 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFault Detection Using Nonlinear Low-Dimensional Representation of Sensor Data
Oct 02, 2019
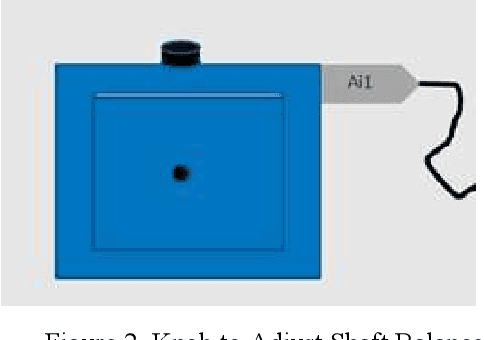
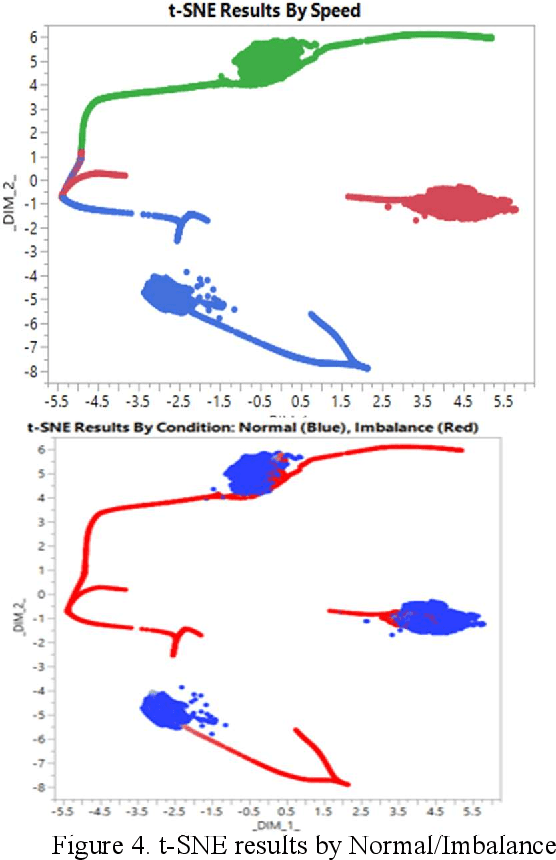
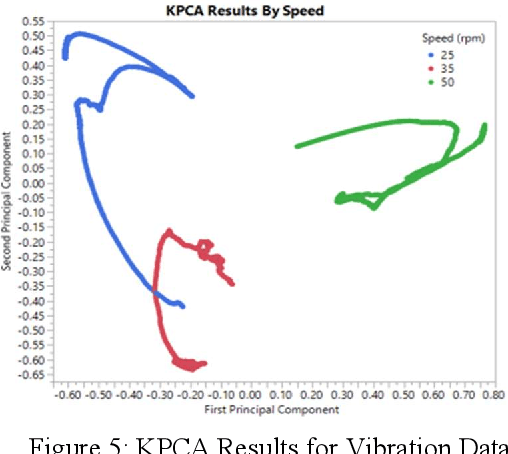
Sensor data analysis plays a key role in health assessment of critical equipment. Such data are multivariate and exhibit nonlinear relationships. This paper describes how one can exploit nonlinear dimension reduction techniques, such as the t-distributed stochastic neighbor embedding (t-SNE) and kernel principal component analysis (KPCA) for fault detection. We show that using anomaly detection with low dimensional representations provides better interpretability and is conducive to edge processing in IoT applications.
Automatic Hyperparameter Tuning Method for Local Outlier Factor, with Applications to Anomaly Detection
Feb 01, 2019
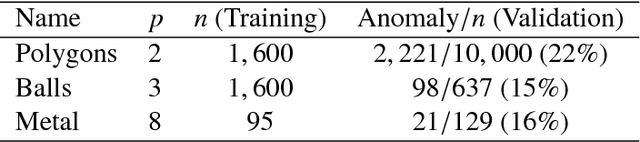
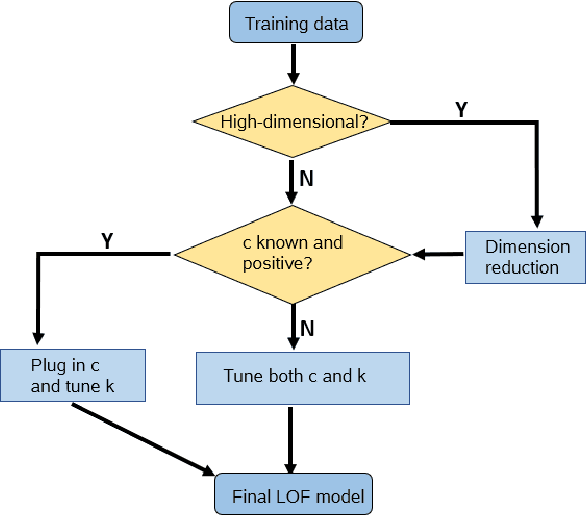
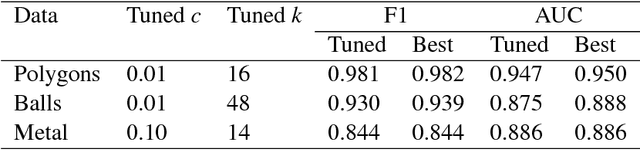
In recent years, there have been many practical applications of anomaly detection such as in predictive maintenance, detection of credit fraud, network intrusion, and system failure. The goal of anomaly detection is to identify in the test data anomalous behaviors that are either rare or unseen in the training data. This is a common goal in predictive maintenance, which aims to forecast the imminent faults of an appliance given abundant samples of normal behaviors. Local outlier factor (LOF) is one of the state-of-the-art models used for anomaly detection, but the predictive performance of LOF depends greatly on the selection of hyperparameters. In this paper, we propose a novel, heuristic methodology to tune the hyperparameters in LOF. A tuned LOF model that uses the proposed method shows good predictive performance in both simulations and real data sets.
