 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-Training Embedding Alignment for Decoupling Enrollment and Runtime Speaker Recognition Models
Jan 23, 2024

Automated speaker identification (SID) is a crucial step for the personalization of a wide range of speech-enabled services. Typical SID systems use a symmetric enrollment-verification framework with a single model to derive embeddings both offline for voice profiles extracted from enrollment utterances, and online from runtime utterances. Due to the distinct circumstances of enrollment and runtime, such as different computation and latency constraints, several applications would benefit from an asymmetric enrollment-verification framework that uses different models for enrollment and runtime embedding generation. To support this asymmetric SID where each of the two models can be updated independently, we propose using a lightweight neural network to map the embeddings from the two independent models to a shared speaker embedding space. Our results show that this approach significantly outperforms cosine scoring in a shared speaker logit space for models that were trained with a contrastive loss on large datasets with many speaker identities. This proposed Neural Embedding Speaker Space Alignment (NESSA) combined with an asymmetric update of only one of the models delivers at least 60% of the performance gain achieved by updating both models in the standard symmetric SID approach.
Tackling the Score Shift in Cross-Lingual Speaker Verification by Exploiting Language Information
Oct 18, 2021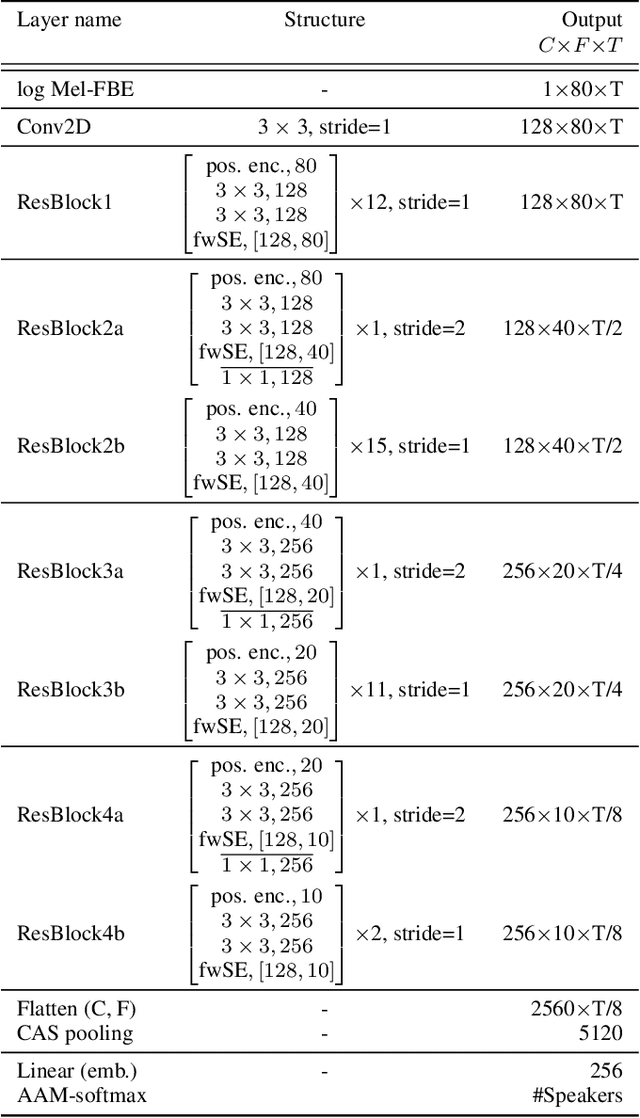
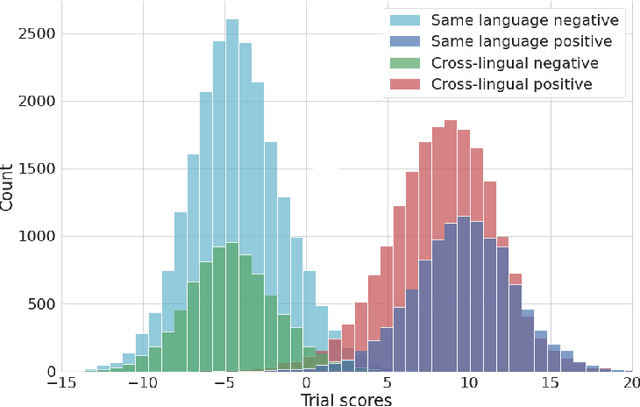
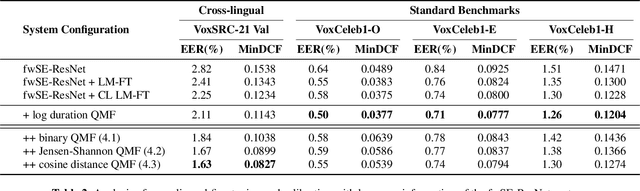
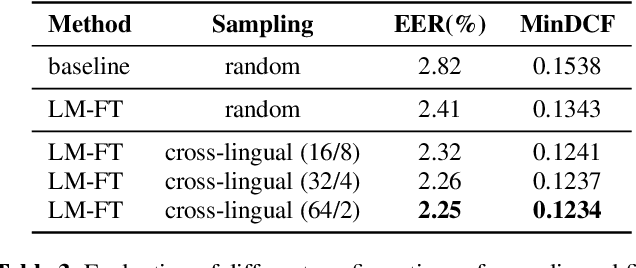
This paper contains a post-challenge performance analysis on cross-lingual speaker verification of the IDLab submission to the VoxCeleb Speaker Recognition Challenge 2021 (VoxSRC-21). We show that current speaker embedding extractors consistently underestimate speaker similarity in within-speaker cross-lingual trials. Consequently, the typical training and scoring protocols do not put enough emphasis on the compensation of intra-speaker language variability. We propose two techniques to increase cross-lingual speaker verification robustness. First, we enhance our previously proposed Large-Margin Fine-Tuning (LM-FT) training stage with a mini-batch sampling strategy which increases the amount of intra-speaker cross-lingual samples within the mini-batch. Second, we incorporate language information in the logistic regression calibration stage. We integrate quality metrics based on soft and hard decisions of a VoxLingua107 language identification model. The proposed techniques result in a 11.7% relative improvement over the baseline model on the VoxSRC-21 test set and contributed to our third place finish in the corresponding challenge.
