 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Trace Criterion for Kernel Bandwidth Selection for Support Vector Data Description
Nov 15, 2018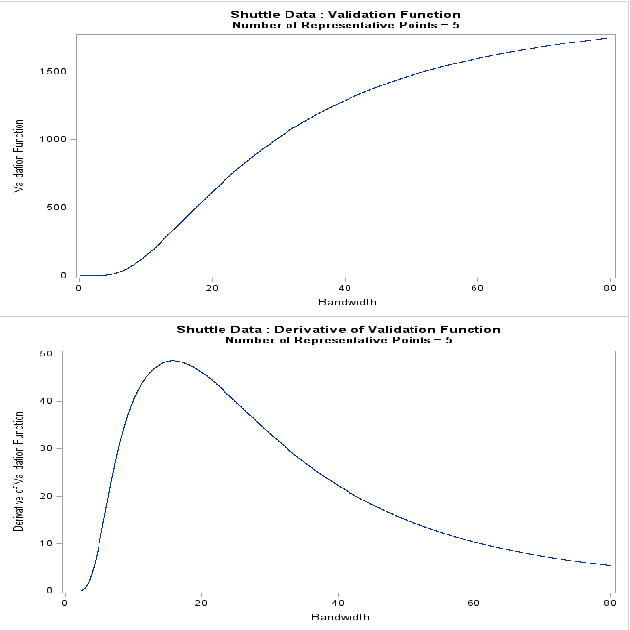
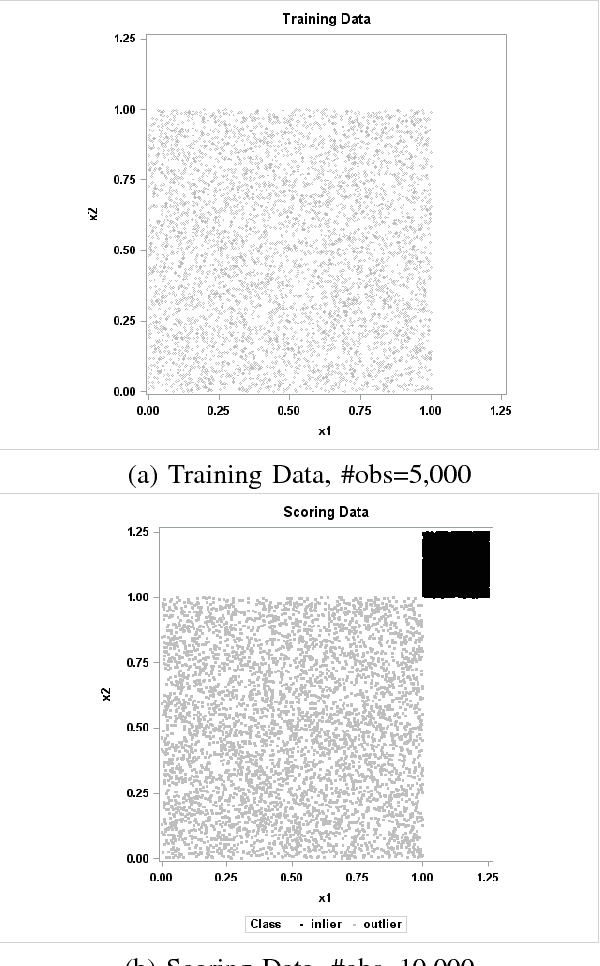
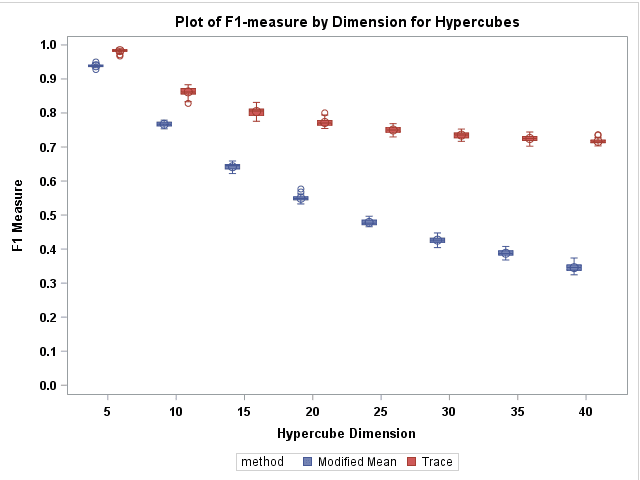
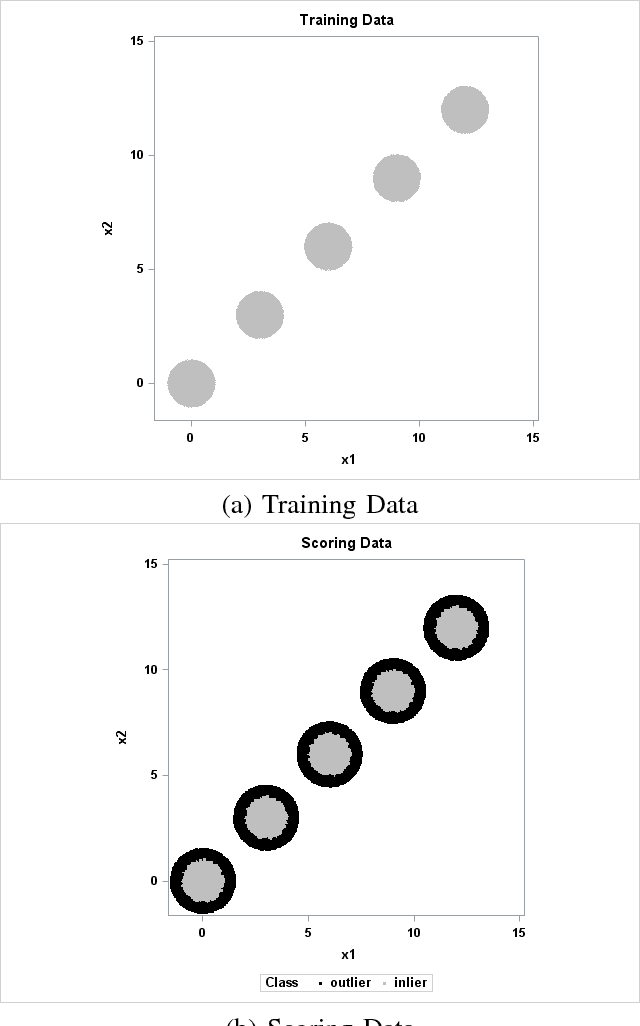
Support vector data description (SVDD) is a popular anomaly detection technique. The SVDD classifier partitions the whole data space into an $\textit{inlier}$ region, which consists of the region $\textit{near}$ the training data, and an $\textit{outlier}$ region, which consists of points $\textit{away}$ from the training data. The computation of the SVDD classifier requires a kernel function, for which the Gaussian kernel is a common choice. The Gaussian kernel has a bandwidth parameter, and it is important to set the value of this parameter correctly for good results. A small bandwidth leads to overfitting such that the resulting SVDD classifier overestimates the number of anomalies, whereas a large bandwidth leads to underfitting and an inability to detect many anomalies. In this paper, we present a new unsupervised method for selecting the Gaussian kernel bandwidth. Our method, which exploits the low-rank representation of the kernel matrix to suggest a kernel bandwidth value, is competitive with existing bandwidth selection methods.
Kernel Bandwidth Selection for SVDD: Peak Criterion Approach for Large Data
May 19, 2017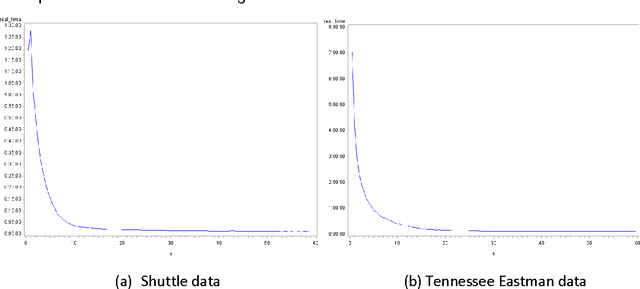

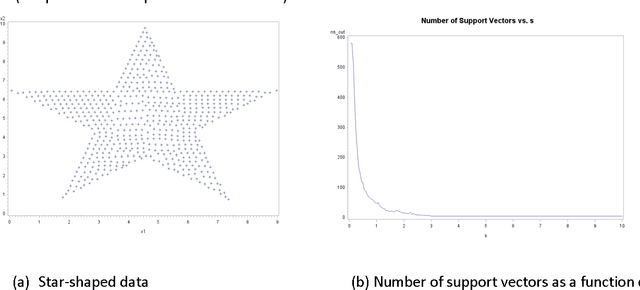
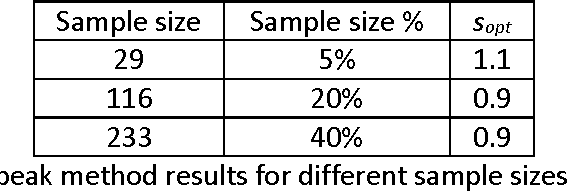
Support Vector Data Description (SVDD) provides a useful approach to construct a description of multivariate data for single-class classification and outlier detection with various practical applications. Gaussian kernel used in SVDD formulation allows flexible data description defined by observations designated as support vectors. The data boundary of such description is non-spherical and conforms to the geometric features of the data. By varying the Gaussian kernel bandwidth parameter, the SVDD-generated boundary can be made either smoother (more spherical) or tighter/jagged. The former case may lead to under-fitting, whereas the latter may result in overfitting. Peak criterion has been proposed to select an optimal value of the kernel bandwidth to strike the balance between the data boundary smoothness and its ability to capture the general geometric shape of the data. Peak criterion involves training SVDD at various values of the kernel bandwidth parameter. When training datasets are large, the time required to obtain the optimal value of the Gaussian kernel bandwidth parameter according to Peak method can become prohibitively large. This paper proposes an extension of Peak method for the case of large data. The proposed method gives good results when applied to several datasets. Two existing alternative methods of computing the Gaussian kernel bandwidth parameter (Coefficient of Variation and Distance to the Farthest Neighbor) were modified to allow comparison with the proposed method on convergence. Empirical comparison demonstrates the advantage of the proposed method.
