 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptSmooth: Certifying Robustness of Medical Vision-Language Models via Prompt Learning
Paper and Code

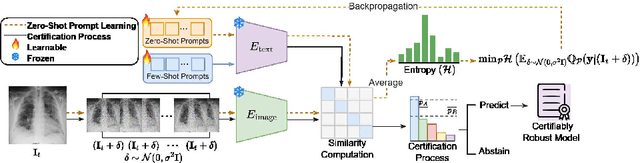
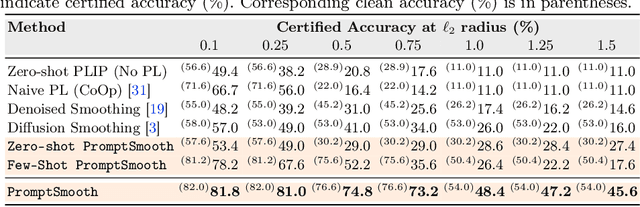
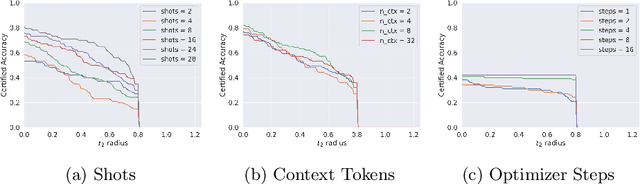
Medical vision-language models (Med-VLMs) trained on large datasets of medical image-text pairs and later fine-tuned for specific tasks have emerged as a mainstream paradigm in medical image analysis. However, recent studies have highlighted the susceptibility of these Med-VLMs to adversarial attacks, raising concerns about their safety and robustness. Randomized smoothing is a well-known technique for turning any classifier into a model that is certifiably robust to adversarial perturbations. However, this approach requires retraining the Med-VLM-based classifier so that it classifies well under Gaussian noise, which is often infeasible in practice. In this paper, we propose a novel framework called PromptSmooth to achieve efficient certified robustness of Med-VLMs by leveraging the concept of prompt learning. Given any pre-trained Med-VLM, PromptSmooth adapts it to handle Gaussian noise by learning textual prompts in a zero-shot or few-shot manner, achieving a delicate balance between accuracy and robustness, while minimizing the computational overhead. Moreover, PromptSmooth requires only a single model to handle multiple noise levels, which substantially reduces the computational cost compared to traditional methods that rely on training a separate model for each noise level. Comprehensive experiments based on three Med-VLMs and across six downstream datasets of various imaging modalities demonstrate the efficacy of PromptSmooth. Our code and models are available at https://github.com/nhussein/promptsmooth.