The IDLAB VoxCeleb Speaker Recognition Challenge 2021 System Description
Sep 09, 2021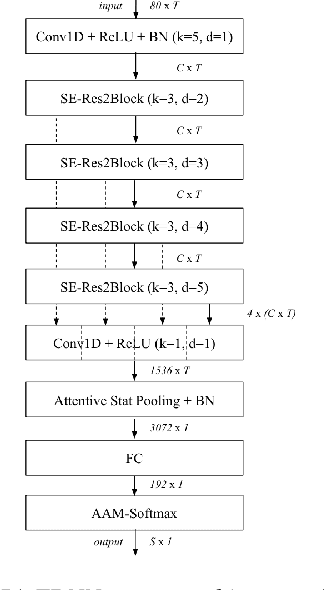
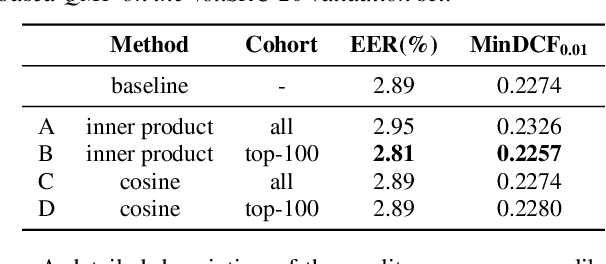
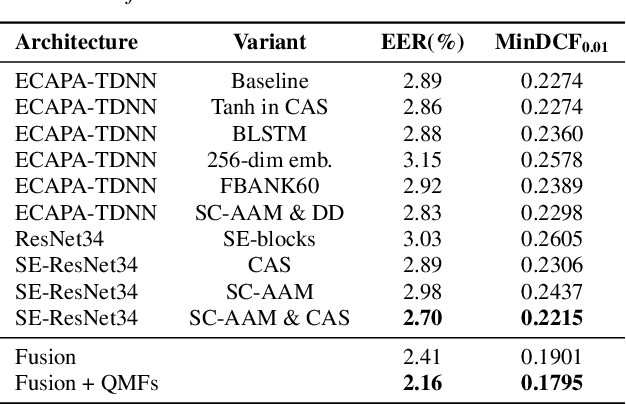
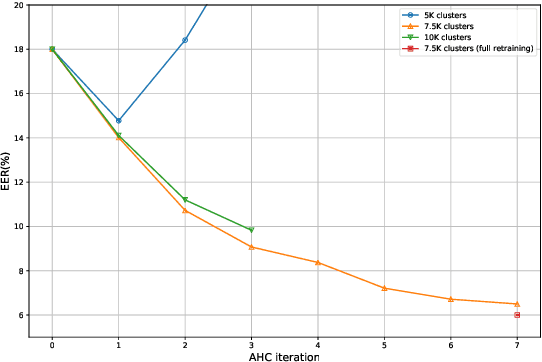
This technical report describes the IDLab submission for track 1 and 2 of the VoxCeleb Speaker Recognition Challenge 2021 (VoxSRC-21). This speaker verification competition focuses on short duration test recordings and cross-lingual trials. Currently, both Time Delay Neural Networks (TDNNs) and ResNets achieve state-of-the-art results in speaker verification. We opt to use a system fusion of hybrid architectures in our final submission. An ECAPA-TDNN baseline is enhanced with a 2D convolutional stem to transfer some of the strong characteristics of a ResNet based model to this hybrid CNN-TDNN architecture. Similarly, we incorporate absolute frequency positional information in the SE-ResNet architectures. All models are trained with a special mini-batch data sampling technique which constructs mini-batches with data that is the most challenging for the system on the level of intra-speaker variability. This intra-speaker variability is mainly caused by differences in language and background conditions between the speaker's utterances. The cross-lingual effects on the speaker verification scores are further compensated by introducing a binary cross-linguality trial feature in the logistic regression based system calibration. The final system fusion with two ECAPA CNN-TDNNs and three SE-ResNets enhanced with frequency positional information achieved a third place on the VoxSRC-21 leaderboard for both track 1 and 2 with a minDCF of 0.1291 and 0.1313 respectively.
Robust Acoustic Scene Classification in the Presence of Active Foreground Speech
Aug 02, 2021


We present an iVector based Acoustic Scene Classification (ASC) system suited for real life settings where active foreground speech can be present. In the proposed system, each recording is represented by a fixed-length iVector that models the recording's important properties. A regularized Gaussian backend classifier with class-specific covariance models is used to extract the relevant acoustic scene information from these iVectors. To alleviate the large performance