 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDALLE-URBAN: Capturing the urban design expertise of large text to image transformers
Paper and Code

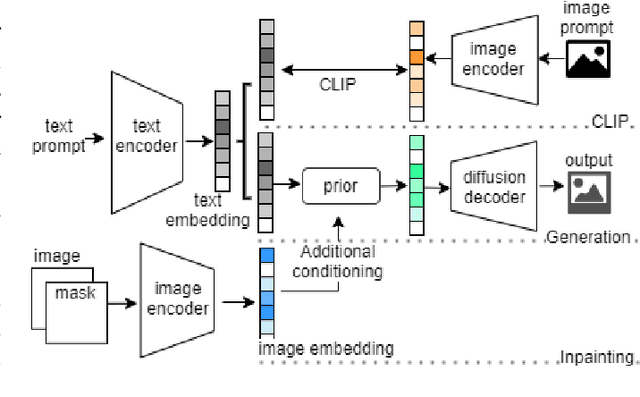

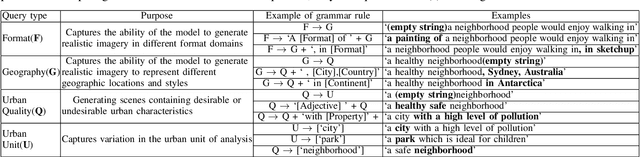
Automatically converting text descriptions into images using transformer architectures has recently received considerable attention. Such advances have implications for many applied design disciplines across fashion, art, architecture, urban planning, landscape design and the future tools available to such disciplines. However, a detailed analysis capturing the capabilities of such models, specifically with a focus on the built environment, has not been performed to date. In this work, we investigate the capabilities and biases of such text-to-image methods as it applies to the built environment in detail. We use a systematic grammar to generate queries related to the built environment and evaluate resulting generated images. We generate 1020 different images and find that text to image transformers are robust at generating realistic images across different domains for this use-case. Generated imagery can be found at the github: https://github.com/sachith500/DALLEURBAN