The Trace Criterion for Kernel Bandwidth Selection for Support Vector Data Description
Nov 15, 2018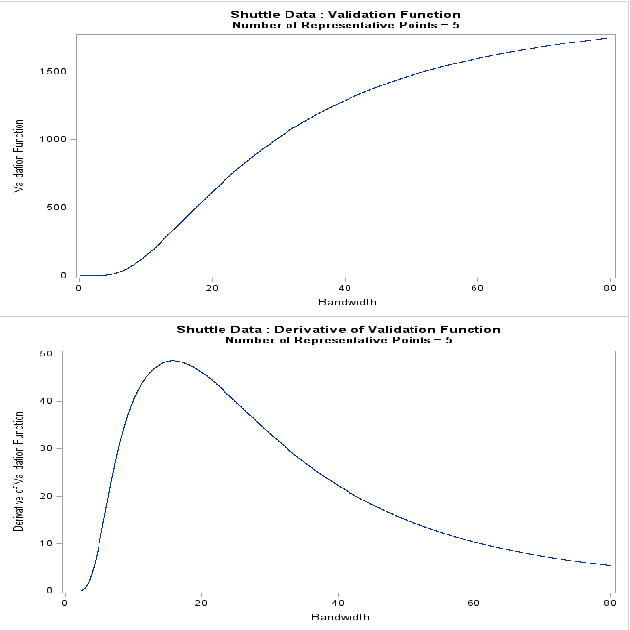
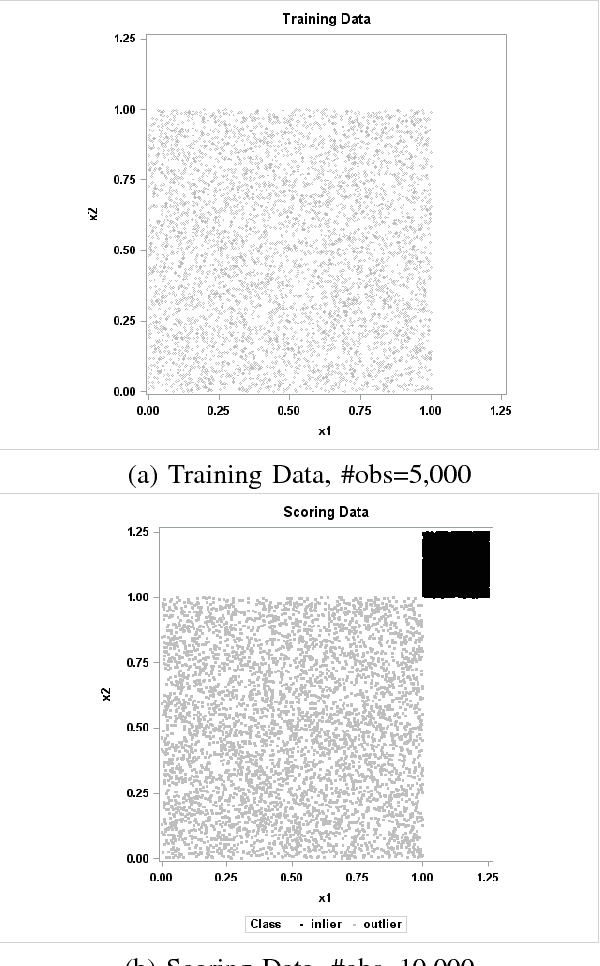
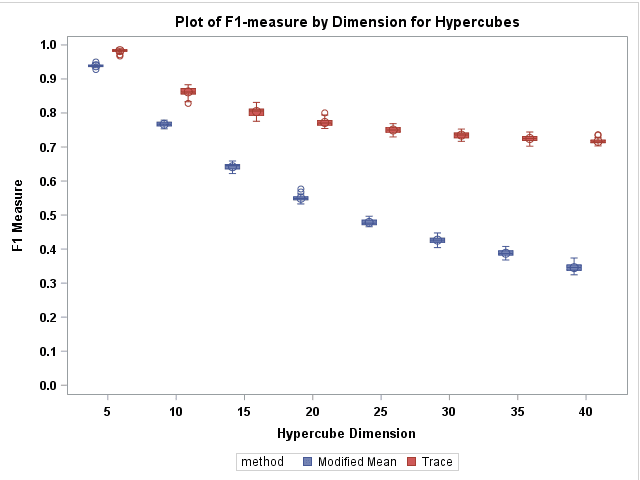
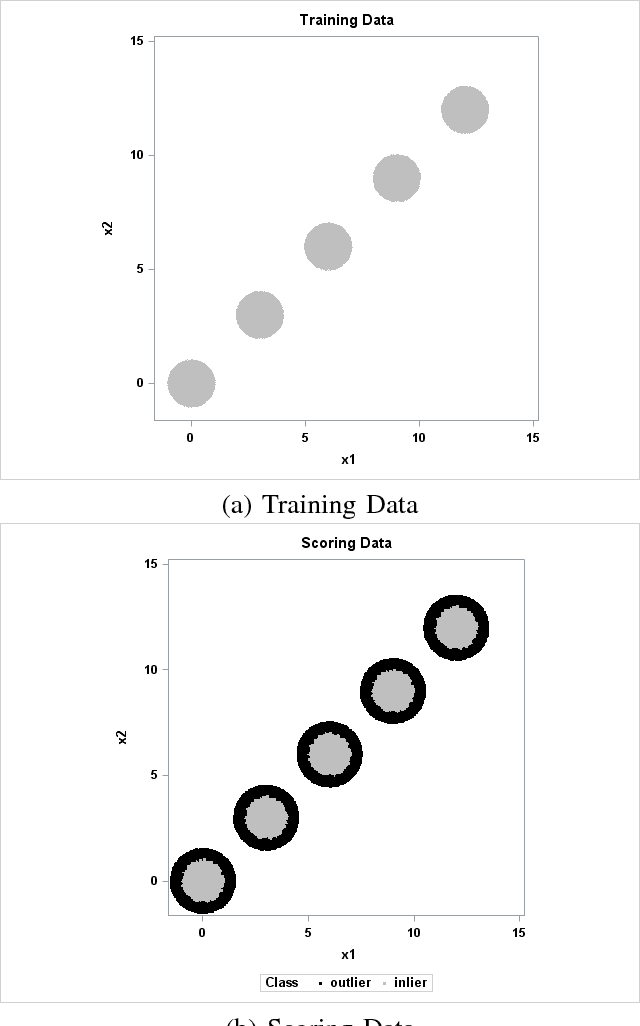
Support vector data description (SVDD) is a popular anomaly detection technique. The SVDD classifier partitions the whole data space into an $\textit{inlier}$ region, which consists of the region $\textit{near}$ the training data, and an $\textit{outlier}$ region, which consists of points $\textit{away}$ from the training data. The computation of the SVDD classifier requires a kernel function, for which the Gaussian kernel is a common choice. The Gaussian kernel has a bandwidth