 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Learning for Knee Osteoarthritis: Diagnostic Limitations and Prognostic Value of Uncurated Hospital Data
Mar 26, 2026This study assesses whether self-supervised learning (SSL) improves knee osteoarthritis (OA) modeling for diagnosis and prognosis relative to ImageNet-pretrained initialization. We compared (i) image-only SSL pretrained on knee radiographs from the OAI, MOST, and NYU cohorts, and (ii) multimodal image-text SSL pretrained on uncurated hospital knee radiographs paired with radiologist impressions. For diagnostic Kellgren-Lawrence (KL) grade prediction, SSL offered mixed results. While image-only SSL improved accuracy during linear probing (frozen encoder), it did not outperform ImageNet pretraining during full fine-tuning. Similarly, multimodal SSL failed to improve grading performance. We attribute this to severe bias in the uncurated hospital pretraining corpus (93% estimated KL grade 3), which limited alignment with the balanced diagnostic task. In contrast, this same multimodal initialization significantly improved prognostic modeling. It outperformed ImageNet baselines in predicting 4-year structural incidence and progression, including on external validation (MOST AUROC: 0.701 vs. 0.599 at 10% labeled data). Overall, while uncurated hospital image-text data may be ineffective for learning diagnosis due to severity bias, it provides a strong signal for prognostic modeling when the downstream task aligns with pretraining data distribution
Scaling Recurrence-aware Foundation Models for Clinical Records via Next-Visit Prediction
Mar 25, 2026While large-scale pretraining has revolutionized language modeling, its potential remains underexplored in healthcare with structured electronic health records (EHRs). We present RAVEN, a novel generative pretraining strategy for sequential EHR data based on Recurrence-Aware next-Visit EveNt prediction. Leveraging a dataset of over one million unique individuals, our model learns to autoregressively generate tokenized clinical events for the next visit conditioned on patient history. We introduce regularization on predicting repeated events and highlight a key pitfall in EHR-based foundation model evaluations: repeated event tokens can inflate performance metrics when new onsets are not distinguished from subsequent occurrences. Furthermore, we empirically investigate the scaling behaviors in a data-constrained, compute-saturated regime, showing that simply increasing model size is suboptimal without commensurate increases in data volume. We evaluate our model via zero-shot prediction for forecasting the incidence of a diverse set of diseases, where it rivals fully fine-tuned representation-based Transformer models and outperforms widely used simulation-based next-token approaches. Finally, without additional parameter updates, we show that RAVEN can generalize to an external patient cohort under lossy clinical code mappings and feature coverage gaps.
Modified Risk Formulation for Improving the Prediction of Knee Osteoarthritis Progression
Jun 14, 2024Current methods for predicting osteoarthritis (OA) outcomes do not incorporate disease specific prior knowledge to improve the outcome prediction models. We developed a novel approach that effectively uses consecutive imaging studies to improve OA outcome predictions by incorporating an OA severity constraint. This constraint ensures that the risk of OA for a knee should either increase or remain the same over time. DL models were trained to predict TKR within multiple time periods (1 year, 2 years, and 4 years) using knee radiographs and MRI scans. Models with and without the risk constraint were evaluated using the area under the receiver operator curve (AUROC) and the area under the precision recall curve (AUPRC) analysis. The novel RiskFORM2 method, leveraging a dual model risk constraint architecture, demonstrated superior performance, yielding an AUROC of 0.87 and AUPRC of 0.47 for 1 year TKR prediction on the OAI radiograph test set, a marked improvement over the 0.79 AUROC and 0.34 AUPRC of the baseline approach. The performance advantage extended to longer followup periods, with RiskFORM2 maintaining a high AUROC of 0.86 and AUPRC of 0.75 in predicting TKR within 4 years. Additionally, when generalizing to the external MOST radiograph test set, RiskFORM2 generalized better with an AUROC of 0.77 and AUPRC of 0.25 for 1 year predictions, which was higher than the 0.71 AUROC and 0.19 AUPRC of the baseline approach. In the MRI test sets, similar patterns emerged, with RiskFORM2 outperforming the baseline approach consistently. However, RiskFORM1 exhibited the highest AUROC of 0.86 and AUPRC of 0.72 for 4 year predictions on the OAI set.
MR-Transformer: Vision Transformer for Total Knee Replacement Prediction Using Magnetic Resonance Imaging
May 05, 2024



A transformer-based deep learning model, MR-Transformer, was developed for total knee replacement (TKR) prediction using magnetic resonance imaging (MRI). The model incorporates the ImageNet pre-training and captures three-dimensional (3D) spatial correlation from the MR images. The performance of the proposed model was compared to existing state-of-the-art deep learning models for knee injury diagnosis using MRI. Knee MR scans of four different tissue contrasts from the Osteoarthritis Initiative and Multicenter Osteoarthritis Study databases were utilized in the study. Experimental results demonstrated the state-of-the-art performance of the proposed model on TKR prediction using MRI.