degradation when a foreground speaker dominates the captured signal, we investigate the use of the iVector framework on Mel-Frequency Cepstral Coefficients (MFCCs) that are derived from an estimate of the noise power spectral density. This noise-floor can be extracted in a statistical manner for single channel recordings. We show that the use of noise-floor features is complementary to multi-condition training in which foreground speech is added to training signal to reduce the mismatch between training and testing conditions. Experimental results on the DCASE 2016 Task 1 dataset show that the noise-floor based features and multi-condition training realize significant classification accuracy gains of up to more than 25 percentage points (absolute) in the most adverse conditions. These promising results can further facilitate the integration of ASC in resource-constrained devices such as hearables.
Integrating Frequency Translational Invariance in TDNNs and Frequency Positional Information in 2D ResNets to Enhance Speaker Verification
Apr 06, 2021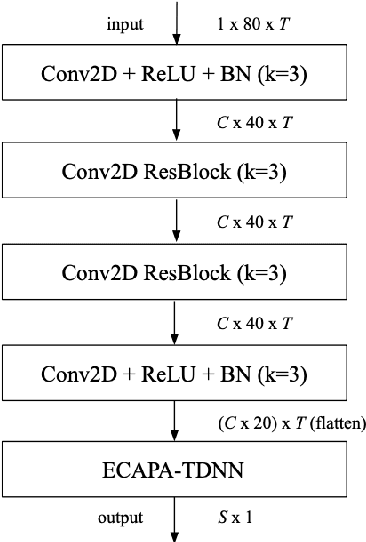
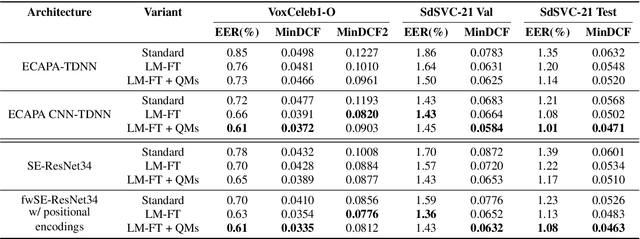

This paper describes the IDLab submission for the text-independent task of the Short-duration Speaker Verification Challenge 2021 (SdSVC-21). This speaker verification competition focuses on short duration test recordings and cross-lingual trials, along with the constraint of limited availability of in-domain DeepMine Farsi training data. Currently, both Time Delay Neural Networks (TDNNs) and ResNets achieve state-of-the-art results in speaker verification. These architectures are structurally very different and the construction of hybrid networks looks a promising way forward. We introduce a 2D convolutional stem in a strong ECAPA-TDNN baseline to transfer some of the strong characteristics of a ResNet based model to this hybrid CNN-TDNN architecture. Similarly, we incorporate absolute frequency positional encodings in an SE-ResNet34 architecture. These learnable feature map biases along the frequency axis offer this architecture a straightforward way to exploit frequency positional information. We also propose a frequency-wise variant of Squeeze-Excitation (SE) which better preserves frequency-specific information when rescaling the feature maps. Both modified architectures significantly outperform their corresponding baseline on the SdSVC-21 evaluation data and the original VoxCeleb1 test set. A four system fusion containing the two improved architectures achieved a third place in the final SdSVC-21 Task 2 ranking.
