 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Origins of Bias in Word Embeddings
Paper and Code
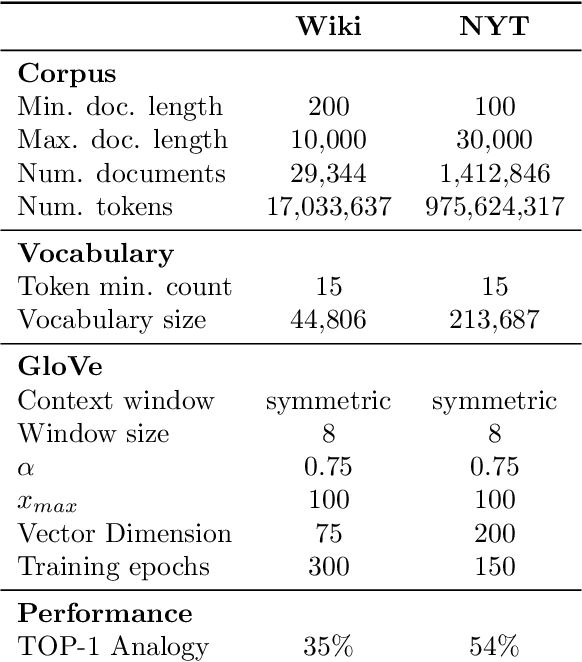
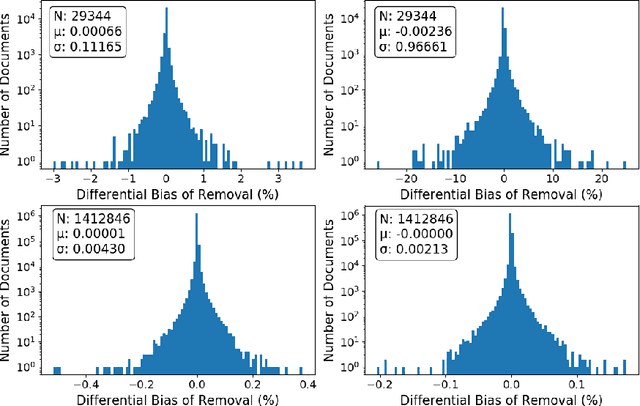
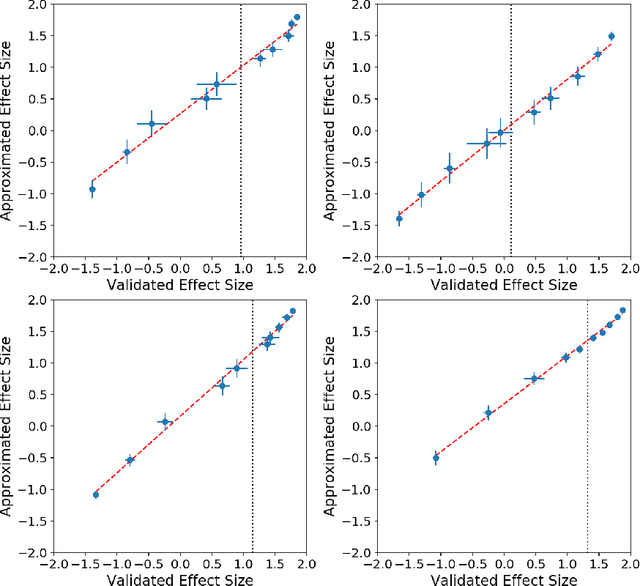
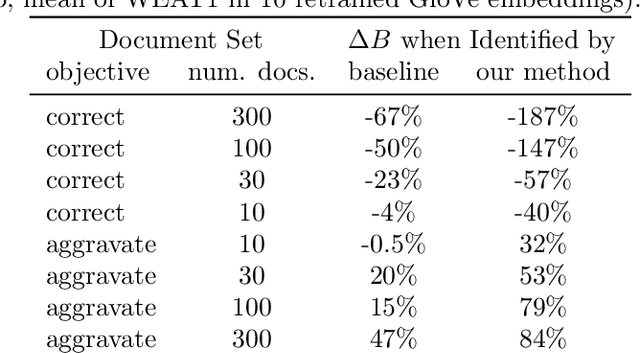
The power of machine learning systems not only promises great technical progress, but risks societal harm. As a recent example, researchers have shown that popular word embedding algorithms exhibit stereotypical biases, such as gender bias. The widespread use of these algorithms in machine learning systems, from automated translation services to curriculum vitae scanners, can amplify stereotypes in important contexts. Although methods have been developed to measure these biases and alter word embeddings to mitigate their biased representations, there is a lack of understanding in how word embedding bias depends on the training data. In this work, we develop a technique for understanding the origins of bias in word embeddings. Given a word embedding trained on a corpus, our method identifies how perturbing the corpus will affect the bias of the resulting embedding. This can be used to trace the origins of word embedding bias back to the original training documents. Using our method, one can investigate trends in the bias of the underlying corpus and identify subsets of documents whose removal would most reduce bias. We demonstrate our techniques on both a New York Times and Wikipedia corpus and find that our influence function-based approximations are extremely accurate.