 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable One-Shot Face Video Synthesis With Semantic Aware Prior
Apr 27, 2023The one-shot talking-head synthesis task aims to animate a source image to another pose and expression, which is dictated by a driving frame. Recent methods rely on warping the appearance feature extracted from the source, by using motion fields estimated from the sparse keypoints, that are learned in an unsupervised manner. Due to their lightweight formulation, they are suitable for video conferencing with reduced bandwidth. However, based on our study, current methods suffer from two major limitations: 1) unsatisfactory generation quality in the case of large head poses and the existence of observable pose misalignment between the source and the first frame in driving videos. 2) fail to capture fine yet critical face motion details due to the lack of semantic understanding and appropriate face geometry regularization. To address these shortcomings, we propose a novel method that leverages the rich face prior information, the proposed model can generate face videos with improved semantic consistency (improve baseline by $7\%$ in average keypoint distance) and expression-preserving (outperform baseline by $15 \%$ in average emotion embedding distance) under equivalent bandwidth. Additionally, incorporating such prior information provides us with a convenient interface to achieve highly controllable generation in terms of both pose and expression.
One-Shot Optimal Topology Generation through Theory-Driven Machine Learning
Jul 27, 2018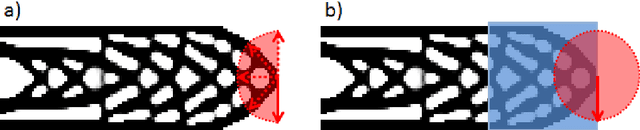

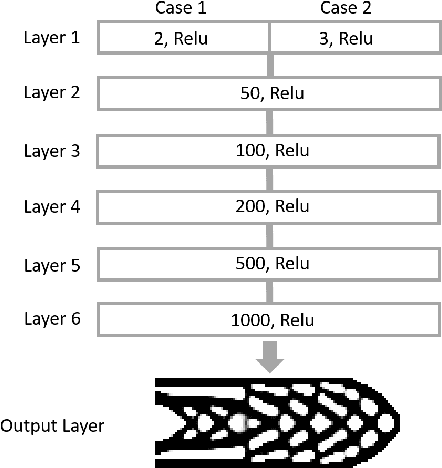
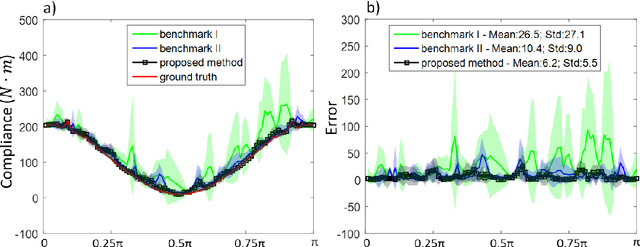
We introduce a theory-driven mechanism for learning a neural network model that performs generative topology design in one shot given a problem setting, circumventing the conventional iterative procedure that computational design tasks usually entail. The proposed mechanism can lead to machines that quickly response to new design requirements based on its knowledge accumulated through past experiences of design generation. Achieving such a mechanism through supervised learning would require an impractically large amount of problem-solution pairs for training, due to the known limitation of deep neural networks in knowledge generalization. To this end, we introduce an interaction between a student (the neural network) and a teacher (the optimality conditions underlying topology optimization): The student learns from existing data and is tested on unseen problems. Deviation of the student's solutions from the optimality conditions is quantified, and used to choose new data points for the student to learn from. We show through a compliance minimization problem that the proposed learning mechanism is significantly more data efficient than using a static dataset under the same computational budget.
Microstructure Representation and Reconstruction of Heterogeneous Materials via Deep Belief Network for Computational Material Design
Apr 28, 2017



Integrated Computational Materials Engineering (ICME) aims to accelerate optimal design of complex material systems by integrating material science and design automation. For tractable ICME, it is required that (1) a structural feature space be identified to allow reconstruction of new designs, and (2) the reconstruction process be property-preserving. The majority of existing structural presentation schemes rely on the designer's understanding of specific material systems to identify geometric and statistical features, which could be biased and insufficient for reconstructing physically meaningful microstructures of complex material systems. In this paper, we develop a feature learning mechanism based on convolutional deep belief network to automate a two-way conversion between microstructures and their lower-dimensional feature representations, and to achieves a 1000-fold dimension reduction from the microstructure space. The proposed model is applied to a wide spectrum of heterogeneous material systems with distinct microstructural features including Ti-6Al-4V alloy, Pb63-Sn37 alloy, Fontainebleau sandstone, and Spherical colloids, to produce material reconstructions that are close to the original samples with respect to 2-point correlation functions and mean critical fracture strength. This capability is not achieved by existing synthesis methods that rely on the Markovian assumption of material microstructures.