ECAPA-TDNN Embeddings for Speaker Diarization
Apr 03, 2021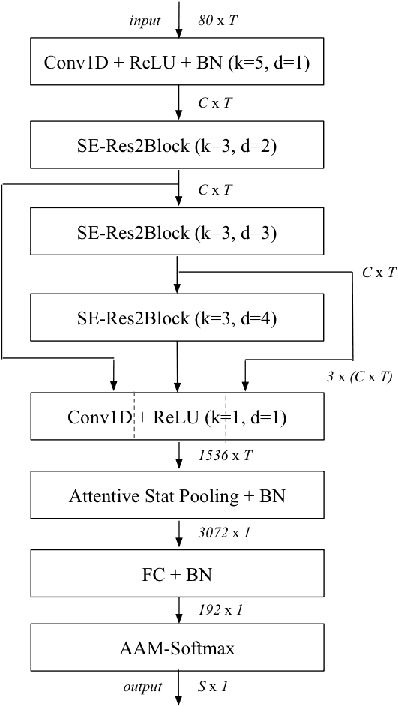
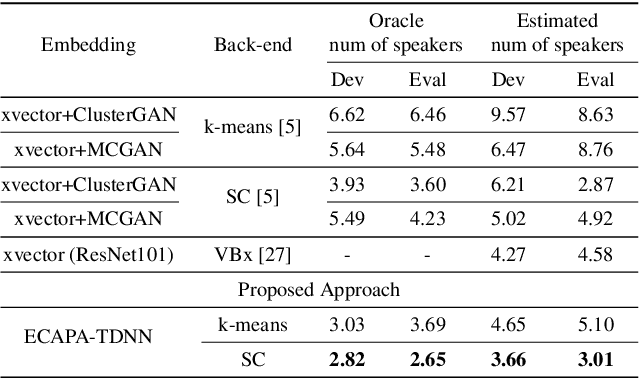
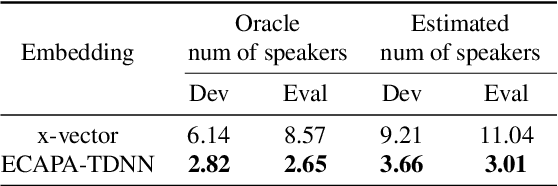
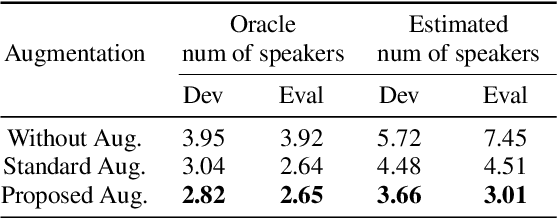
Learning robust speaker embeddings is a crucial step in speaker diarization. Deep neural networks can accurately capture speaker discriminative characteristics and popular deep embeddings such as x-vectors are nowadays a fundamental component of modern diarization systems. Recently, some improvements over the standard TDNN architecture used for x-vectors have been proposed. The ECAPA-TDNN model, for instance, has shown impressive performance in the speaker verification domain, thanks to a carefully designed neural model. In this work, we extend, for the first time, the use of the ECAPA-TDNN model to speaker diarization. Moreover, we improved its robustness with a powerful augmentation scheme that concatenates several contaminated versions of the same signal within the same training batch. The ECAPA-TDNN model turned out to provide robust speaker embeddings under both close-talking and distant-talking conditions. Our results on the popular AMI meeting corpus show that our system significantly outperforms recently proposed approaches.
