 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Optimal Tree Models Under Beam Search
Paper and Code
Jun 27, 2020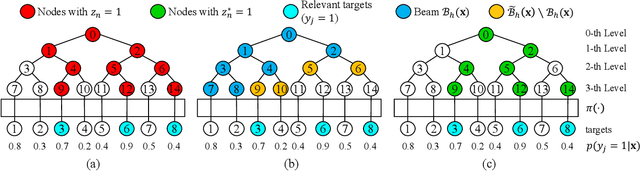
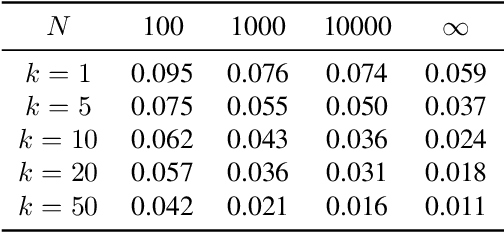
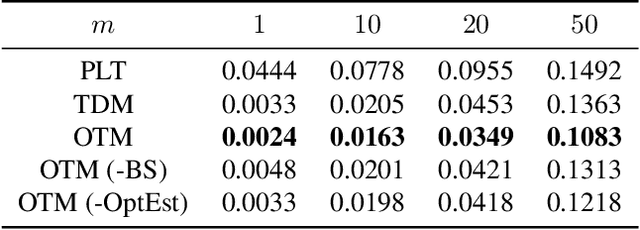
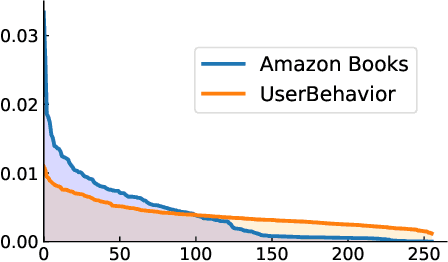
Retrieving relevant targets from an extremely large target set under computational limits is a common challenge for information retrieval and recommendation systems. Tree models, which formulate targets as leaves of a tree with trainable node-wise scorers, have attracted a lot of interests in tackling this challenge due to their logarithmic computational complexity in both training and testing. Tree-based deep models (TDMs) and probabilistic label trees (PLTs) are two representative kinds of them. Though achieving many practical successes, existing tree models suffer from the training-testing discrepancy, where the retrieval performance deterioration caused by beam search in testing is not considered in training. This leads to an intrinsic gap between the most relevant targets and those retrieved by beam search with even the optimally trained node-wise scorers. We take a first step towards understanding and analyzing this problem theoretically, and develop the concept of Bayes optimality under beam search and calibration under beam search as general analyzing tools for this purpose. Moreover, to eliminate the discrepancy, we propose a novel algorithm for learning optimal tree models under beam search. Experiments on both synthetic and real data verify the rationality of our theoretical analysis and demonstrate the superiority of our algorithm compared to state-of-the-art methods.