 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrimSeq: a deep learning-based pipeline to quantitate rehabilitation training
Dec 22, 2021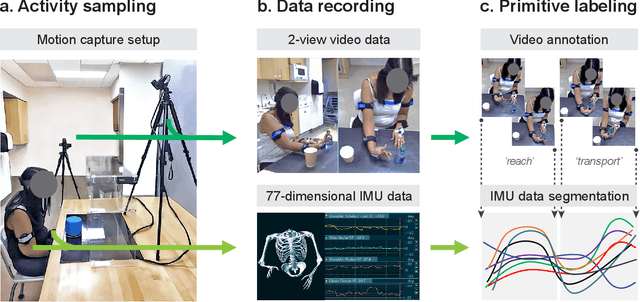
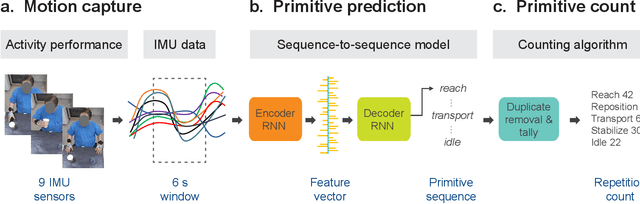
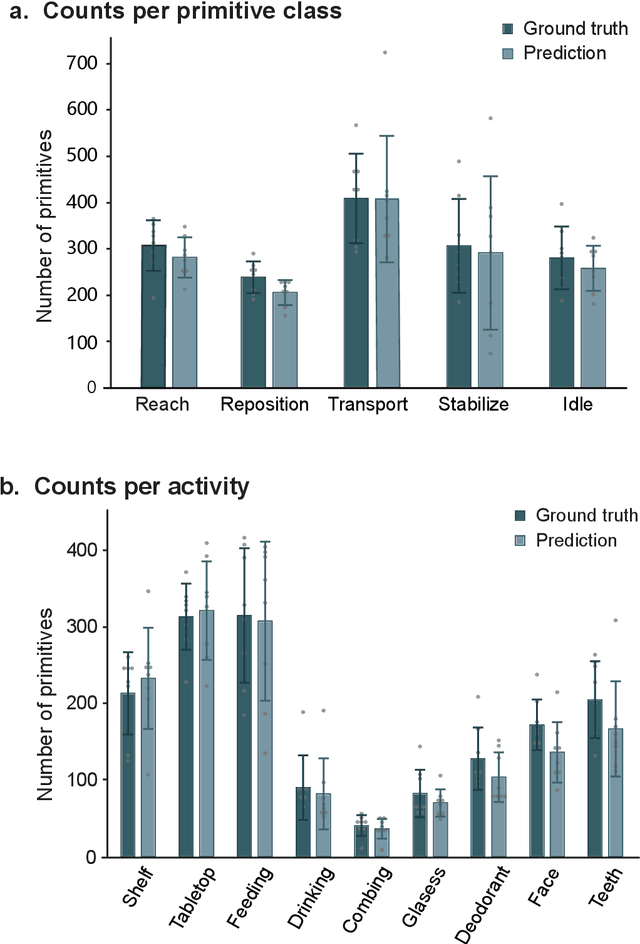
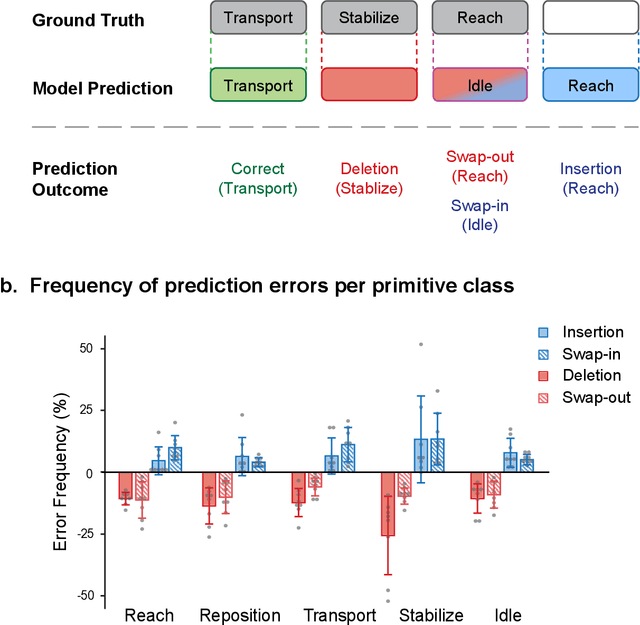
Stroke rehabilitation seeks to increase neuroplasticity through the repeated practice of functional motions, but may have minimal impact on recovery because of insufficient repetitions. The optimal training content and quantity are currently unknown because no practical tools exist to measure them. Here, we present PrimSeq, a pipeline to classify and count functional motions trained in stroke rehabilitation. Our approach integrates wearable sensors to capture upper-body motion, a deep learning model to predict motion sequences, and an algorithm to tally motions. The trained model accurately decomposes rehabilitation activities into component functional motions, outperforming competitive machine learning methods. PrimSeq furthermore quantifies these motions at a fraction of the time and labor costs of human experts. We demonstrate the capabilities of PrimSeq in previously unseen stroke patients with a range of upper extremity motor impairment. We expect that these advances will support the rigorous measurement required for quantitative dosing trials in stroke rehabilitation.