parameter, and it is important to set the value of this parameter correctly for good results. A small bandwidth leads to overfitting such that the resulting SVDD classifier overestimates the number of anomalies, whereas a large bandwidth leads to underfitting and an inability to detect many anomalies. In this paper, we present a new unsupervised method for selecting the Gaussian kernel bandwidth. Our method, which exploits the low-rank representation of the kernel matrix to suggest a kernel bandwidth value, is competitive with existing bandwidth selection methods.
A New SVDD-Based Multivariate Non-parametric Process Capability Index
Nov 13, 2018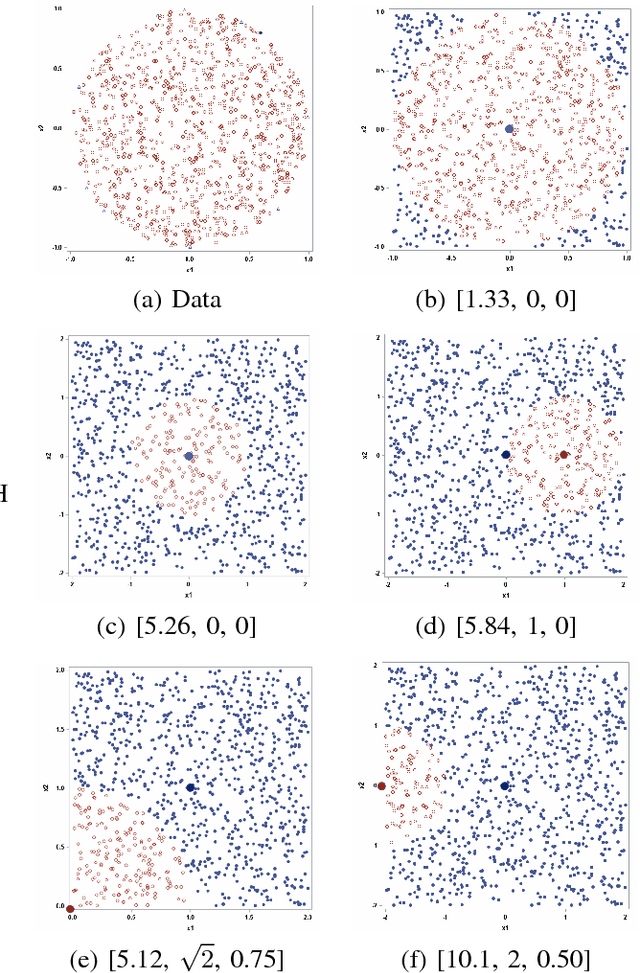
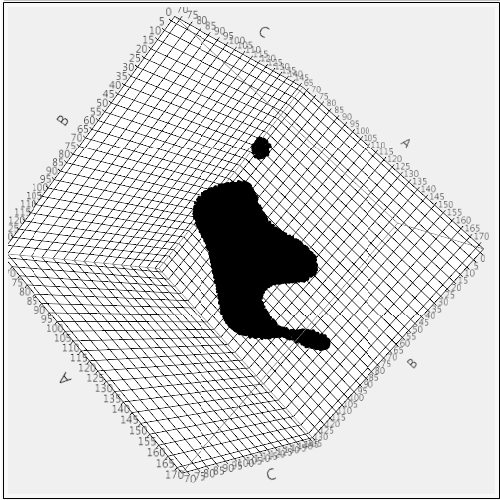
