 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Space Chain-of-Embedding Enables Output-free LLM Self-Evaluation
Paper and Code
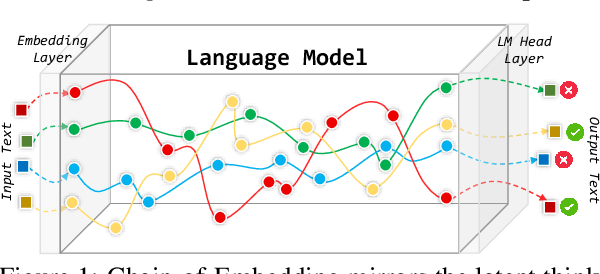
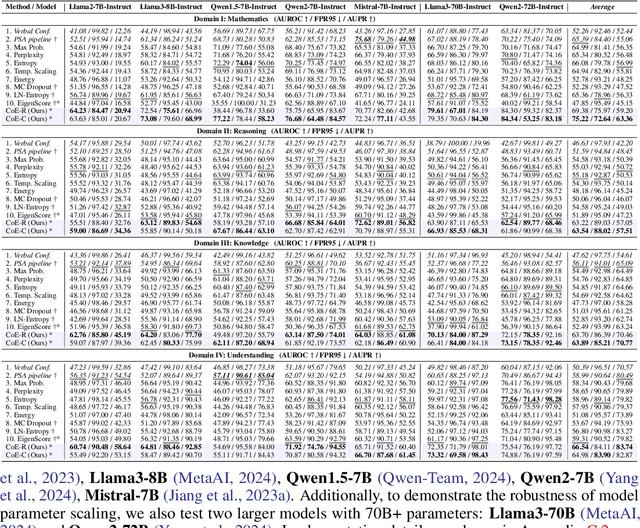
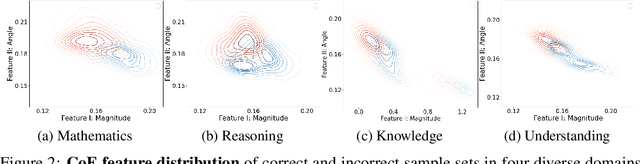
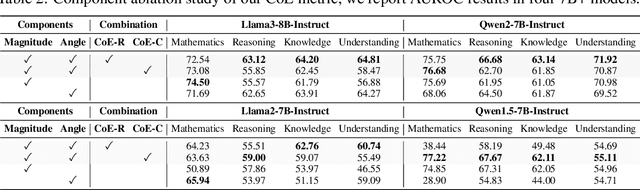
LLM self-evaluation relies on the LLM's own ability to estimate response correctness, which can greatly improve its deployment reliability. In this research track, we propose the Chain-of-Embedding (CoE) in the latent space to enable LLMs to perform output-free self-evaluation. CoE consists of all progressive hidden states produced during the inference time, which can be treated as the latent thinking path of LLMs. We find that when LLMs respond correctly and incorrectly, their CoE features differ, these discrepancies assist us in estimating LLM response correctness. Experiments in four diverse domains and seven LLMs fully demonstrate the effectiveness of our method. Meanwhile, its label-free design intent without any training and millisecond-level computational cost ensure real-time feedback in large-scale scenarios. More importantly, we provide interesting insights into LLM response correctness from the perspective of hidden state changes inside LLMs.