 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Lingual Speaker Verification with Domain-Balanced Hard Prototype Mining and Language-Dependent Score Normalization
Paper and Code
Aug 10, 2020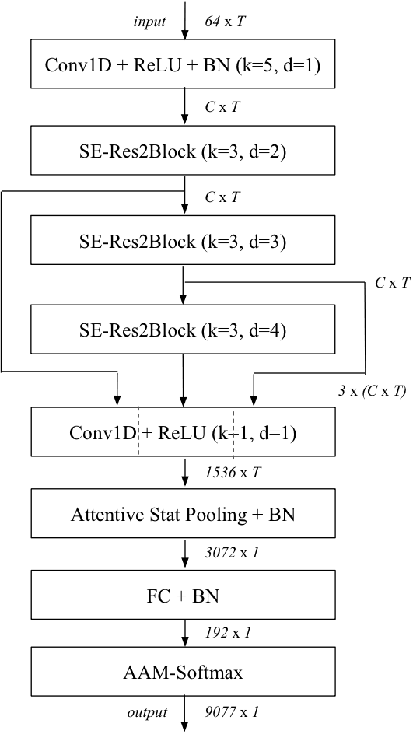
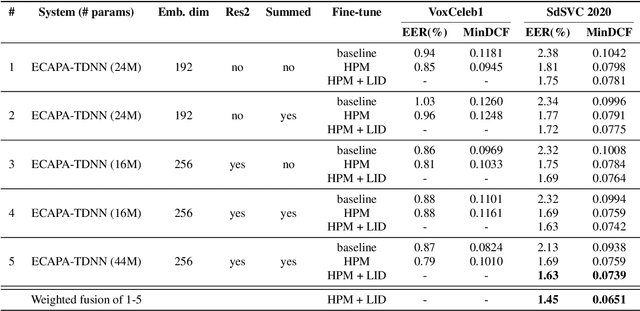
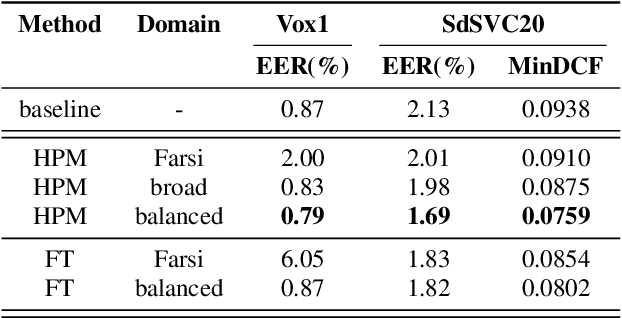
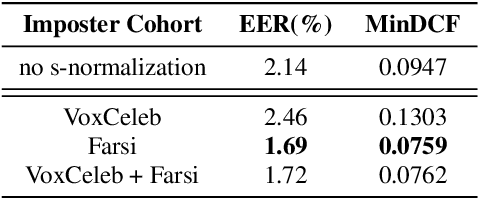
In this paper we describe the top-scoring IDLab submission for the text-independent task of the Short-duration Speaker Verification (SdSV) Challenge 2020. The main difficulty of the challenge exists in the large degree of varying phonetic overlap between the potentially cross-lingual trials, along with the limited availability of in-domain DeepMine Farsi training data. We introduce domain-balanced hard prototype mining to fine-tune the state-of-the-art ECAPA-TDNN x-vector based speaker embedding extractor. The sample mining technique efficiently exploits speaker distances between the speaker prototypes of the popular AAM-softmax loss function to construct challenging training batches that are balanced on the domain-level. To enhance the scoring of cross-lingual trials, we propose a language-dependent s-norm score normalization. The imposter cohort only contains data from the Farsi target-domain which simulates the enrollment data always being Farsi. In case a Gaussian-Backend language model detects the test speaker embedding to contain English, a cross-language compensation offset determined on the AAM-softmax speaker prototypes is subtracted from the maximum expected imposter mean score. A fusion of five systems with minor topological tweaks resulted in a final MinDCF and EER of 0.065 and 1.45% respectively on the SdSVC evaluation set.