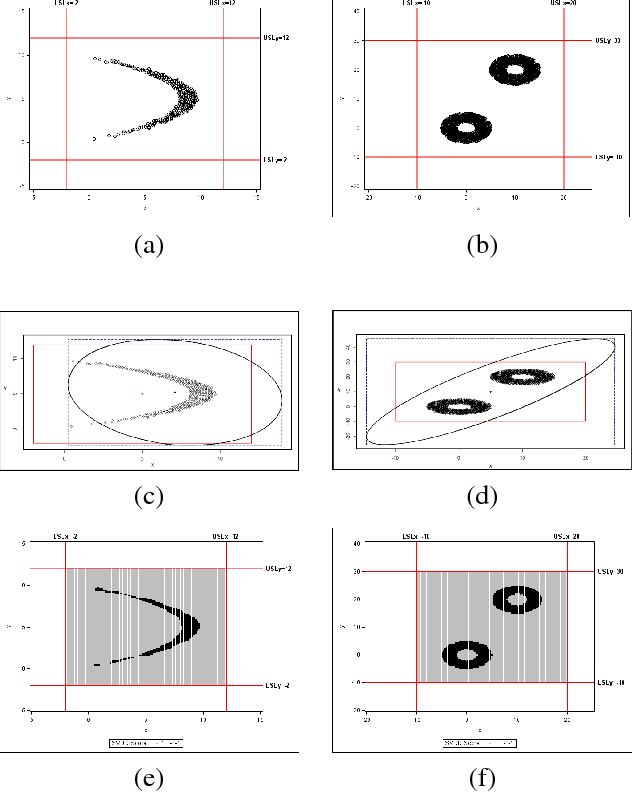
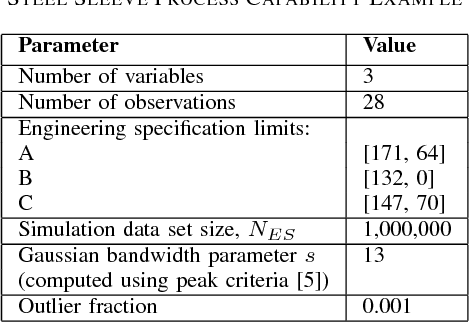
Process capability index (PCI) is a commonly used statistic to measure ability of a process to operate within the given specifications or to produce products which meet the required quality specifications. PCI can be univariate or multivariate depending upon the number of process specifications or quality characteristics of interest. Most PCIs make distributional assumptions which are often unrealistic in practice. This paper proposes a new multivariate non-parametric process capability index. This index can be used when distribution of the process or quality parameters is either unknown or does not follow commonly used distributions such as multivariate normal.
