 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Unlearning: Solutions and Challenges
Paper and Code
Aug 14, 2023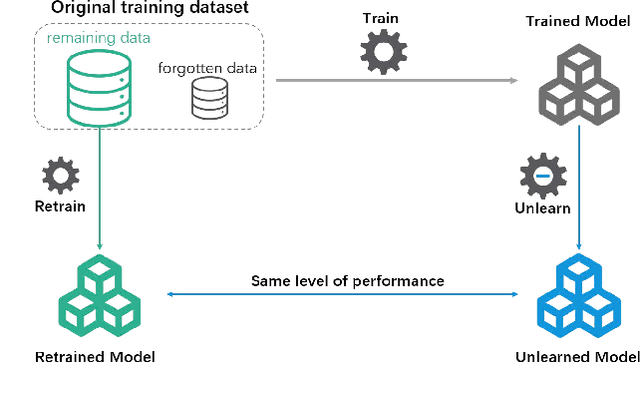
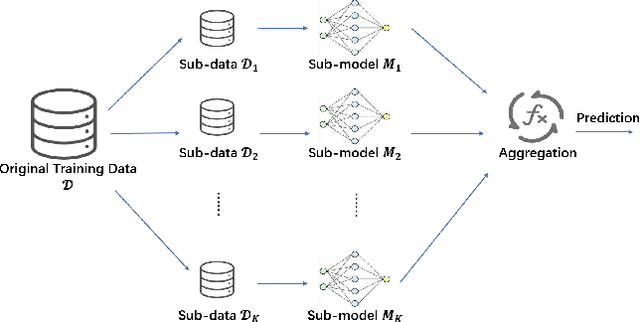
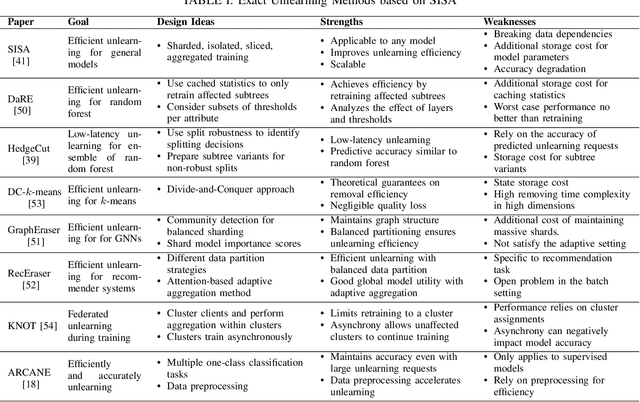
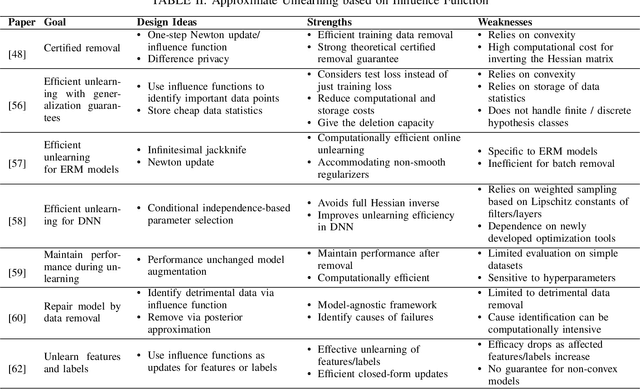
Machine learning models may inadvertently memorize sensitive, unauthorized, or malicious data, posing risks of privacy violations, security breaches, and performance deterioration. To address these issues, machine unlearning has emerged as a critical technique to selectively remove specific training data points' influence on trained models. This paper provides a comprehensive taxonomy and analysis of machine unlearning research. We categorize existing research into exact unlearning that algorithmically removes data influence entirely and approximate unlearning that efficiently minimizes influence through limited parameter updates. By reviewing the state-of-the-art solutions, we critically discuss their advantages and limitations. Furthermore, we propose future directions to advance machine unlearning and establish it as an essential capability for trustworthy and adaptive machine learning. This paper provides researchers with a roadmap of open problems, encouraging impactful contributions to address real-world needs for selective data removal.