Sequence-to-Sequence Modeling for Action Identification at High Temporal Resolution
Nov 03, 2021

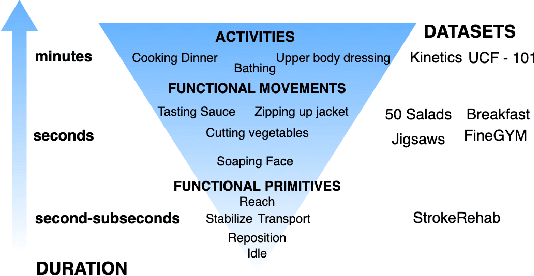
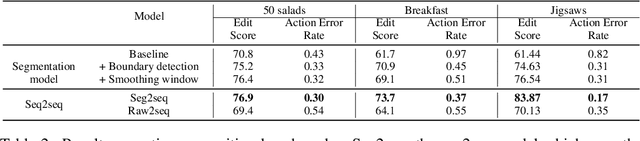
Automatic action identification from video and kinematic data is an important machine learning problem with applications ranging from robotics to smart health. Most existing works focus on identifying coarse actions such as running, climbing, or cutting a vegetable, which have relatively long durations. This is an important limitation for applications that require the identification of subtle motions at high temporal resolution. For example, in stroke recovery, quantifying rehabilitation dose requires differentiating motions with sub-second durations. Our goal is to bridge this gap. To this end, we introduce a large-scale, multimodal dataset, StrokeRehab, as a new action-recognition benchmark that includes subtle short-duration actions labeled at a high temporal resolution. These short-duration actions are called functional primitives, and consist of reaches, transports, repositions, stabilizations, and idles. The dataset consists of high-quality Inertial Measurement Unit sensors and video data of 41 stroke-impaired patients performing activities of daily living like feeding, brushing teeth, etc. We show that current state-of-the-art models based on segmentation produce noisy predictions when applied to these data, which often leads to overcounting of actions. To address this, we propose a novel approach for high-resolution action identification, inspired by speech-recognition techniques, which is based on a sequence-to-sequence model that directly predicts the sequence of actions. This approach outperforms current state-of-the-art methods on the StrokeRehab dataset, as well as on the standard benchmark datasets 50Salads, Breakfast, and Jigsaws.
Emotion Recognition from Speech
Dec 22, 2019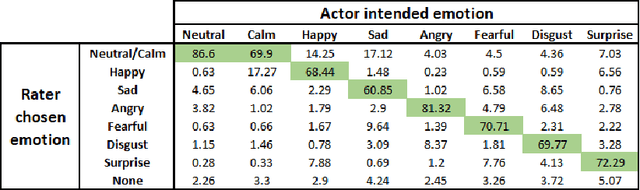
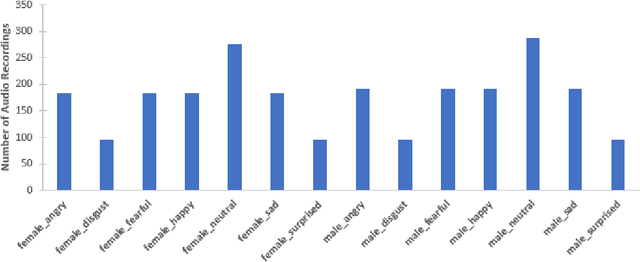
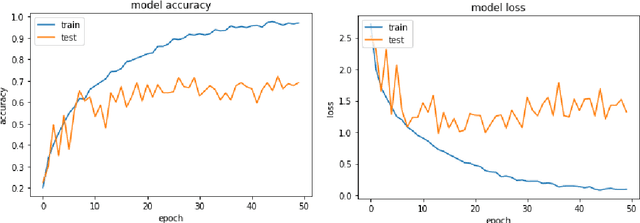
In this work, we conduct an extensive comparison of various approaches to speech based emotion recognition systems. The analyses were carried out on audio recordings from Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS). After pre-processing the raw audio files, features such as Log-Mel Spectrogram, Mel-Frequency Cepstral Coefficients (MFCCs), pitch and energy were considered. The significance of these features for emotion classification was compared by applying methods such as Long Short Term Memory (LSTM), Convolutional Neural Networks (CNNs), Hidden Markov Models (HMMs) and Deep Neural Networks (DNNs). On the 14-class (2 genders x 7 emotions) classification task, an accuracy of 68% was achieved with a 4-layer 2 dimensional CNN using the Log-Mel Spectrogram features. We also observe that, in emotion recognition, the choice of audio features impacts the results much more than the model complexity.