The Mean and Median Criterion for Automatic Kernel Bandwidth Selection for Support Vector Data Description
Aug 21, 2017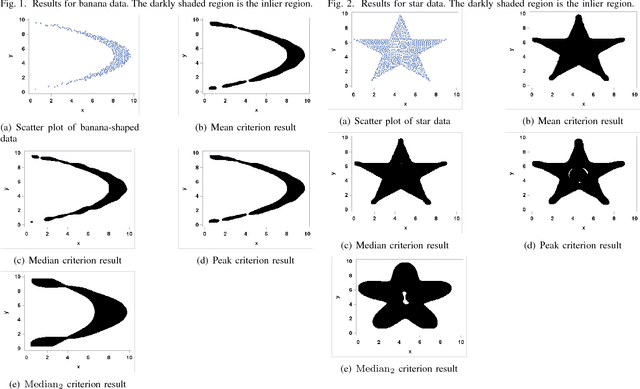
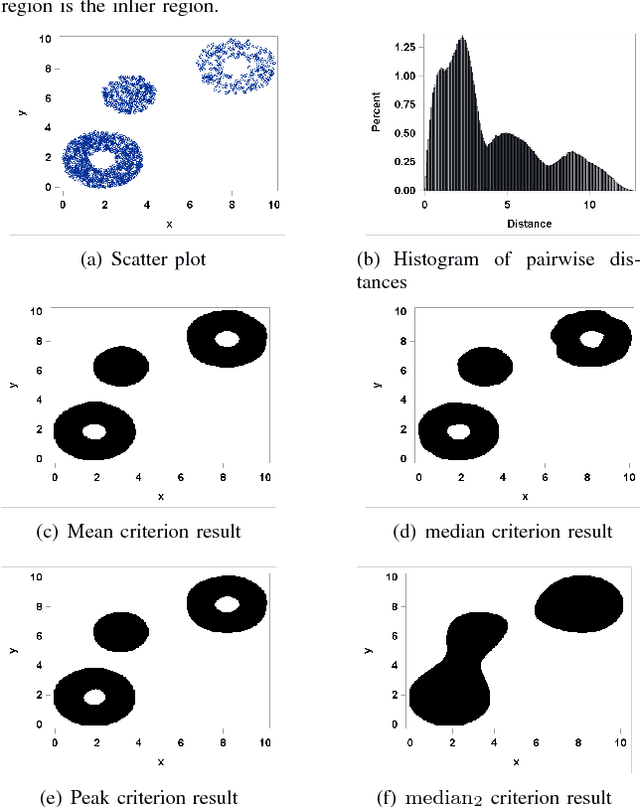
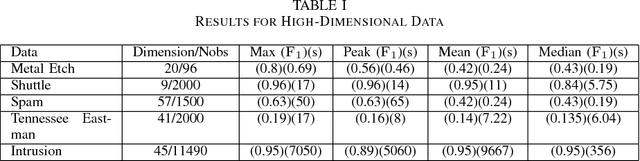
Support vector data description (SVDD) is a popular technique for detecting anomalies. The SVDD classifier partitions the whole space into an inlier region, which consists of the region near the training data, and an outlier region, which consists of points away from the training data. The computation of the SVDD classifier requires a kernel function, and the Gaussian kernel is a common choice for the kernel function. The Gaussian kernel has a bandwidth parameter, whose value is important for good results. A small bandwidth leads to overfitting, and the resulting SVDD classifier overestimates the number of anomalies. A large bandwidth leads to underfitting, and the classifier fails to detect many anomalies. In this paper we present a new automatic, unsupervised method for selecting the Gaussian kernel bandwidth. The selected value can be computed quickly, and it is competitive with existing bandwidth selection methods.
Peak Criterion for Choosing Gaussian Kernel Bandwidth in Support Vector Data Description
Aug 08, 2017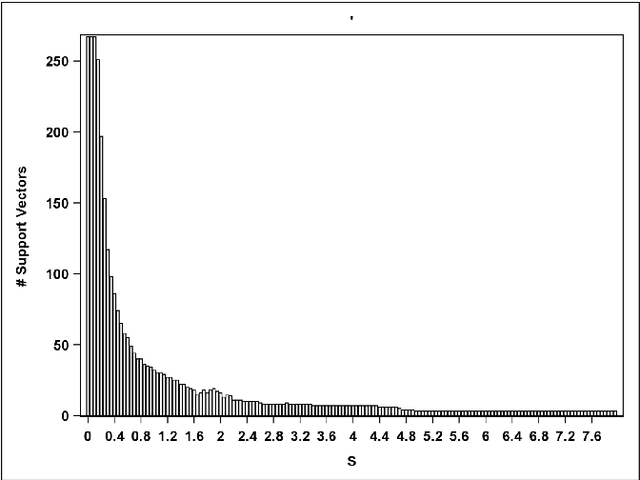

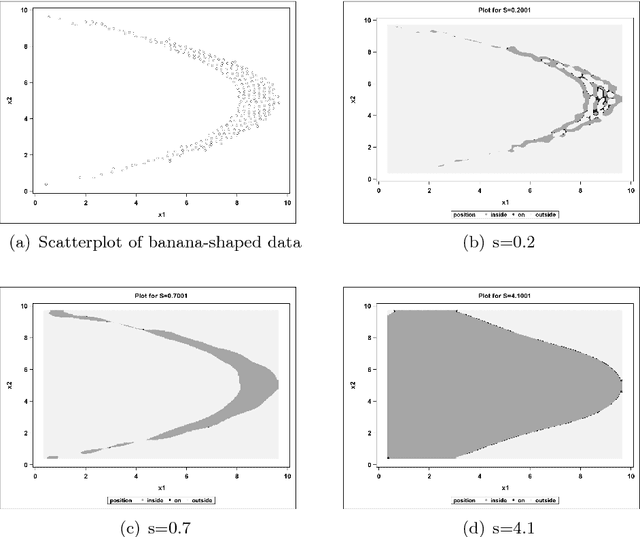
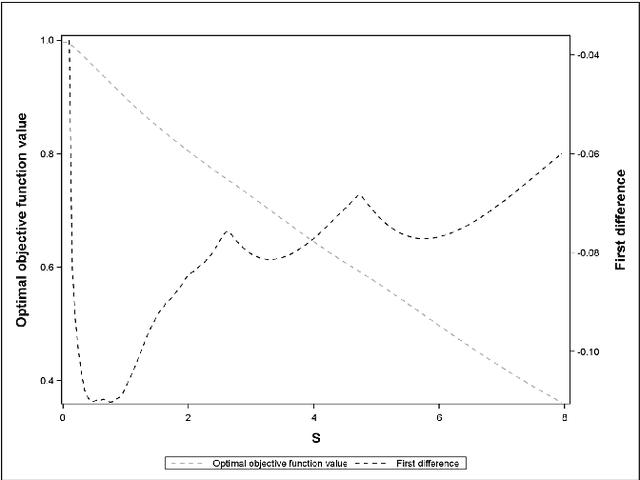
Support Vector Data Description (SVDD) is a machine-learning technique used for single class classification and outlier detection. SVDD formulation with kernel function provides a flexible boundary around data. The value of kernel function parameters affects the nature of the data boundary. For example, it is observed that with a Gaussian kernel, as the value of kernel bandwidth is lowered, the data boundary changes from spherical to wiggly. The spherical data boundary leads to underfitting, and an extremely wiggly data boundary leads to overfitting. In this paper, we propose empirical criterion to obtain good values of the Gaussian kernel bandwidth parameter. This criterion provides a smooth boundary that captures the essential geometric features of the data.
