 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Talker Identity Aids With Improving Speech Recognition in Adversarial Environments
Oct 07, 2024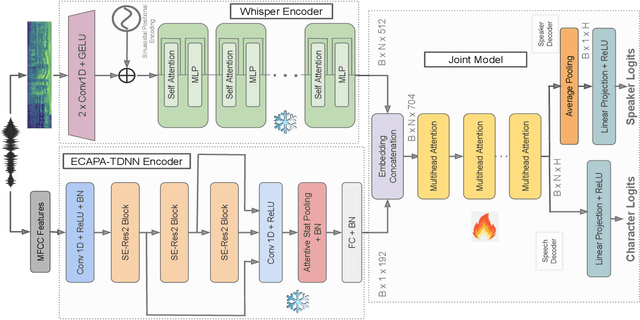
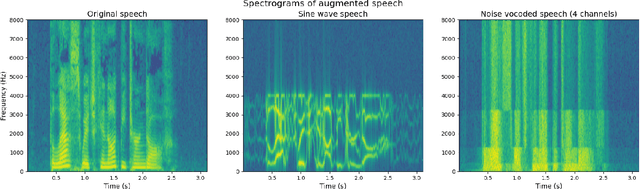
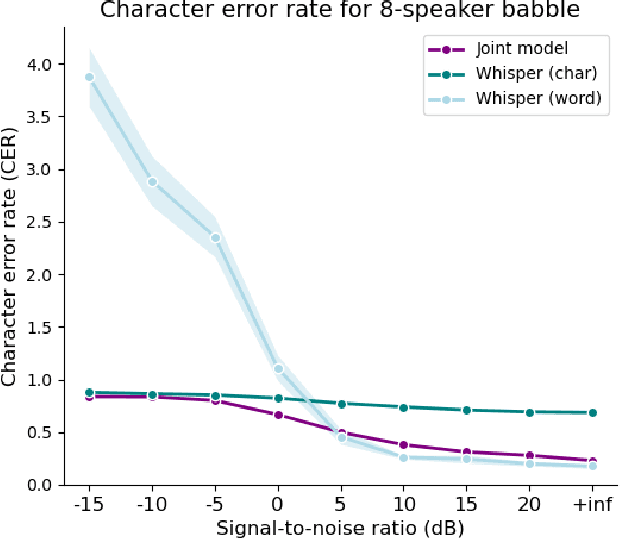
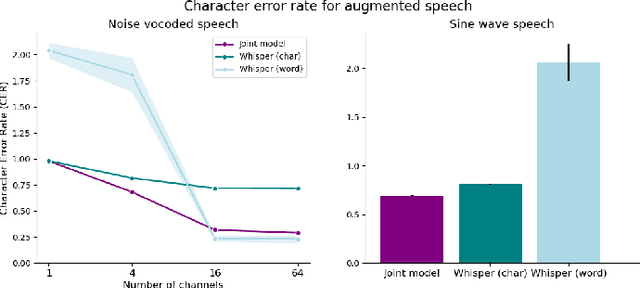
Current state-of-the-art speech recognition models are trained to map acoustic signals into sub-lexical units. While these models demonstrate superior performance, they remain vulnerable to out-of-distribution conditions such as background noise and speech augmentations. In this work, we hypothesize that incorporating speaker representations during speech recognition can enhance model robustness to noise. We developed a transformer-based model that jointly performs speech recognition and speaker identification. Our model utilizes speech embeddings from Whisper and speaker embeddings from ECAPA-TDNN, which are processed jointly to perform both tasks. We show that the joint model performs comparably to Whisper under clean conditions. Notably, the joint model outperforms Whisper in high-noise environments, such as with 8-speaker babble background noise. Furthermore, our joint model excels in handling highly augmented speech, including sine-wave and noise-vocoded speech. Overall, these results suggest that integrating voice representations with speech recognition can lead to more robust models under adversarial conditions.