 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICL Markup: Structuring In-Context Learning using Soft-Token Tags
Dec 12, 2023Large pretrained language models (LLMs) can be rapidly adapted to a wide variety of tasks via a text-to-text approach, where the instruction and input are fed to the model in natural language. Combined with in-context learning (ICL), this paradigm is impressively flexible and powerful. However, it also burdens users with an overwhelming number of choices, many of them arbitrary. Inspired by markup languages like HTML, we contribute a method of using soft-token tags to compose prompt templates. This approach reduces arbitrary decisions and streamlines the application of ICL. Our method is a form of meta-learning for ICL; it learns these tags in advance during a parameter-efficient fine-tuning ``warm-up'' process. The tags can subsequently be used in templates for ICL on new, unseen tasks without any additional fine-tuning. Our experiments with this approach yield promising initial results, improving LLM performance on important enterprise applications such as few-shot and open-world intent detection, as well as text classification in news and legal domains.
RelatIF: Identifying Explanatory Training Examples via Relative Influence
Mar 25, 2020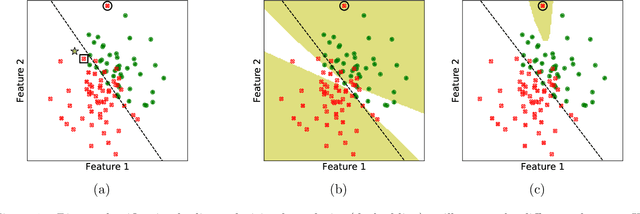
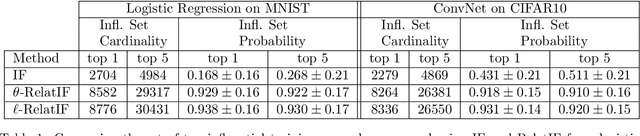
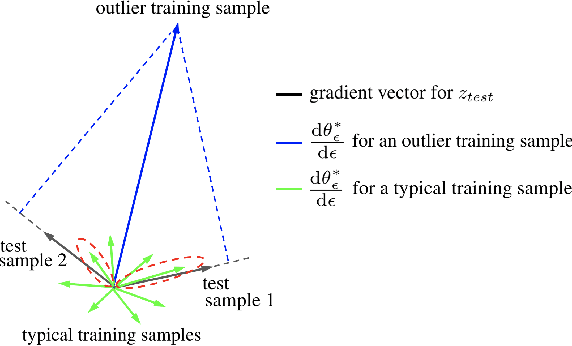
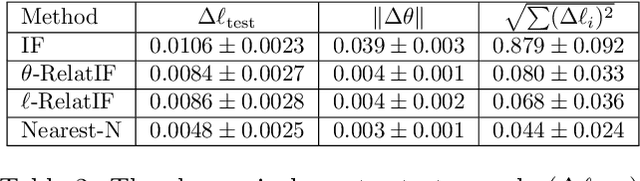
In this work, we focus on the use of influence functions to identify relevant training examples that one might hope "explain" the predictions of a machine learning model. One shortcoming of influence functions is that the training examples deemed most "influential" are often outliers or mislabelled, making them poor choices for explanation. In order to address this shortcoming, we separate the role of global versus local influence. We introduce RelatIF, a new class of criteria for choosing relevant training examples by way of an optimization objective that places a constraint on global influence. RelatIF considers the local influence that an explanatory example has on a prediction relative to its global effects on the model. In empirical evaluations, we find that the examples returned by RelatIF are more intuitive when compared to those found using influence functions.