Kernel Bandwidth Selection for SVDD: Peak Criterion Approach for Large Data
May 19, 2017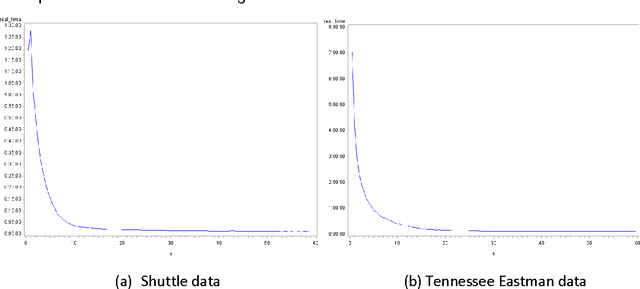

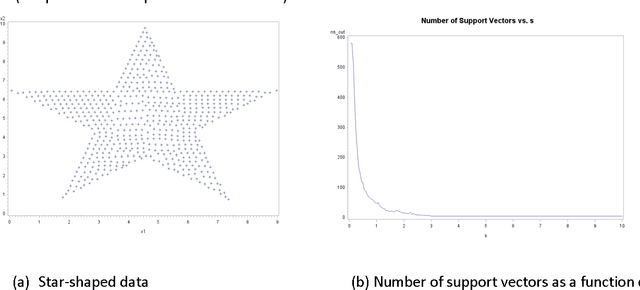
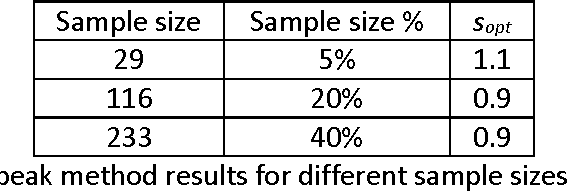
Support Vector Data Description (SVDD) provides a useful approach to construct a description of multivariate data for single-class classification and outlier detection with various practical applications. Gaussian kernel used in SVDD formulation allows flexible data description defined by observations designated as support vectors. The data boundary of such description is non-spherical and conforms to the geometric features of the data. By varying the Gaussian kernel bandwidth parameter, the SVDD-generated boundary can be made either smoother (more spherical) or tighter/jagged. The former case may lead to under-fitting, whereas the latter may result in overfitting. Peak criterion has been proposed to select an optimal value of the kernel bandwidth to strike the balance between the data boundary smoothness and its ability to capture the general geometric shape of the data. Peak criterion involves training SVDD at various values of the kernel bandwidth parameter. When training datasets are large, the time required to obtain the optimal value of the Gaussian kernel bandwidth parameter according to Peak method can become prohibitively large. This paper proposes an extension of Peak method for the case of large data. The proposed method gives good results when applied to several datasets. Two existing alternative methods of computing the Gaussian kernel bandwidth parameter (Coefficient of Variation and Distance to the Farthest Neighbor) were modified to allow comparison with the proposed method on convergence. Empirical comparison demonstrates the advantage of the proposed method.