Sampling Method for Fast Training of Support Vector Data Description
Sep 25, 2016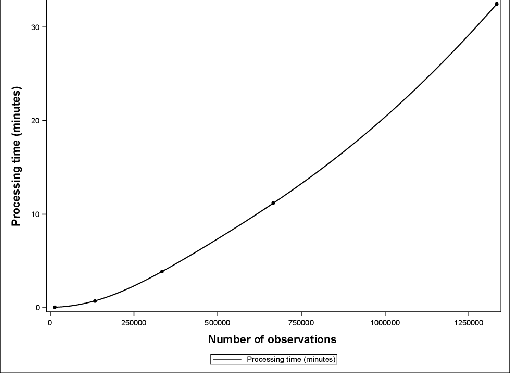
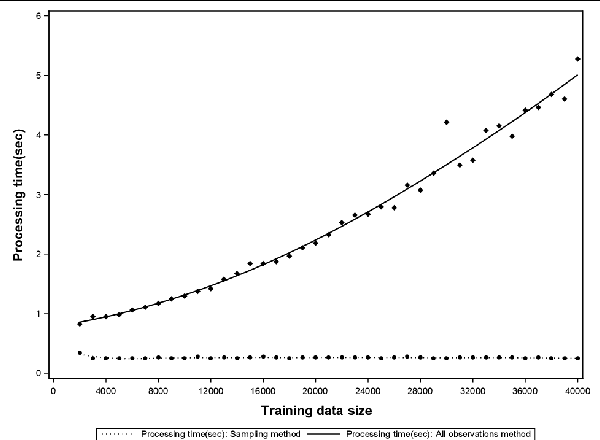
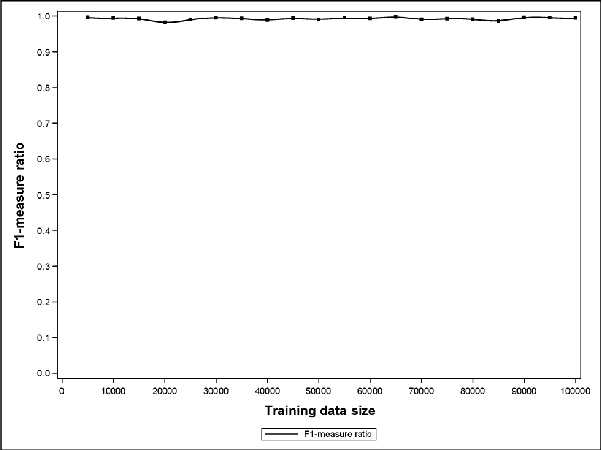
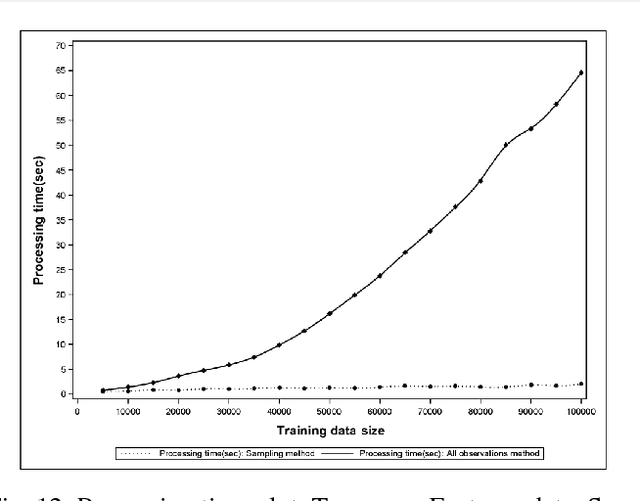
Support Vector Data Description (SVDD) is a popular outlier detection technique which constructs a flexible description of the input data. SVDD computation time is high for large training datasets which limits its use in big-data process-monitoring applications. We propose a new iterative sampling-based method for SVDD training. The method incrementally learns the training data description at each iteration by computing SVDD on an independent random sample selected with replacement from the training data set. The experimental results indicate that the proposed method is extremely fast and provides a good data description .