Understanding the Origins of Bias in Word Embeddings
Oct 08, 2018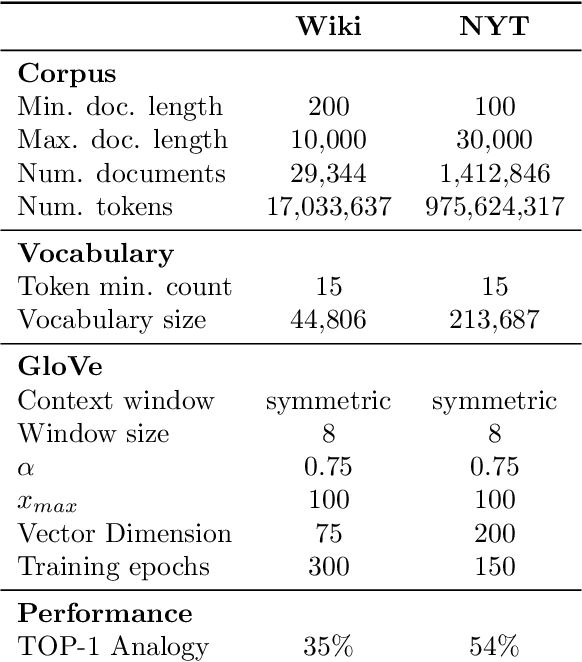
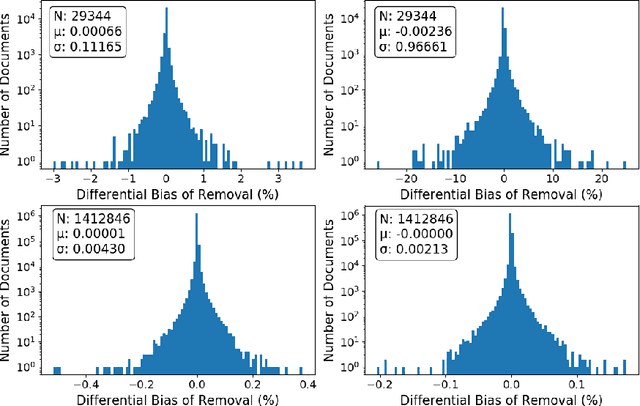
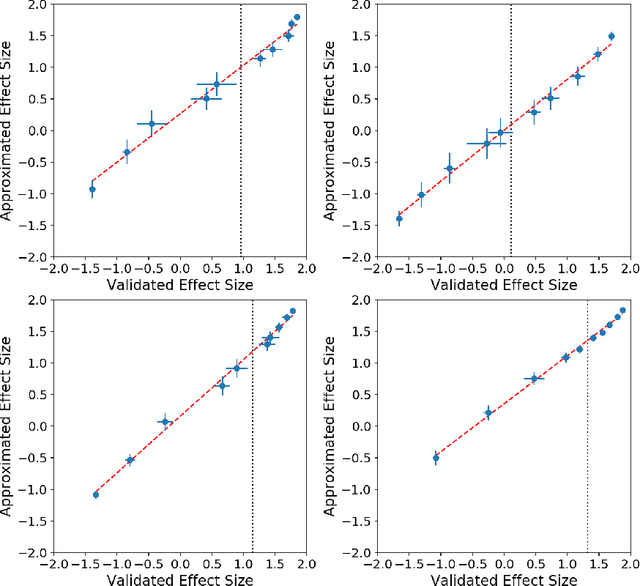
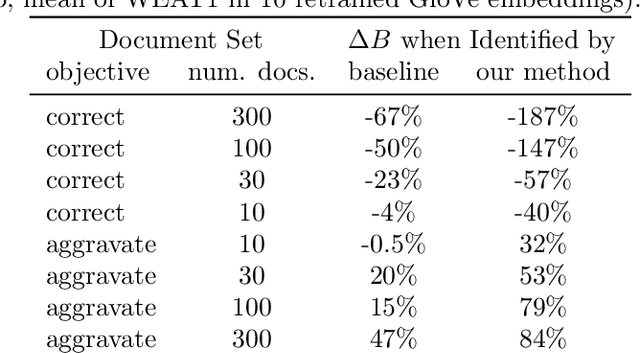
The power of machine learning systems not only promises great technical progress, but risks societal harm. As a recent example, researchers have shown that popular word embedding algorithms exhibit stereotypical biases, such as gender bias. The widespread use of these algorithms in machine learning systems, from automated translation services to curriculum vitae scanners, can amplify stereotypes in important contexts. Although methods have been developed to measure these biases and alter word embeddings to mitigate their biased representations, there is a lack of understanding in how word embedding bias depends on the training data. In this work, we develop a technique for understanding the origins of bias in word embeddings. Given a word embedding trained on a corpus, our method identifies how perturbing the corpus will affect the bias of the resulting embedding. This can be used to trace the origins of word embedding bias back to the original training documents. Using our method, one can investigate trends in the bias of the underlying corpus and identify subsets of documents whose removal would most reduce bias. We demonstrate our techniques on both a New York Times and Wikipedia corpus and find that our influence function-based approximations are extremely accurate.