Sampling Method for Fast Training of Support Vector Data Description
Sep 25, 2016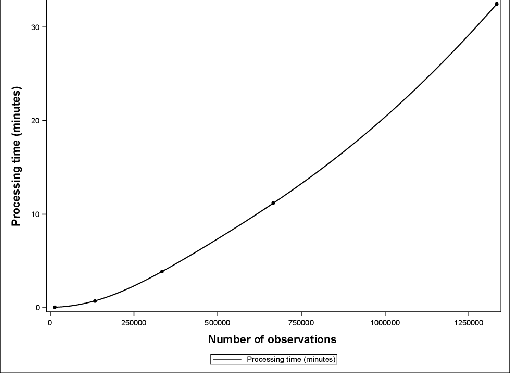
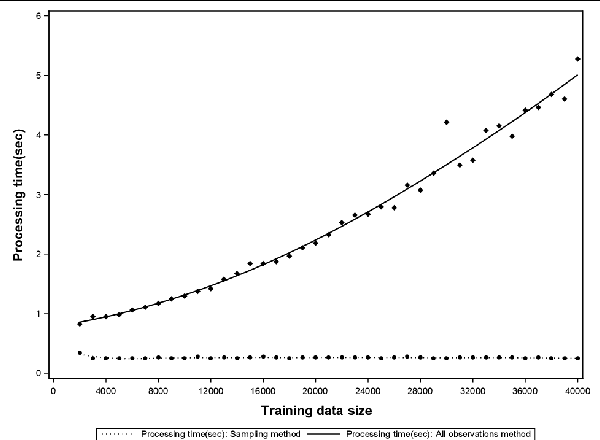
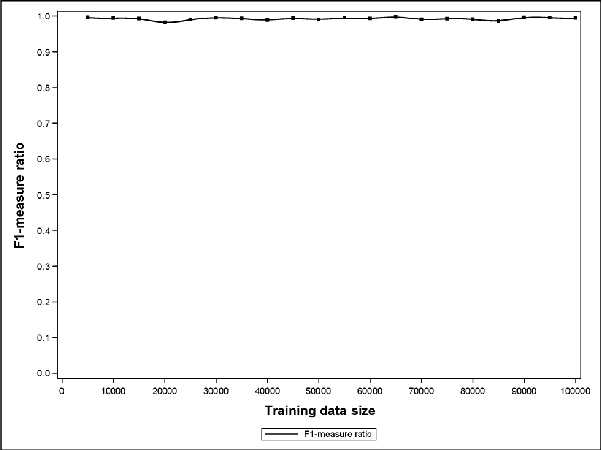
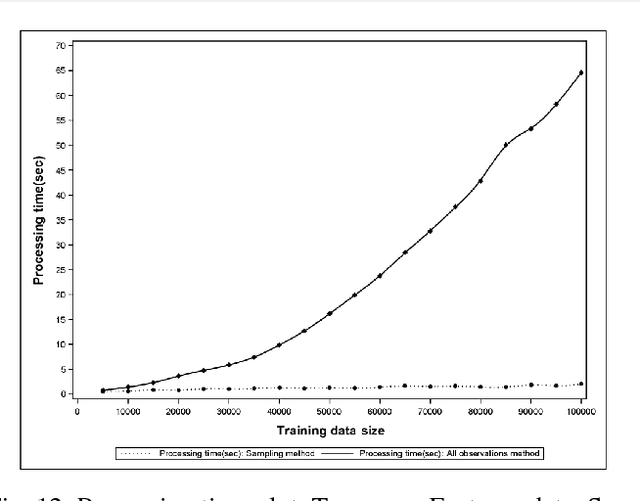
Support Vector Data Description (SVDD) is a popular outlier detection technique which constructs a flexible description of the input data. SVDD computation time is high for large training datasets which limits its use in big-data process-monitoring applications. We propose a new iterative sampling-based method for SVDD training. The method incrementally learns the training data description at each iteration by computing SVDD on an independent random sample selected with replacement from the training data set. The experimental results indicate that the proposed method is extremely fast and provides a good data description .
A Non-Parametric Control Chart For High Frequency Multivariate Data
Jul 29, 2016

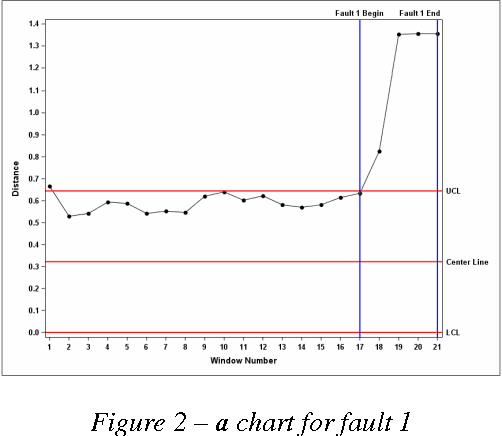
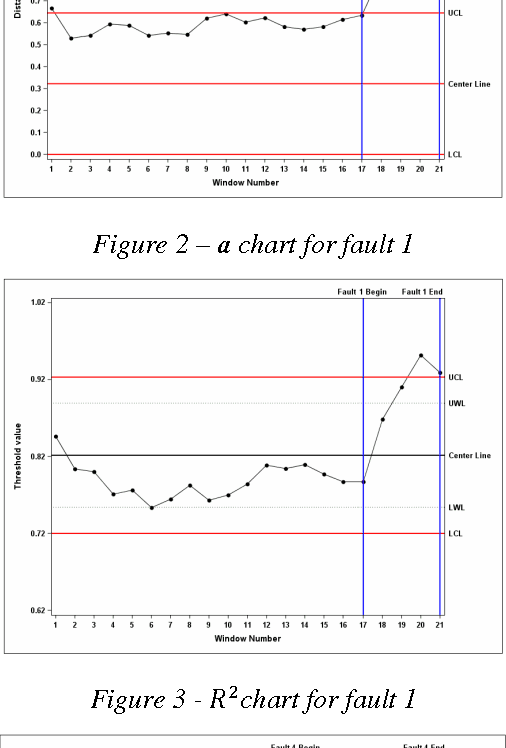
Support Vector Data Description (SVDD) is a machine learning technique used for single class classification and outlier detection. SVDD based K-chart was first introduced by Sun and Tsung for monitoring multivariate processes when underlying distribution of process parameters or quality characteristics depart from Normality. The method first trains a SVDD model on data obtained from stable or in-control operations of the process to obtain a threshold $R^2$ and kernel center a. For each new observation, its Kernel distance from the Kernel center a is calculated. The kernel distance is compared against the threshold $R^2$ to determine if the observation is within the control limits. The non-parametric K-chart provides an attractive alternative to the traditional control charts such as the Hotelling's $T^2$ charts when distribution of the underlying multivariate data is either non-normal or is unknown. But there are challenges when K-chart is deployed in practice. The K-chart requires calculating kernel distance of each new