 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJailbreak Scaling Laws for Large Language Models: Polynomial-Exponential Crossover
Mar 11, 2026Adversarial attacks can reliably steer safety-aligned large language models toward unsafe behavior. Empirically, we find that adversarial prompt-injection attacks can amplify attack success rate from the slow polynomial growth observed without injection to exponential growth with the number of inference-time samples. To explain this phenomenon, we propose a theoretical generative model of proxy language in terms of a spin-glass system operating in a replica-symmetry-breaking regime, where generations are drawn from the associated Gibbs measure and a subset of low-energy, size-biased clusters is designated unsafe. Within this framework, we analyze prompt injection-based jailbreaking. Short injected prompts correspond to a weak magnetic field aligned towards unsafe cluster centers and yield a power-law scaling of attack success rate with the number of inference-time samples, while long injected prompts, i.e., strong magnetic field, yield exponential scaling. We derive these behaviors analytically and confirm them empirically on large language models. This transition between two regimes is due to the appearance of an ordered phase in the spin chain under a strong magnetic field, which suggests that the injected jailbreak prompt enhances adversarial order in the language model.
Incorporating Talker Identity Aids With Improving Speech Recognition in Adversarial Environments
Oct 07, 2024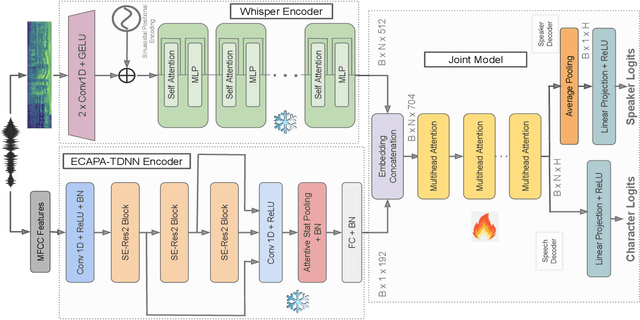
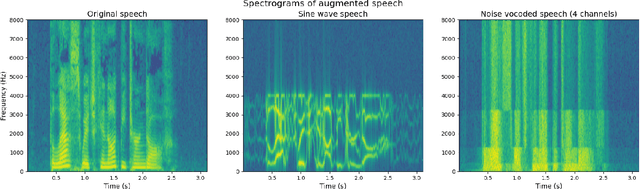
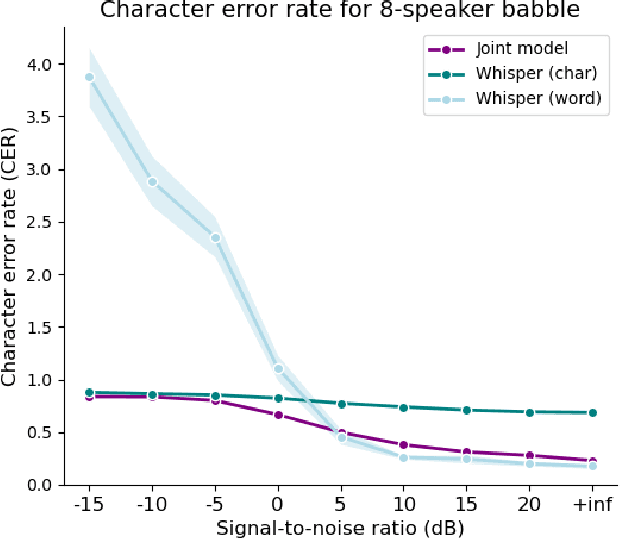
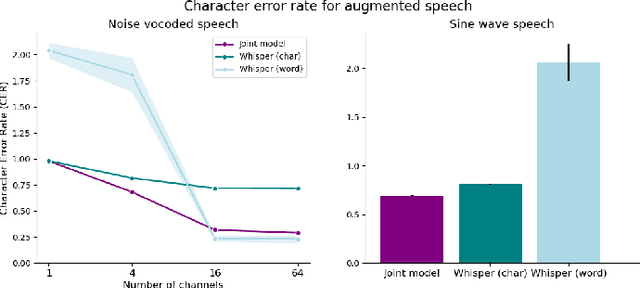
Current state-of-the-art speech recognition models are trained to map acoustic signals into sub-lexical units. While these models demonstrate superior performance, they remain vulnerable to out-of-distribution conditions such as background noise and speech augmentations. In this work, we hypothesize that incorporating speaker representations during speech recognition can enhance model robustness to noise. We developed a transformer-based model that jointly performs speech recognition and speaker identification. Our model utilizes speech embeddings from Whisper and speaker embeddings from ECAPA-TDNN, which are processed jointly to perform both tasks. We show that the joint model performs comparably to Whisper under clean conditions. Notably, the joint model outperforms Whisper in high-noise environments, such as with 8-speaker babble background noise. Furthermore, our joint model excels in handling highly augmented speech, including sine-wave and noise-vocoded speech. Overall, these results suggest that integrating voice representations with speech recognition can lead to more robust models under adversarial conditions.
