 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Frequency Translational Invariance in TDNNs and Frequency Positional Information in 2D ResNets to Enhance Speaker Verification
Paper and Code
Apr 06, 2021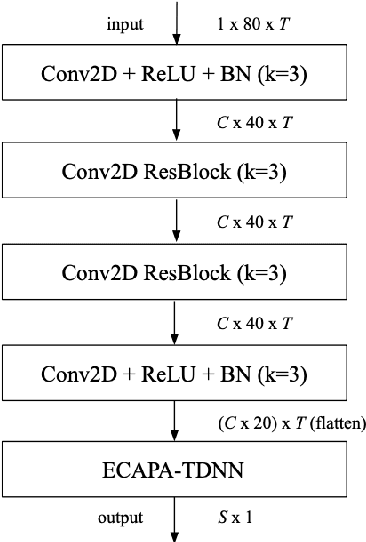
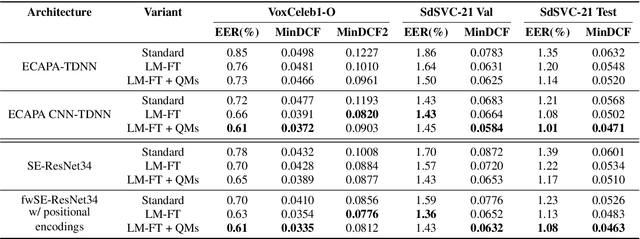
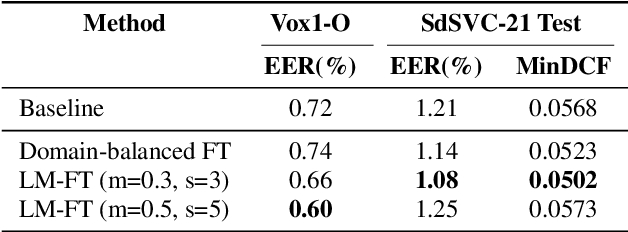

This paper describes the IDLab submission for the text-independent task of the Short-duration Speaker Verification Challenge 2021 (SdSVC-21). This speaker verification competition focuses on short duration test recordings and cross-lingual trials, along with the constraint of limited availability of in-domain DeepMine Farsi training data. Currently, both Time Delay Neural Networks (TDNNs) and ResNets achieve state-of-the-art results in speaker verification. These architectures are structurally very different and the construction of hybrid networks looks a promising way forward. We introduce a 2D convolutional stem in a strong ECAPA-TDNN baseline to transfer some of the strong characteristics of a ResNet based model to this hybrid CNN-TDNN architecture. Similarly, we incorporate absolute frequency positional encodings in an SE-ResNet34 architecture. These learnable feature map biases along the frequency axis offer this architecture a straightforward way to exploit frequency positional information. We also propose a frequency-wise variant of Squeeze-Excitation (SE) which better preserves frequency-specific information when rescaling the feature maps. Both modified architectures significantly outperform their corresponding baseline on the SdSVC-21 evaluation data and the original VoxCeleb1 test set. A four system fusion containing the two improved architectures achieved a third place in the final SdSVC-21 Task 2 ranking.