observation but there are no guidelines on how to interpret the kernel distance plot and infer about shifts in process mean or changes in process variation. This limits the application of K-charts in big-data applications such as equipment health monitoring, where observations are generated at a very high frequency. In this scenario, the analyst using the K-chart is inundated with kernel distance results at a very high frequency, generally without any recourse for detecting presence of any assignable causes of variation. We propose a new SVDD based control chart, called as $K_T$ chart, which addresses challenges encountered when using K-chart for big-data applications. The $K_T$ charts can be used to simultaneously track process variation and central tendency. We illustrate the successful use of $K_T$ chart using the Tennessee Eastman process data.
Leveraging Unstructured Data to Detect Emerging Reliability Issues
Jul 26, 2016
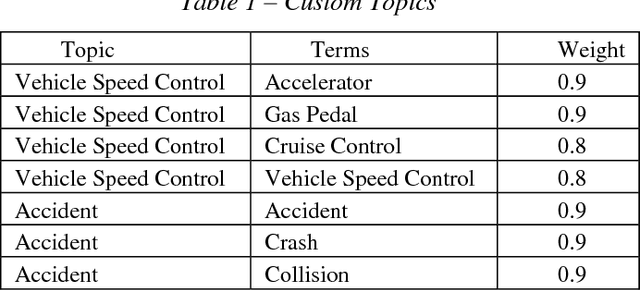
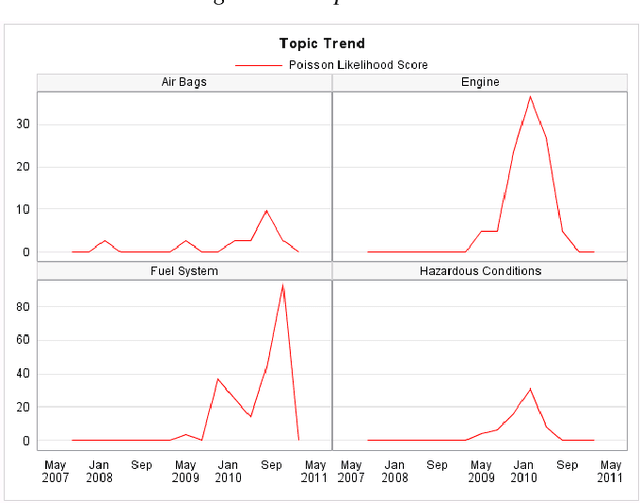
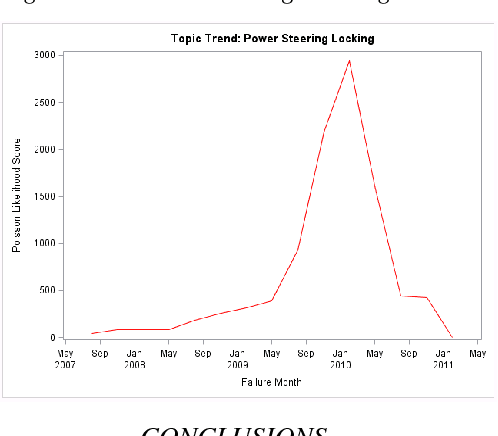
Unstructured data refers to information that does not have a predefined data model or is not organized in a pre-defined manner. Loosely speaking, unstructured data refers to text data that is generated by humans. In after-sales service businesses, there are two main sources of unstructured data: customer complaints, which generally describe symptoms, and technician comments, which outline diagnostics and treatment information. A legitimate customer complaint can eventually be tracked to a failure or a claim. However, there is a delay between the time of a customer complaint and the time of a failure or a claim. A proactive strategy aimed at analyzing customer complaints for symptoms can help service providers detect reliability problems in advance and initiate corrective actions such as recalls. This paper introduces essential text mining concepts in the context of reliability analysis and a method to detect emerging reliability issues. The application of the method is illustrated using a case study.