An Implantable Piezofilm Middle Ear Microphone: Performance in Human Cadaveric Temporal Bones
Dec 22, 2023Purpose: One of the major reasons that totally implantable cochlear microphones are not readily available is the lack of good implantable microphones. An implantable microphone has the potential to provide a range of benefits over external microphones for cochlear implant users including the filtering ability of the outer ear, cosmetics, and usability in all situations. This paper presents results from experiments in human cadaveric ears of a piezofilm microphone concept under development as a possible component of a future implantable microphone system for use with cochlear implants. This microphone is referred to here as a drum microphone (DrumMic) that senses the robust and predictable motion of the umbo, the tip of the malleus. Methods: The performance was measured of five DrumMics inserted in four different human cadaveric temporal bones. Sensitivity, linearity, bandwidth, and equivalent input noise were measured during these experiments using a sound stimulus and measurement setup. Results: The sensitivity of the DrumMics was found to be tightly clustered across different microphones and ears despite differences in umbo and middle ear anatomy. The DrumMics were shown to behave linearly across a large dynamic range (46 dB SPL to 100 dB SPL) across a wide bandwidth (100 Hz to 8 kHz). The equivalent input noise (0.1-10 kHz) of the DrumMic and amplifier referenced to the ear canal was measured to be 54 dB SPL and estimated to be 46 dB SPL after accounting for the pressure gain of the outer ear. Conclusion: The results demonstrate that the DrumMic behaves robustly across ears and fabrication. The equivalent input noise performance was shown to approach that of commercial hearing aid microphones. To advance this demonstration of the DrumMic concept to a future prototype implantable in humans, work on encapsulation, biocompatibility, connectorization will be required.
A Residual Network based Deep Learning Model for Detection of COVID-19 from Cough Sounds
Jun 04, 2021


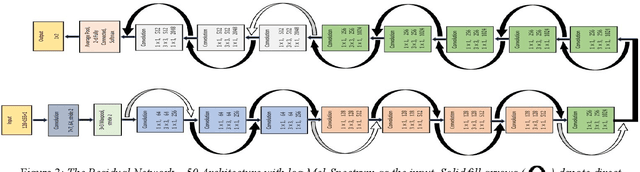
The present work proposes a deep-learning-based approach for the classification of COVID-19 coughs from non-COVID-19 coughs and that can be used as a low-resource-based tool for early detection of the onset of such respiratory diseases. The proposed system uses the ResNet-50 architecture, a popularly known Convolutional Neural Network (CNN) for image recognition tasks, fed with the log-Mel spectrums of the audio data to discriminate between the two types of coughs. For the training and validation of the proposed deep learning model, this work utilizes the Track-1 dataset provided by the DiCOVA Challenge 2021 organizers. Additionally, to increase the number of COVID-positive samples and to enhance variability in the training data, it has also utilized a large open-source database of COVID-19 coughs collected by the EPFL CoughVid team. Our developed model has achieved an average validation AUC of 98.88%. Also, applying this model on the Blind Test Set released by the DiCOVA Challenge, the system has achieved a Test AUC of 75.91%, Test Specificity of 62.50%, and Test Sensitivity of 80.49%. Consequently, this submission has secured 16th position in the DiCOVA Challenge 2021 leader-board.