 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBurst Image Super-Resolution via Multi-Cross Attention Encoding and Multi-Scan State-Space Decoding
May 26, 2025

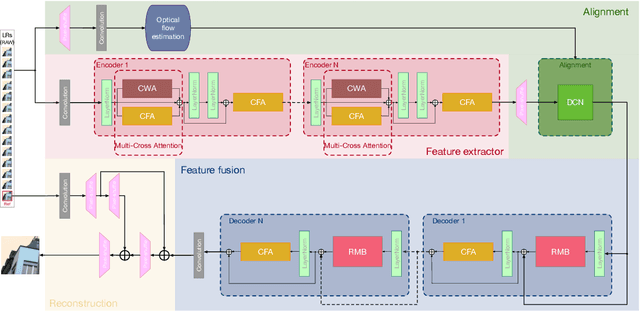
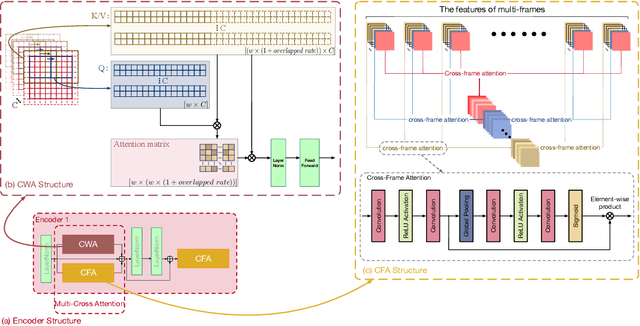
Multi-image super-resolution (MISR) can achieve higher image quality than single-image super-resolution (SISR) by aggregating sub-pixel information from multiple spatially shifted frames. Among MISR tasks, burst super-resolution (BurstSR) has gained significant attention due to its wide range of applications. Recent methods have increasingly adopted Transformers over convolutional neural networks (CNNs) in super-resolution tasks, due to their superior ability to capture both local and global context. However, most existing approaches still rely on fixed and narrow attention windows that restrict the perception of features beyond the local field. This limitation hampers alignment and feature aggregation, both of which are crucial for high-quality super-resolution. To address these limitations, we propose a novel feature extractor that incorporates two newly designed attention mechanisms: overlapping cross-window attention and cross-frame attention, enabling more precise and efficient extraction of sub-pixel information across multiple frames. Furthermore, we introduce a Multi-scan State-Space Module with the cross-frame attention mechanism to enhance feature aggregation. Extensive experiments on both synthetic and real-world benchmarks demonstrate the superiority of our approach. Additional evaluations on ISO 12233 resolution test charts further confirm its enhanced super-resolution performance.
Linear-Covariance Loss for End-to-End Learning of 6D Pose Estimation
Mar 21, 2023Most modern image-based 6D object pose estimation methods learn to predict 2D-3D correspondences, from which the pose can be obtained using a PnP solver. Because of the non-differentiable nature of common PnP solvers, these methods are supervised via the individual correspondences. To address this, several methods have designed differentiable PnP strategies, thus imposing supervision on the pose obtained after the PnP step. Here, we argue that this conflicts with the averaging nature of the PnP problem, leading to gradients that may encourage the network to degrade the accuracy of individual correspondences. To address this, we derive a loss function that exploits the ground truth pose before solving the PnP problem. Specifically, we linearize the PnP solver around the ground-truth pose and compute the covariance of the resulting pose distribution. We then define our loss based on the diagonal covariance elements, which entails considering the final pose estimate yet not suffering from the PnP averaging issue. Our experiments show that our loss consistently improves the pose estimation accuracy for both dense and sparse correspondence based methods, achieving state-of-the-art results on both Linemod-Occluded and YCB-Video.