Sequence-to-Sequence Modeling for Action Identification at High Temporal Resolution
Nov 03, 2021

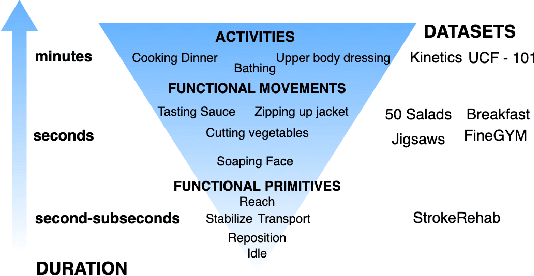
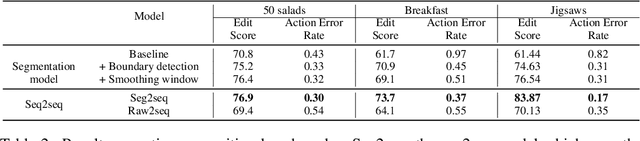
Automatic action identification from video and kinematic data is an important machine learning problem with applications ranging from robotics to smart health. Most existing works focus on identifying coarse actions such as running, climbing, or cutting a vegetable, which have relatively long durations. This is an important limitation for applications that require the identification of subtle motions at high temporal resolution. For example, in stroke recovery, quantifying rehabilitation dose requires differentiating motions with sub-second durations. Our goal is to bridge this gap. To this end, we introduce a large-scale, multimodal dataset, StrokeRehab, as a new action-recognition benchmark that includes subtle short-duration actions labeled at a high temporal resolution. These short-duration actions are called functional primitives, and consist of reaches, transports, repositions, stabilizations, and idles. The dataset consists of high-quality Inertial Measurement Unit sensors and video data of 41 stroke-impaired patients performing activities of daily living like feeding, brushing teeth, etc. We show that current state-of-the-art models based on segmentation produce noisy predictions when applied to these data, which often leads to overcounting of actions. To address this, we propose a novel approach for high-resolution action identification, inspired by speech-recognition techniques, which is based on a sequence-to-sequence model that directly predicts the sequence of actions. This approach outperforms current state-of-the-art methods on the StrokeRehab dataset, as well as on the standard benchmark datasets 50Salads, Breakfast, and Jigsaws.
Emotion Recognition from Speech
Dec 22, 2019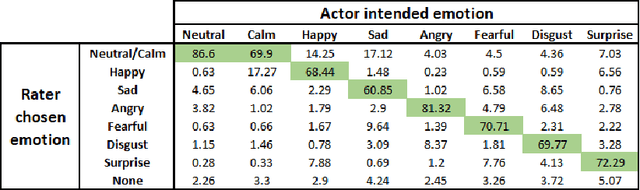
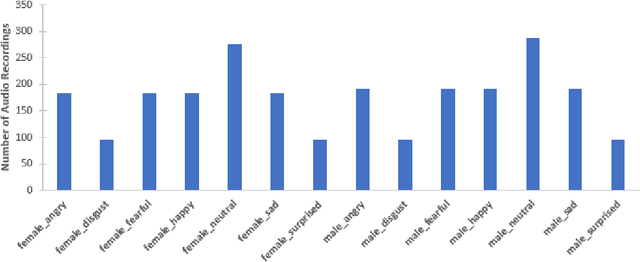
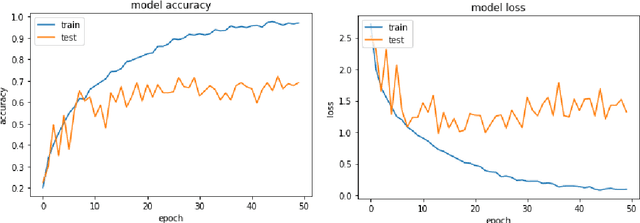
In this work, we conduct an extensive comparison of various approaches to speech based emotion recognition systems. The analyses were carried out on audio recordings from Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS). After pre-processing the raw audio files, features such as Log-Mel Spectrogram, Mel-Frequency Cepstral Coefficients (MFCCs), pitch and energy were considered. The significance of these features for emotion classification was compared by applying methods such as Long Short Term Memory (LSTM), Convolutional Neural Networks (CNNs), Hidden Markov Models (HMMs) and Deep Neural Networks (DNNs). On the 14-class (2 genders x 7 emotions) classification task, an accuracy of 68% was achieved with a 4-layer 2 dimensional CNN using the Log-Mel Spectrogram features. We also observe that, in emotion recognition, the choice of audio features impacts the results much more than the model complexity.