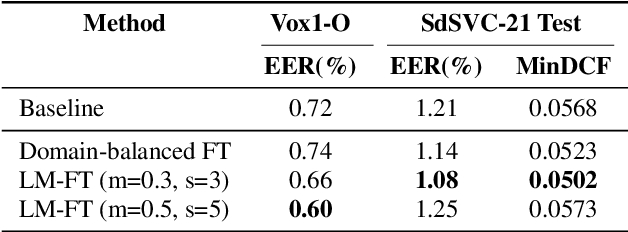
Cross-Lingual Speaker Verification with Domain-Balanced Hard Prototype Mining and Language-Dependent Score Normalization
Aug 10, 2020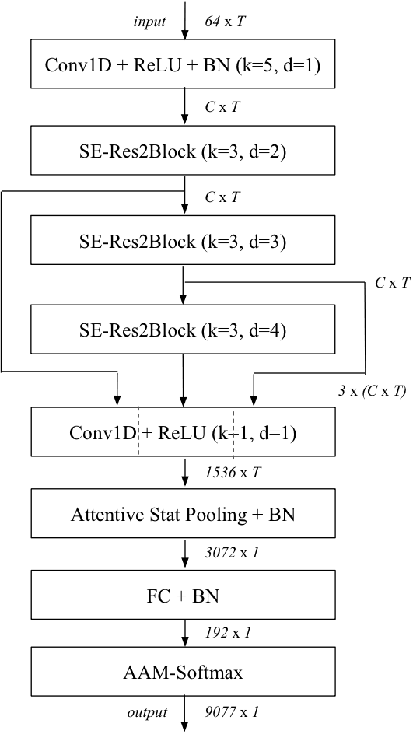
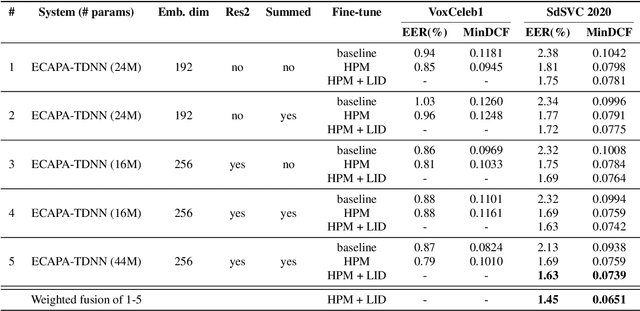
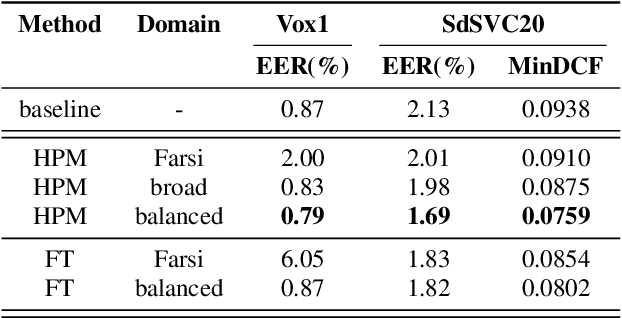
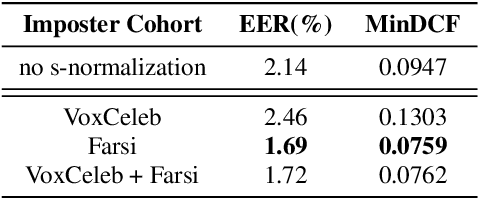
In this paper we describe the top-scoring IDLab submission for the text-independent task of the Short-duration Speaker Verification (SdSV) Challenge 2020. The main difficulty of the challenge exists in the large degree of varying phonetic overlap between the potentially cross-lingual trials, along with the limited availability of in-domain DeepMine Farsi training data. We introduce domain-balanced hard prototype mining to fine-tune the state-of-the-art ECAPA-TDNN x-vector based speaker embedding extractor. The sample mining technique efficiently exploits speaker distances between the speaker prototypes of the popular AAM-softmax loss function to construct challenging training batches that are balanced on the domain-level. To enhance the scoring of cross-lingual trials, we propose a language-dependent s-norm score normalization. The imposter cohort only contains data from the Farsi target-domain which simulates the enrollment data always being Farsi. In case a Gaussian-Backend language model detects the test speaker embedding to contain English, a cross-language compensation offset determined on the AAM-softmax speaker prototypes is subtracted from the maximum expected imposter mean score. A fusion of five systems with minor topological tweaks resulted in a final MinDCF and EER of 0.065 and 1.45% respectively on the SdSVC evaluation set.