text datasets. Our results show the effectiveness of our approach in producing coherent, and realistic-looking adversaries that can evade strong defenses known to be resilient to traditional adversarial attacks
Evolution in Groups: A deeper look at synaptic cluster driven evolution of deep neural networks
Apr 07, 2017

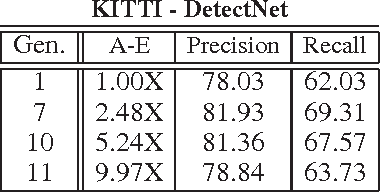

A promising paradigm for achieving highly efficient deep neural networks is the idea of evolutionary deep intelligence, which mimics biological evolution processes to progressively synthesize more efficient networks. A crucial design factor in evolutionary deep intelligence is the genetic encoding scheme used to simulate heredity and determine the architectures of offspring networks. In this study, we take a deeper look at the notion of synaptic cluster-driven evolution of deep neural networks which guides the evolution process towards the formation of a highly sparse set of synaptic clusters in offspring networks. Utilizing a synaptic cluster-driven genetic encoding, the probabilistic encoding of synaptic traits considers not only individual synaptic properties but also inter-synaptic relationships within a deep neural network. This process results in highly sparse offspring networks which are particularly tailored for parallel computational devices such as GPUs and deep neural network accelerator chips. Comprehensive experimental results using four well-known deep neural network architectures (LeNet-5, AlexNet, ResNet-56, and DetectNet) on two different tasks (object categorization and object detection) demonstrate the efficiency of the proposed method. Cluster-driven genetic encoding scheme synthesizes networks that can achieve state-of-the-art performance with significantly smaller number of synapses than that of the original ancestor network. ($\sim$125-fold decrease in synapses for MNIST). Furthermore, the improved cluster efficiency in the generated offspring networks ($\sim$9.71-fold decrease in clusters for MNIST and a $\sim$8.16-fold decrease in clusters for KITTI) is particularly useful for accelerated performance on parallel computing hardware architectures such as those in GPUs and deep neural network accelerator chips.