 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSampling-Efficient Test-Time Scaling: Self-Estimating the Best-of-N Sampling in Early Decoding
Paper and Code
Mar 03, 2025

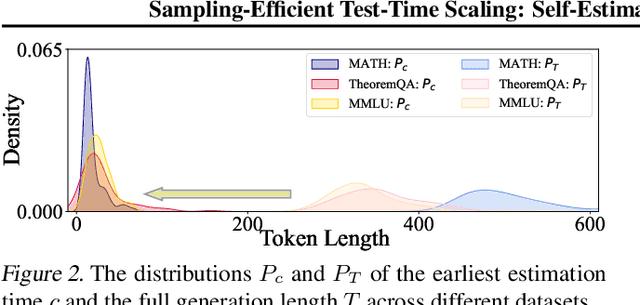

Test-time scaling improves large language model performance by adding extra compute during decoding. Best-of-N (BoN) sampling serves as a common scaling technique, broadening the search space for finding better solutions from the model distribution. However, traditional BoN requires N full generations, leading to high GPU memory overhead and time latency. Moreover, some methods depend on reward models, adding computational cost and limiting domain generalization. In this paper, we propose Self-Truncation Best-of-N (ST-BoN), a novel decoding method that avoids fully generating all samplings and eliminates the need for reward models. ST-BoN introduces early sampling consistency to estimate the most promising sample, truncating suboptimal ones to free memory and accelerate inference. This pushes the sampling-efficient test-time scaling. Compared to traditional BoN, ST-BoN can reduce dynamic GPU memory overhead by over 90% and time latency by 50%, while achieving comparable or even better performance across reasoning and open-ended domains.